Android解析HTML网页数据 第一个方法Jsoup
Posted 瞎子客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Android解析HTML网页数据 第一个方法Jsoup相关的知识,希望对你有一定的参考价值。
最近发现一些无聊的东西,就是抓取网页上的数据,然后使用安卓原生代码显示出来,或者说借用网页数据,用自定义的View显示。
借助jsoup-1.10.2.jar库,获取并解析数据。(Jsoup百度云下载地址:http://pan.baidu.com/s/1nvSFKyl)
jsoup官方文档:
https://jsoup.org/cookbook/
中文文档:
http://www.open-open.com/jsoup/
应用场景:
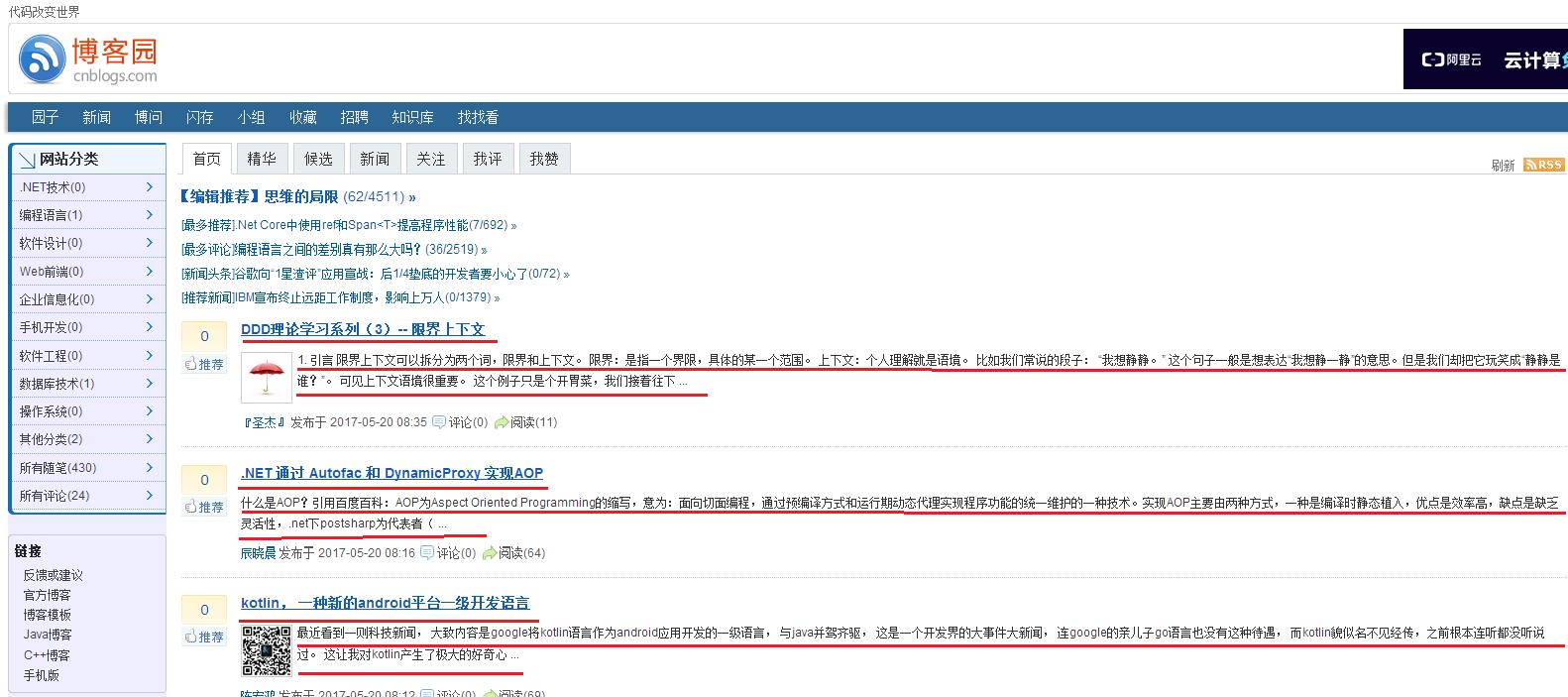
我需要获取博客园网页上的数据,如图中标记的文字标题,链接,文本简介。
1、浏览器打开网页,然后右键查看网页源码,或者按F12审查元素。(区别:审查元素(或者用开发者工具,Firebug)看到的是现在实时性的内容(经过js的修改),而网页源代码看到的是就是最开始浏览器收到HTTP响应内容)

找到对应的html代码。
2、找到对应的节点<div class="post_item_body"> <a class="titlelnk"> <p class="post_item_summary">,使用Jsoup解析。代码如下:
