如何监控flume的重复读取数据的问题
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何监控flume的重复读取数据的问题相关的知识,希望对你有一定的参考价值。
参考技术A 你把新文件传递到flume监控目录,flume会自动发现这个文件,并且上传常见的几种Flume日志收集场景实战
这里主要介绍几种常见的日志的source来源,包括监控文件型,监控文件内容增量,TCP和HTTP。
Spool类型
用于监控指定目录内数据变更,若有新文件,则将新文件内数据读取上传
在最后有介绍此案例
Exec
EXEC执行一个给定的命令获得输出的源,如果要使用tail命令,必选使得file足够大才能看到输出内容
创建agent配置文件
# vi /usr/local/flume170/conf/exec_tail.conf
a1.sources = r1 a1.channels = c1 c2 a1.sinks = k1 k2# Describe/configure the sourcea1.sources.r1.type = execa1.sources.r1.channels = c1 c2 a1.sources.r1.command = tail -F /var/log/haproxy.log# Use a channel which buffers events in memorya1.channels.c1.type = memory a1.channels.c1.capacity = 1000a1.channels.c1.transactionCapacity = 100a1.channels.c2.type = file a1.channels.c2.checkpointDir = /usr/local/flume170/checkpoint a1.channels.c2.dataDirs = /usr/local/flume170/data# Describe the sinka1.sinks.k1.type = logger a1.sinks.k1.channel =c1 a1.sinks.k2.type = FILE_ROLL a1.sinks.k2.channel = c2 a1.sinks.k2.sink.directory = /usr/local/flume170/files a1.sinks.k2.sink.rollInterval = 0
启动flume agent a1
# /usr/local/flume170/bin/flume-ng agent -c . -f /usr/local/flume170/conf/exec_tail.conf -n a1 -Dflume.root.logger=INFO,console
生成足够多的内容在文件里
# for i in {1..100};do echo "exec tail$i" >> /usr/local/flume170/log_exec_tail;echo $i;sleep 0.1;done
在H32的控制台,可以看到以下信息:
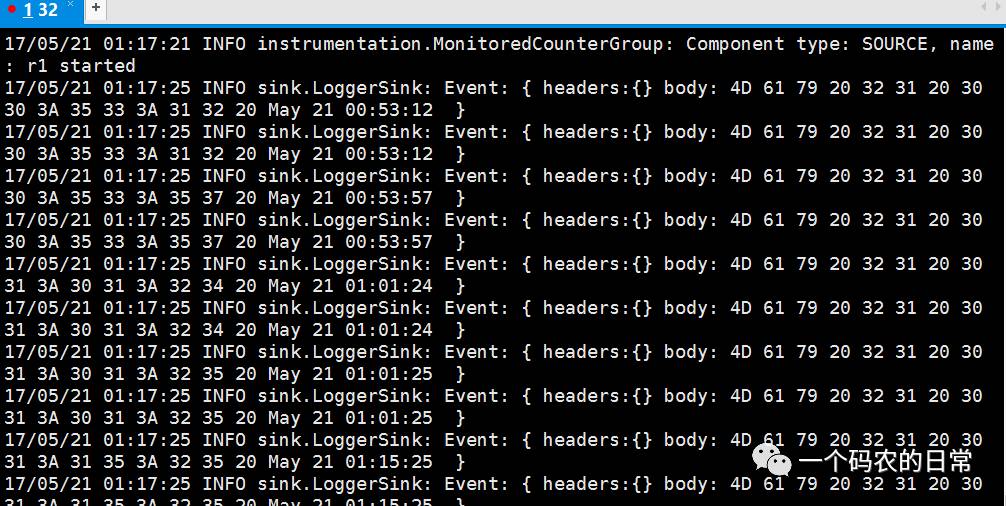
Http
JSONHandler型
基于HTTP POST或GET方式的数据源,支持JSON、BLOB表示形式
创建agent配置文件
# vi /usr/local/flume170/conf/post_json.conf
a1.sources = r1 a1.channels = c1 a1.sinks = k1# Describe/configure the sourcea1.sources.r1.type = org.apache.flume.source.http.HTTPSource a1.sources.r1.port = 5142a1.sources.r1.channels = c1# Use a channel which buffers events in memorya1.channels.c1.type = memory a1.channels.c1.capacity = 1000a1.channels.c1.transactionCapacity = 100# Describe the sinka1.sinks.k1.type = logger a1.sinks.k1.channel = c1
