elasticsearch 使用心得
Posted 风行天下-2080
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了elasticsearch 使用心得相关的知识,希望对你有一定的参考价值。
安装所遇到的问题:
http://www.bubuko.com/infodetail-1889252.html
一,先创建用户和组
groupadd es useradd -g es es passwd es
二,下载对应文件
初始条件要安装java
yum -y install java
Download and install the .tar.gz packageedit
The .tar.gz archive for Elasticsearch v5.4.0 can be downloaded and installed as follows:
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-5.4.0.tar.gz
sha1sum elasticsearch-5.4.0.tar.gz 
三,切换用户并解压文件
su es
tar -xzf elasticsearch-5.4.0.tar.gz
然后chmod 777 给文件所在的目录授权
cd elasticsearch-5.4.0/
四,启动软件
[root@linux-node2 ~]# su es
[es@linux-node2 root]$ cd elasticsearch-5.4.0
[es@linux-node2 elasticsearch-5.4.0]$ ./bin/elasticsearch
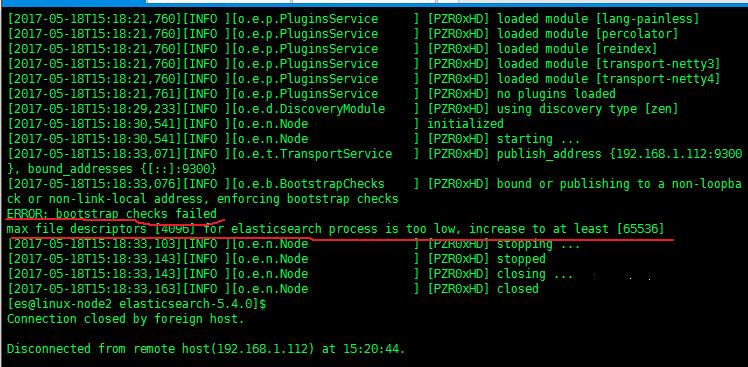
启动后总是这里报错,然后参考下面文章进行修改。
五,排错的过程
结合tail命令进行排查
[root@linux-node2 ~]# tail -100f /root/elasticsearch-5.4.0/logs/elasticsearch.log
六测试
[root@linux-node2 ~]# curl http://192.168.1.112:9200
{
"name" : "PZR0xHD",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "8SGo5ehvQxyYxlRGrUgwpQ",
"version" : {
"number" : "5.4.0",
"build_hash" : "780f8c4",
"build_date" : "2017-04-28T17:43:27.229Z",
"build_snapshot" : false,
"lucene_version" : "6.5.0"
},
"tagline" : "You Know, for Search"
}
ELK学习系列文章第二章:elasticsearch常见错误与配置简介::
http://m.blog.csdn.net/article/details?id=53577115
