倒排索引PForDelta压缩算法——基本假设和霍夫曼压缩同
Posted 将者,智、信、仁、勇、严也。
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了倒排索引PForDelta压缩算法——基本假设和霍夫曼压缩同相关的知识,希望对你有一定的参考价值。
PForDelta算法
PForDelta算法最早由Heman在2005年提出,它允许同时对整个chunk数据(例128个数)进行压缩处理。基础思想是对于一个chunk的数列(例128个),认为其中占多数的x%数据(例90%)占用较小空间,而剩余的少数1-x%(例10%)才是导致数字存储空间过大的异常值。因此,对x%的小数据统一使用较少的b个bit存储,剩下的1-x%数据单独存储。
举个例子,假设我们有一串数列23, 41, 8, 12, 30, 68, 18, 45, 21, 9, ..。取b = 5,即认为5个bit(32)能存储数列中大部分数字,剩下的超过32的数字单独处理。从可见的队列中,超过32的数字有41, 68, 45。那么PForDelta压缩后的数据如下图所示(图中将超过32的数字称为异常值exception):

图中第一个单元(5bit)记录第一个异常值的位置,其值为“1”表示间隔1个b-bit之后是第一个异常值。第一个异常值出现在“23”之后,是“41”,其储存的位置在队列的最末端,而其在128个5bit数字中的值“3”表示间隔3个b-bit之后,是下一个异常值,即“68”,之后依次类推。异常值用32bit记录,在队列末尾从后向前排列。
上述队列就对应一个chunk(DocID),还需要另外记录b的取值和一个chunk压缩后的长度。这样就完整的对一个chunk数据进行了压缩。
但是这样算法有一个明显的不足:如果两个异常值的间隔非常大(例如超过32),我们需要加入更多的空间来记录间隔,并且还需要更多的参数来记录多出多少空间。为了避免这样的问题,出现了改进的算法NewPFD。
改进的PForDelta算法
在PForDelta算法基础上,H. Yan et.al WWW2009提出NewPFD算法及 OptPFD算法。
NewPFD算法
由于PForDelta算法最大的问题是如果异常值间隔太大会造成b-bit放不下。NewPFD的思路是:128个数最多需要7个bit就能保存,如果能将第二部分中保存异常值的32bit进行压缩,省出7bit的空间用于保存这个异常值的位置,问题就迎刃而解了。同时更自然想到,如果异常值位置信息保存在队列后方的32bit中,那么队列第一部分原用于记录异常值间隔的对应部分空间就空余出来了,可以利用这部分做进一步改进。
因此,NewPFD的算法是,假设128个数中,取b=5bit,即32作为阈值。数列中低于32的数字正常存放,数列中大于32的数字,例如41 (101001) 将其低5位(b-bit)放在第一部分,将其剩下的高位(overflow)存放在队列末端。我们依然以PForDelta中的例子作为说明,一个128位数列23, 41, 8, 12, 30, 68, 18, 45, 21, 9, ..。经过NewPFD算法压缩后的形式如下图所示:
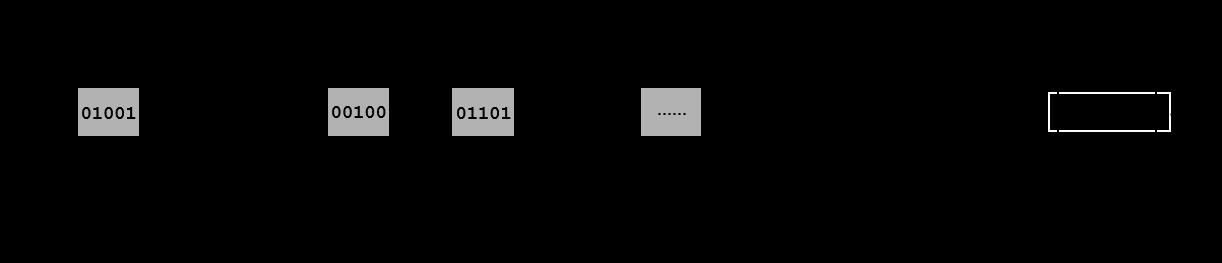
NewPFD算法压缩后的数据依然包括两部分,第一部分128个b-bit数列,省去了第一个异常值位置单元;第二部分异常值部分包含异常值的位置和异常值的高位数字。例如,对于异常值“41”其2进制码为101001,那么低5位01001保存在数据块第一部分。在第二部分中,先保存位置信息(“41”的位置是“1”,表示原数列第2个),再以字节为单位保存高位“1”即“0000 0001”,这样反而只需要附加2个字节(一个保存位置,一个保存高位)就可以储存原本需要4个字节保存的异常值。而对于高位字节,还可以继续使用压缩算法进行压缩,本文不再继续讨论。
除了数据列,NewPFD算法还需要另外保存b值和高位占的字节数(称为a值)。因为参数ab已经确定了数据块的长度,因此chunk长度值不用再单独记录。
OptPFD算法
OptPFD算法在NewPFD之上,认为每个数据压缩单元chunk应该有适应自己数据的独立a值和b值,这样虽然需要保存大量的ab值,但是毕竟数据量小不会影响太大的速度,相反,由于对不同chunk单独压缩,使压缩效果更好,反而提高了解压缩的效果。
对于b的选取,通常选择2^b可以覆盖数列中90%的数字,也就是控制异常值在10%左右,这样可以获得压缩效果和解压缩效率的最大化。
索引压缩步骤
代码见:http://www.cnblogs.com/huxiao-tee/p/4644422.html
以上是关于倒排索引PForDelta压缩算法——基本假设和霍夫曼压缩同的主要内容,如果未能解决你的问题,请参考以下文章
倒排列表压缩算法汇总——分区Elias-Fano编码貌似是最牛叉的啊!
ElasticSearch探索之路索引原理:倒排索引列式存储Fielddata索引压缩联合索引
ElasticSearch探索之路索引原理:倒排索引列式存储Fielddata索引压缩联合索引