启动flume agent a1
# /usr/local/flume170/bin/flume-ng agent -c . -f /usr/local/flume170/conf/post_json.conf -n a1 -Dflume.root.logger=INFO,console
生成JSON 格式的POST request
# curl -X POST -d '[{ "headers" :{"a" : "a1","b" : "b1"},"body" : "idoall.org_body"}]' http://localhost:8888
在H32的控制台,可以看到以下信息:
![]()
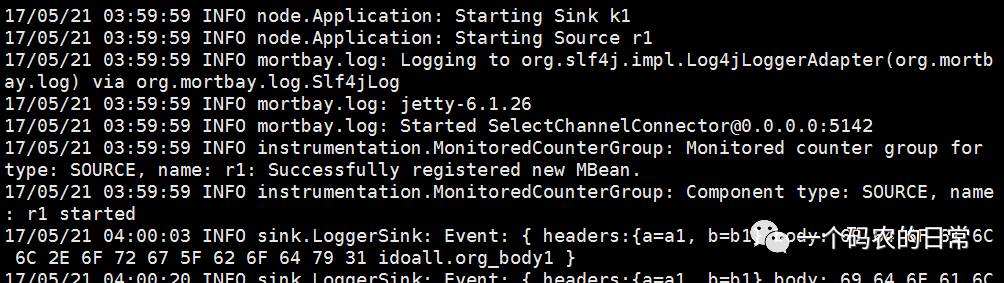
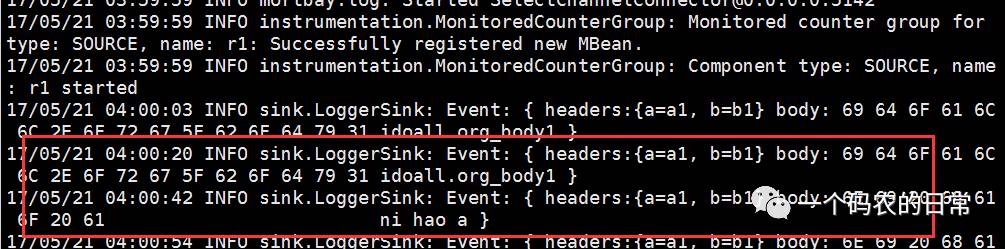
Tcp
Syslogtcp监听TCP的端口做为数据源
创建agent配置文件
# vi /usr/local/flume170/conf/syslog_tcp.conf
a1.sources = r1 a1.channels = c1 a1.sinks = k1# Describe/configure the sourcea1.sources.r1.type = syslogtcp a1.sources.r1.port = 5140a1.sources.r1.host = H32 a1.sources.r1.channels = c1# Use a channel which buffers events in memorya1.channels.c1.type = memory a1.channels.c1.capacity = 1000a1.channels.c1.transactionCapacity = 100# Describe the sinka1.sinks.k1.type = logger a1.sinks.k1.channel = c1
启动flume agent a1
# /usr/local/flume170/bin/flume-ng agent -c . -f /usr/local/flume170/conf/syslog_tcp.conf -n a1 -Dflume.root.logger=INFO,console
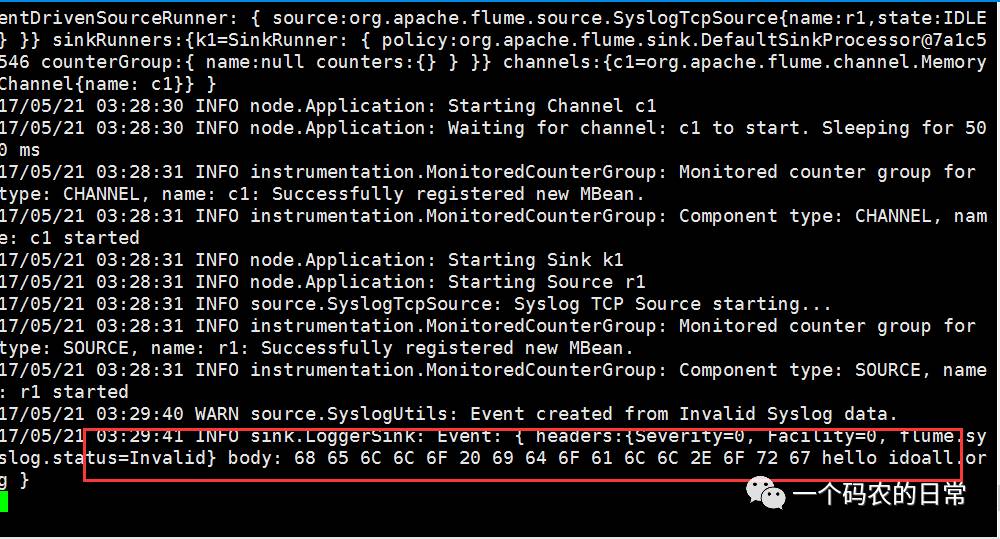
测试产生syslog
# echo "hello idoall.org syslog" | nc localhost 5140
在H32的控制台,可以看到以下信息:

Flume Sink Processors和Avro类型
Avro可以发送一个给定的文件给Flume,Avro 源使用AVRO RPC机制。
failover的机器是一直发送给其中一个sink,当这个sink不可用的时候,自动发送到下一个sink。channel的transactionCapacity参数不能小于sink的batchsiz
在H32创建Flume_Sink_Processors配置文件