在安装Elasticsearch时候,会出现一些坑,我这里做个总结,目的是进行一些记录以及后面使用的童鞋一个参考,同时把其配置做一个简介。
一、常见错误
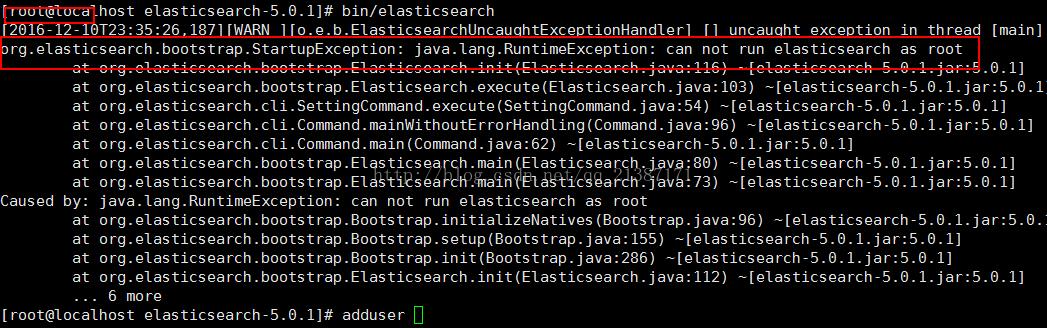
1.1 root用户启动elasticsearch报错
Elasticsearch为了安全考虑,不让使用root启动,解决方法新建一个用户,用此用户进行相关的操作。如果你用root启动,会出现“java.lang.RuntimeException: can not runelasticsearch as root”错误,具体如下所示:
1.2 JVM虚拟机内存不足
错误:“JavaHotSpot(TM) 64-Bit Server VM warning: INFO: error=\'Cannotallocate memory\' (errno=12)”表示内存不足,其配置文件为config目录下的jvm.options,默认为2g,可以修改为1g。
1.3 max_map_count过小
错误“max virtual memory areas vm.max_map_count [65530]is too low, increase to at least [262144]”,max_map_count文件包含限制一个进程可以拥有的VMA(虚拟内存区域)的数量,系统默认是65530,修改成262144。解决方法是修改/etc/sysctl.conf配置文件,添加vm.max_map_count=262144,记得需要重启机器才起作用,修改后配置如下图所示:

1.4 max file descriptors过小
错误“max file descriptors [65535] for elasticsearchprocess is too low, increase to at least [65536]”,maxfile descriptors为最大文件描述符,设置其大于65536即可。解决方法是修改/etc/security/limits.conf文件,添加“* - nofile65536 * - memlock unlimited”,“*”表示给所有用户起作用,修改后的配置如下图所示:
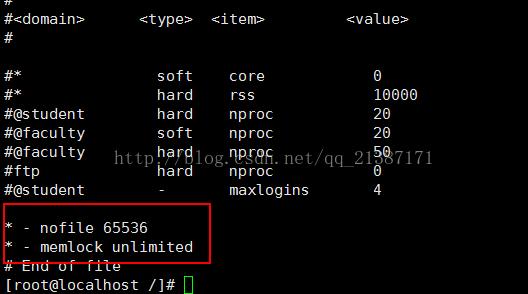
一定要重新启动机器要不死活就是你麻痹的,启动不了。
1.5外网访问设置
细心的同学也许发现第一章验证是用的“localhost:9200”,如果换成“IP:9200”,则浏览器与curl都无法进行访问,那么如何让外网访问呢?网上查了一下,需要修改config目录下elasticsearch.yml文件,修改network.host为“0.0.0.0”,然后进行启动成功,外网就可以访问啦。但是很遗憾,在我的机器还出现了其他错误,具体如下所示:
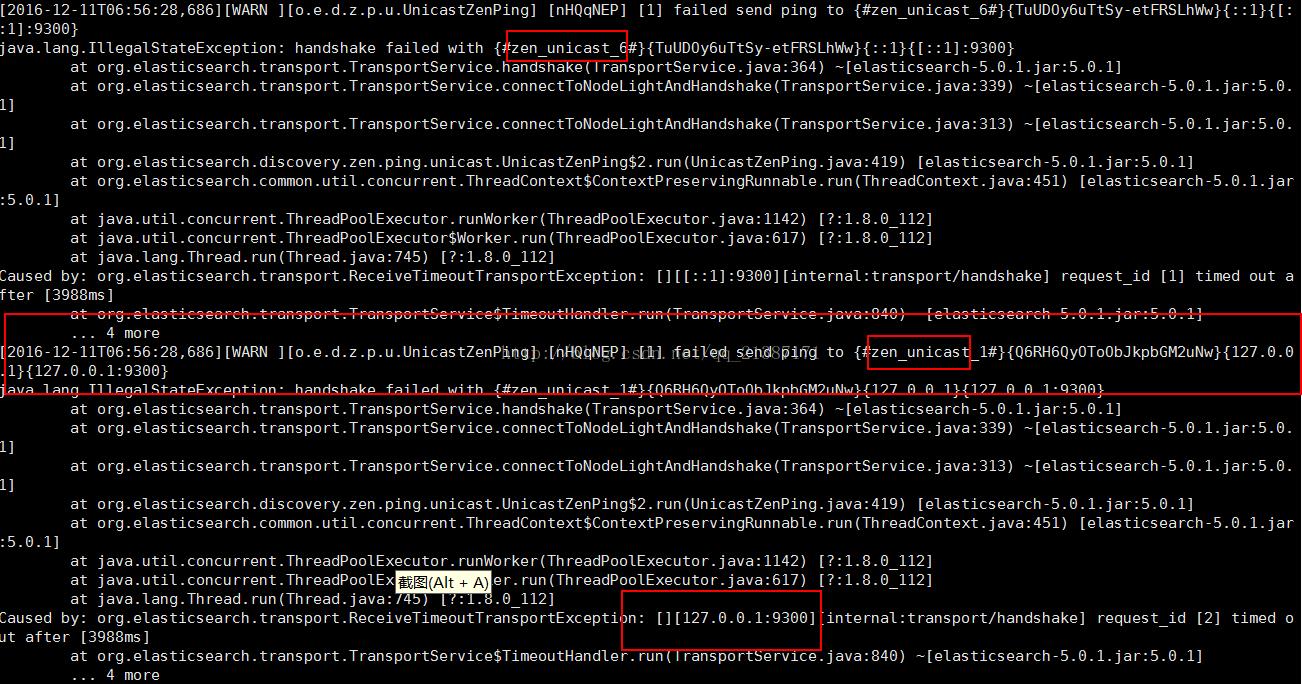
通过上面的错误信息,想到需要修改config目录下elasticsearch.yml文件,修改discovery.zen.ping.unicast.hosts为“[“0.0.0.0”]”,然后再次启动,发现没有报错信息(注意防火墙对于端口的限制),同时远程浏览器访问也正常,如下图所示:
