(转载)排序二 快速排序
Posted 王小东大将军
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了(转载)排序二 快速排序相关的知识,希望对你有一定的参考价值。
要点
快速排序是一种交换排序。
快速排序由C. A. R. Hoare在1962年提出。
它的基本思想是:通过一趟排序将要排序的数据分割成独立的两部分:分割点左边都是比它小的数,右边都是比它大的数。
然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
详细的图解往往比大堆的文字更有说明力,所以直接上图:
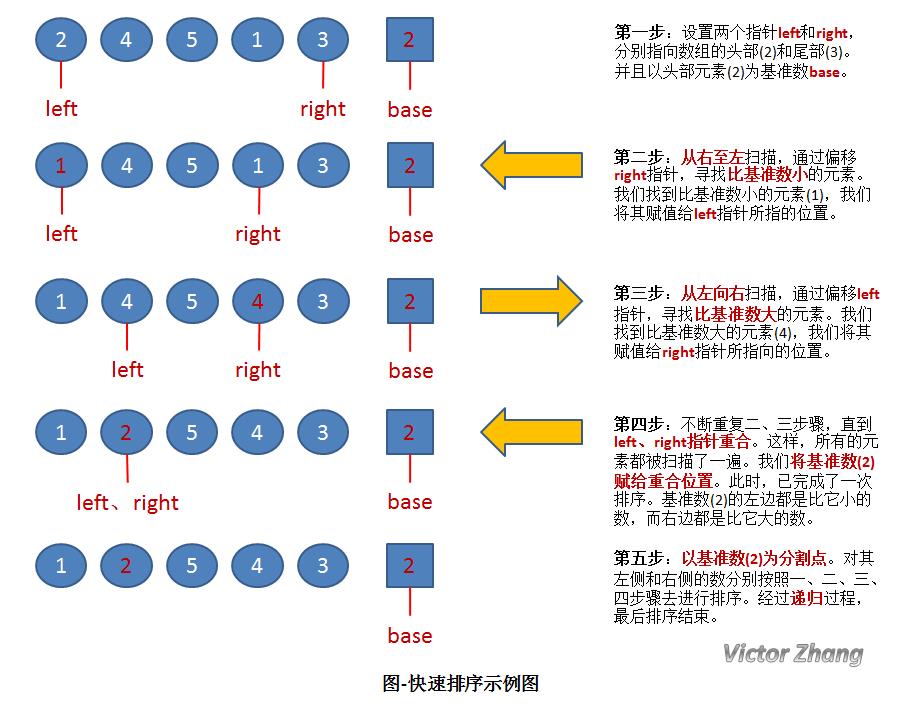
上图中,演示了快速排序的处理过程:
初始状态为一组无序的数组:2、4、5、1、3。
经过以上操作步骤后,完成了第一次的排序,得到新的数组:1、2、5、4、3。
新的数组中,以2为分割点,左边都是比2小的数,右边都是比2大的数。
因为2已经在数组中找到了合适的位置,所以不用再动。
2左边的数组只有一个元素1,所以显然不用再排序,位置也被确定。(注:这种情况时,left指针和right指针显然是重合的。因此在代码中,我们可以通过设置判定条件left必须小于right,如果不满足,则不用排序了)。
而对于2右边的数组5、4、3,设置left指向5,right指向3,开始继续重复图中的一、二、三、四步骤,对新的数组进行排序。
核心代码
// 以最左边的数(left)为基准
int base = list[left];
while (left < right) {
// 从序列右端开始,向左遍历,直到找到小于base的数
while (left < right && list[right] >= base)
right--;
// 找到了比base小的元素,将这个元素放到最左边的位置
list[left] = list[right];
// 从序列左端开始,向右遍历,直到找到大于base的数
while (left < right && list[left] <= base)
left++;
// 找到了比base大的元素,将这个元素放到最右边的位置
list[right] = list[left];
}
// 最后将base放到left位置。此时,left位置的左侧数值应该都比left小;
// 而left位置的右侧数值应该都比left大。
list[left] = base;
return left;
}
private void quickSort(int[] list, int left, int right) {
// 左下标一定小于右下标,否则就越界了
if (left < right) {
// 对数组进行分割,取出下次分割的基准标号
int base = division(list, left, right);
System.out.format("base = %d:\\t", list[base]);
printPart(list, left, right);
// 对“基准标号“左侧的一组数值进行递归的切割,以至于将这些数值完整的排序
quickSort(list, left, base - 1);
// 对“基准标号“右侧的一组数值进行递归的切割,以至于将这些数值完整的排序
quickSort(list, base + 1, right);
}
}
算法分析
快速排序算法的性能
|
排序类别 |
排序方法 |
时间复杂度 |
空间复杂度 |
稳定性 |
复杂性 |
||
|
平均情况 |
最坏情况 |
最好情况 |
|||||
|
交换排序 |
快速排序 |
O(Nlog2N) |
O(N2) |
O(Nlog2N) |
O(Nlog2N) |
不稳定 |
较复杂 |
时间复杂度
当数据有序时,以第一个关键字为基准分为两个子序列,前一个子序列为空,此时执行效率最差。
而当数据随机分布时,以第一个关键字为基准分为两个子序列,两个子序列的元素个数接近相等,此时执行效率最好。
所以,数据越随机分布时,快速排序性能越好;数据越接近有序,快速排序性能越差。
空间复杂度
快速排序在每次分割的过程中,需要 1 个空间存储基准值。而快速排序的大概需要 Nlog2N次 的分割处理,所以占用空间也是 Nlog2N 个。
算法稳定性
在快速排序中,相等元素可能会因为分区而交换顺序,所以它是不稳定的算法。
完整参考代码
JAVA版本
代码实现
运行结果
base = 1: 0 1 4 5 2 6 9 7 8 3
base = 4: 3 2 4 6 9 7 8 5
base = 3: 2 3
base = 6: 5 6 7 8 9
base = 7: 7 8 9
base = 8: 8 9
排序后: 0 1 2 3 4 5 6 7 8 9