# vi /usr/local/flume170/conf/Flume_Sink_Processors.conf
a1.sources = r1 a1.channels = c1 c2 a1.sinks = k1 k2# Describe/configure the sourcea1.sources.r1.type = syslogtcp a1.sources.r1.port = 5140a1.sources.r1.channels = c1 c2 a1.sources.r1.selector.type = replicating# Use a channel which buffers events in memorya1.channels.c1.type = memory a1.channels.c1.capacity = 1000a1.channels.c1.transactionCapacity = 100a1.channels.c2.type = memory a1.channels.c2.capacity = 1000a1.channels.c2.transactionCapacity = 100# Describe the sinka1.sinks.k1.type = avro a1.sinks.k1.channel = c1 a1.sinks.k1.hostname = H32 a1.sinks.k1.port = 5141a1.sinks.k2.type = avro a1.sinks.k2.channel = c2 a1.sinks.k2.hostname = H33 a1.sinks.k2.port = 5141# 这个是配置failover的关键,需要有一个sink groupa1.sinkgroups = g1 a1.sinkgroups.g1.sinks = k1 k2# 处理的类型是failovera1.sinkgroups.g1.processor.type = failover# 优先级,数字越大优先级越高,每个sink的优先级必须不相同a1.sinkgroups.g1.processor.priority.k1 = 5a1.sinkgroups.g1.processor.priority.k2 = 10# 设置为10秒,当然可以根据你的实际状况更改成更快或者很慢a1.sinkgroups.g1.processor.maxpenalty = 10000
在H32创建Flume_Sink_Processors_avro配置文件
# vi /usr/local/flume170/conf/Flume_Sink_Processors_avro.conf
a1.sources = r1 a1.channels = c1 a1.sinks = k1# Describe/configure the sourcea1.sources.r1.type = avro a1.sources.r1.channels = c1 a1.sources.r1.bind = 0.0.0.0a1.sources.r1.port = 5141# Use a channel which buffers events in memorya1.channels.c1.type = memory a1.channels.c1.capacity = 1000a1.channels.c1.transactionCapacity = 100# Describe the sinka1.sinks.k1.type = logger a1.sinks.k1.channel = c1
将2个配置文件复制到H33上一份
/usr/local/flume170# scp -r /usr/local/flume170/conf/Flume_Sink_Processors.conf H33:/usr/local/flume170/conf/Flume_Sink_Processors.conf
/usr/local/flume170# scp -r /usr/local/flume170/conf/Flume_Sink_Processors_avro.conf H33:/usr/local/flume170/conf/Flume_Sink_Processors_avro.conf