public void testJsoup(){ new Thread(new Runnable() { @Override public void run() { // TODO Auto-generated method stub try { Document doc = Jsoup.connect("http://www.cnblogs.com/").get(); Elements elements = doc.select("div.post_item_body"); for(Element element : elements){ Elements title = element.select("a.titlelnk"); Log.e("title:", title.get(0).text()); Log.e("url", title.get(0).attr("href")); Elements content = element.select("p.post_item_summary"); Log.e("content:", content.get(0).text()); } } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } catch (Exception e) { // TODO: handle exception } } }).start(); }
3、打印日志,如下:
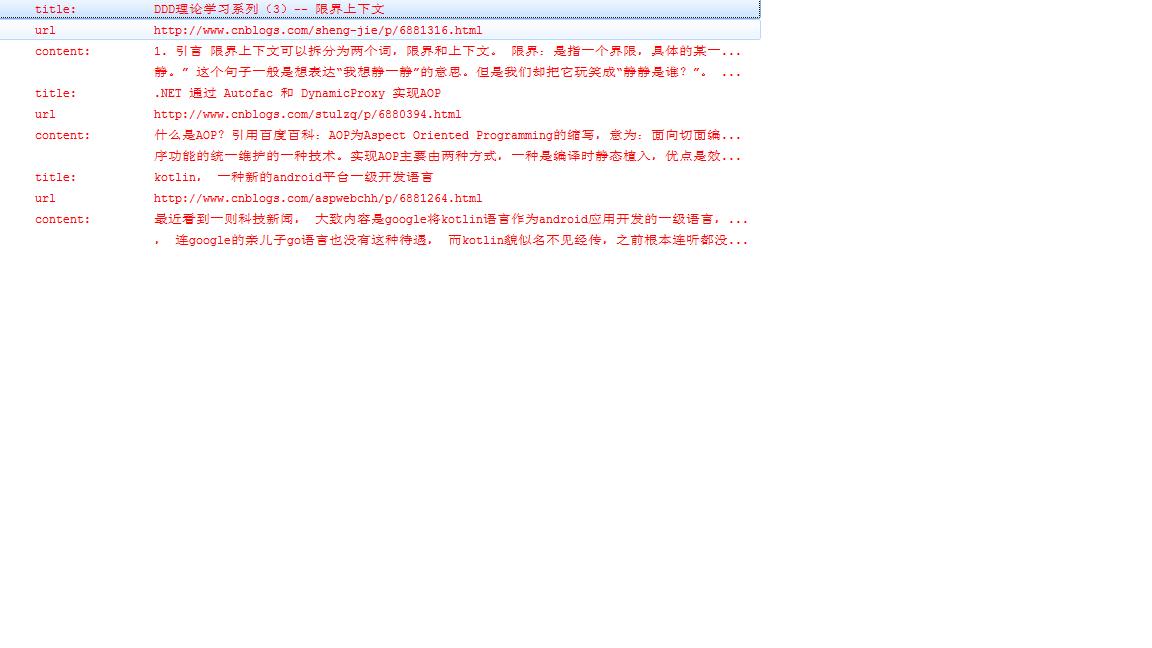
到这里,网页数据基本可以解析出来。
以上是关于Android解析HTML网页数据 第一个方法Jsoup的主要内容,如果未能解决你的问题,请参考以下文章