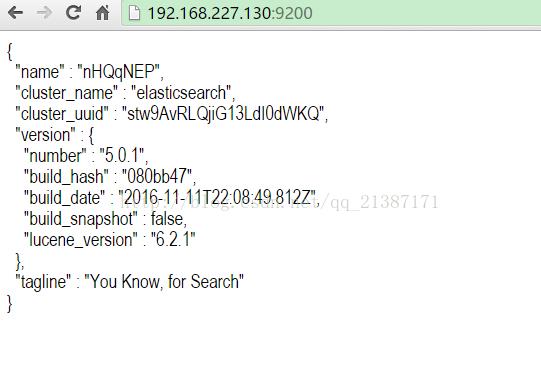
+++++++++++++++++++++++++++++++++++++++配置简介++++++++++++++++++++++++++++++++++++++++++++++++
elasticsearch配置简介
配置文件在config目录下:jvm.options、elasticsearch.yml和log4j2.properties。其中jvm.options为虚拟机配置,log4j2.properties为日志配置,都相对比较简单。下面重点介绍elasticsearch.yml一些重要的配置项及其含义。
(1)cluster.name: elasticsearch
配置elasticsearch的集群名称,默认是elasticsearch。elasticsearch会自动发现在同一网段下的集群名为elasticsearch的主机,如果在同一网段下有多个集群,就可以用这个属性来区分不同的集群。生成环境时建议更改。
(2)node.name: “node-1”
节点名,默认随机指定一个name列表中名字,该列表在elasticsearch的jar包中config文件夹里name.txt文件中,其中有很多作者添加的有趣名字,大部分是漫威动漫里面的人物名字。生成环境中建议更改以能方便的指定集群中的节点对应的机器
(3)node.master: true
指定该节点是否有资格被选举成为node,默认是true,elasticsearch默认集群中的第一台启动的机器为master,如果这台机挂了就会重新选举master。
(4)node.data: true
指定该节点是否存储索引数据,默认为true。如果节点配置node.master:false并且node.data: false,则该节点将起到负载均衡的作用
(5)index.number_of_shards: 5
设置默认索引分片个数,默认为5片。经本人测试,索引分片对ES的查询性能有很大的影响,在应用环境,应该选择适合的分片大小。
(6)index.number_of_replicas:
设置默认索引副本个数,默认为1个副本。此处的1个副本是指index.number_of_shards的一个完全拷贝;默认5个分片1个拷贝;即总分片数为10。
(7)path.conf: /path/to/conf
设置配置文件的存储路径,默认是es根目录下的config文件夹。
(8)path.data:/path/to/data1,/path/to/data2
设置索引数据的存储路径,默认是es根目录下的data文件夹,可以设置多个存储路径,用逗号隔开。
(9)path.logs: /path/to/logs
设置日志文件的存储路径,默认是es根目录下的logs文件夹
(10)path.plugins: /path/to/plugins
设置插件的存放路径,默认是es根目录下的plugins文件夹
(11)bootstrap.memory_lock: true
