scrapy爬虫框架
Posted Braveliberty
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了scrapy爬虫框架相关的知识,希望对你有一定的参考价值。
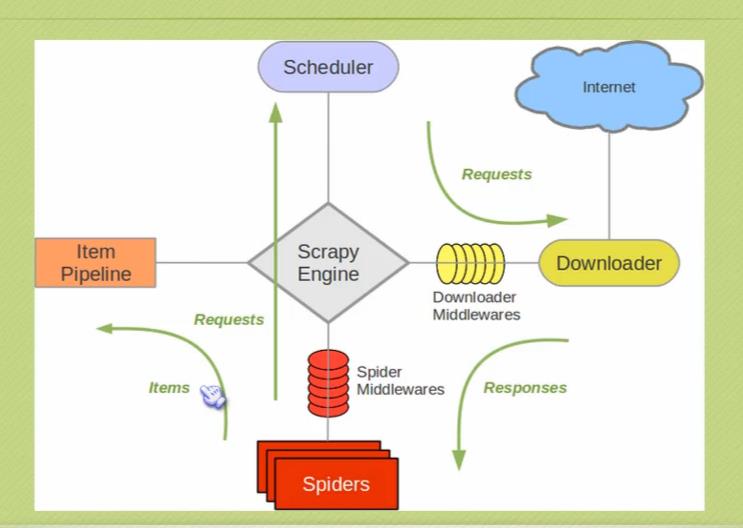
downloader:负责下载html页面
spider:负责爬取页面内容,我们需要自己写爬取规则 srapy提供了selector,获取的方式有xpath,css,正则,extract
item容器:spider获取到的内容放到item中
schedul:负责调度
以上是关于scrapy爬虫框架的主要内容,如果未能解决你的问题,请参考以下文章