设置为true来锁住内存。因为当jvm开始swapping时es的效率会降低,所以要保证它不swap,可以把ES_MIN_MEM和ES_MAX_MEM两个环境变量设置成同一个值,并且保证机器有足够的内存分配给es。同时也要允许elasticsearch的进程可以锁住内存,linux下可以通过ulimit -l unlimited命令。
(12)network.host: 192.168.0.1
这个参数是用来同时设置bind_host和publish_host上面两个参数。
(13)http.port: 9200
设置对外服务的http端口,默认为9200。
(14)gateway.recover_after_nodes: 1
设置集群中N个节点启动时进行数据恢复,默认为1。
(15)discovery.zen.minimum_master_nodes: 1
设置这个参数来保证集群中的节点可以知道其它N个有master资格的节点。默认为1,对于大的集群来说,可以设置大一点的值(2-4)
(16)discovery.zen.ping.timeout: 3s
设置集群中自动发现其它节点时ping连接超时时间,默认为3秒,对于比较差的网络环境可以高点的值来防止自动发现时出错。
(17)discovery.zen.ping.multicast.enabled:false
设置是否打开多播发现节点,默认是true。
(18)discovery.zen.ping.unicast.hosts: [“host1”, “host2:port”]
设置集群中master节点的初始列表,可以通过这些节点来自动发现新加入集群的节点。
三、总结
在学习一个新的东西,需要保持耐心以及擅长思考的能力。本章节主要讲述安装运行elasticsearch过程常见的错误,同时给出解决方法;第二部分,介绍了一些常用的配置参数的含义,这样可以根据自己的环境进行合理的配置
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
logstash安装配置过程
官方网站:https://www.elastic.co/cn/products 在里面选择logstash:https://www.elastic.co/cn/products/logstash
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
elasticsearch-head
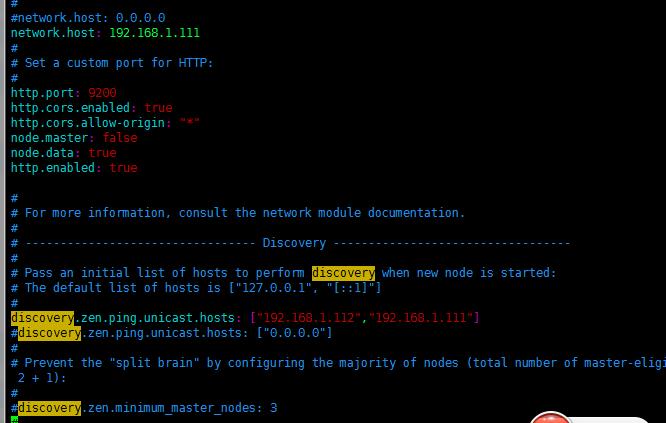
使其起作用需要在,yml文件做如下修改:
network.host: 192.168.1.111
#
# Set a custom port for HTTP:
#
http.port: 9200
http.cors.enabled: true
http.cors.allow-origin: "*"
node.master: false
node.data: true
http.enabled: true
以上是关于elasticsearch 使用心得的主要内容,如果未能解决你的问题,请参考以下文章