打开4个窗口,在H32和H33上同时启动两个flume agent
# /usr/local/flume170/bin/flume-ng agent -c . -f /usr/local/flume170/conf/Flume_Sink_Processors_avro.conf -n a1 -Dflume.root.logger=INFO,console
# /usr/local/flume170/bin/flume-ng agent -c . -f /usr/local/flume170/conf/Flume_Sink_Processors.conf -n a1 -Dflume.root.logger=INFO,console
然后在H32或H33的任意一台机器上,测试产生log
# echo "idoall.org test1 failover" | nc H32 5140
因为H33的优先级高,所以在H33的sink窗口,可以看到以下信息,而H32没有:
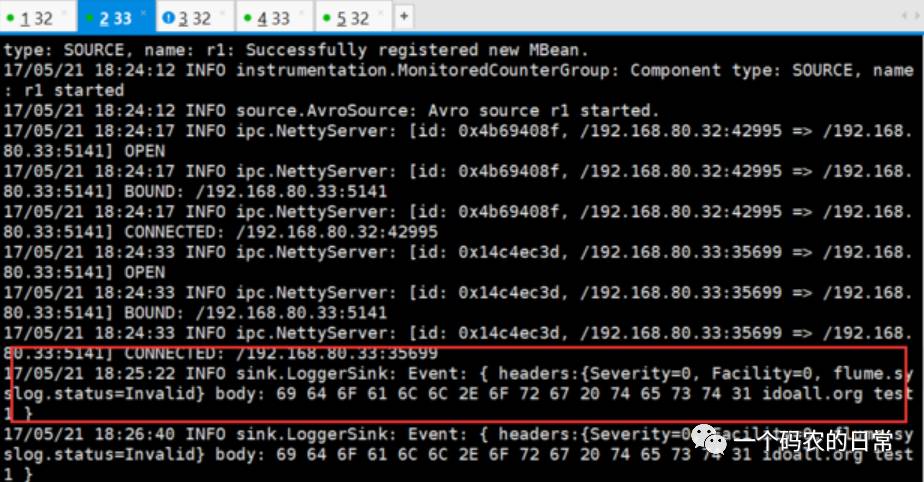
这时我们停止掉H33机器上的sink(ctrl+c),再次输出测试数据
# echo "idoall.org test2 failover" | nc localhost 5140
可以在H32的sink窗口,看到读取到了刚才发送的两条测试数据:
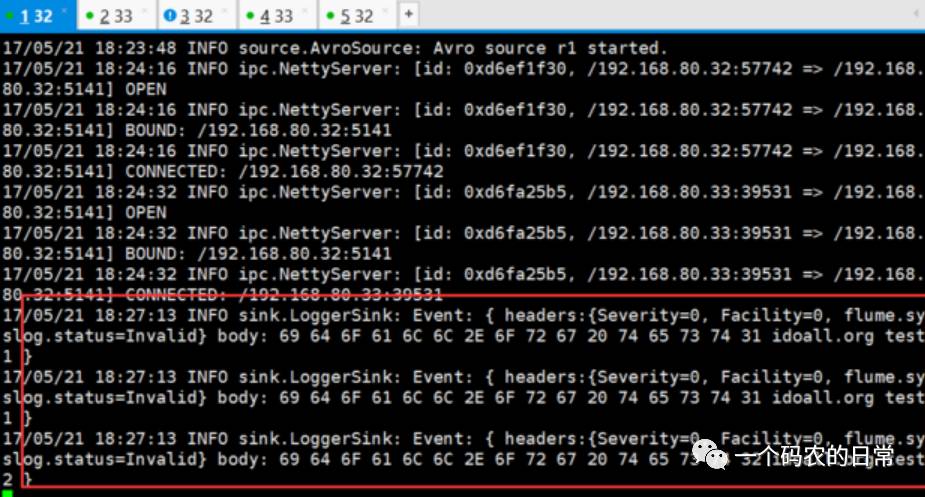
我们再在H33的sink窗口中,启动sink:
# /usr/local/flume170/bin/flume-ng agent -c . -f /usr/local/flume170/conf/Flume_Sink_Processors_avro.conf -n a1 -Dflume.root.logger=INFO,console
输入两批测试数据:
# echo "idoall.org test3 failover" | nc localhost 5140 && echo "idoall.org test4 failover" | nc localhost 5140
在H33的sink窗口,我们可以看到以下信息,因为优先级的关系,log消息会再次落到H33上:
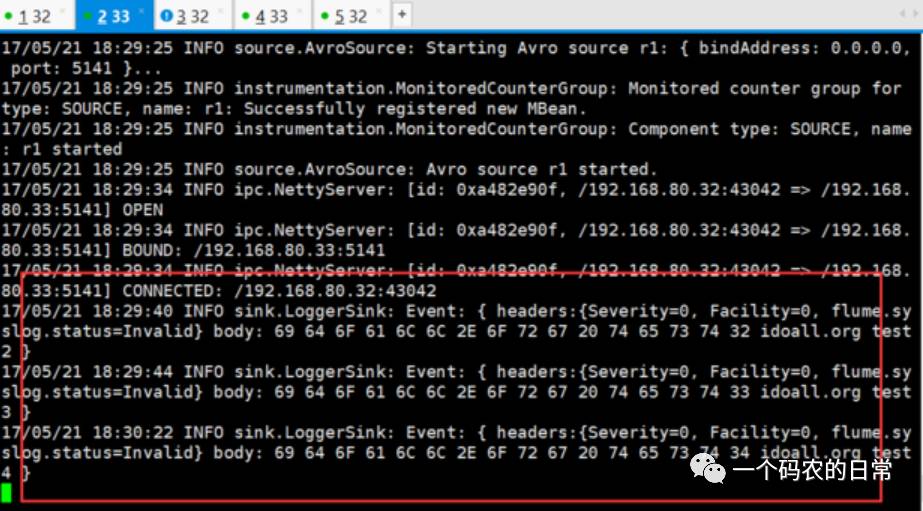
Load balancing Sink Processor
load balance type和failover不同的地方是,load balance有两个配置,一个是轮询,一个是随机。两种情况下如果被选择的sink不可用,就会自动尝试发送到下一个可用的sink上面。
在H32创建Load_balancing_Sink_Processors配置文件
# vi /usr/local/flume170/conf/Load_balancing_Sink_Processors.conf
a1.sources = r1 a1.channels = c1 a1.sinks = k1 k2# Describe/configure the sourcea1.sources.r1.type = syslogtcp a1.sources.r1.port = 5140a1.sources.r1.channels = c1# Use a channel which buffers events in memorya1.channels.c1.type = memory a1.channels.c1.capacity = 1000a1.channels.c1.transactionCapacity = 100# Describe the sinka1.sinks.k1.type = avro a1.sinks.k1.channel = c1 a1.sinks.k1.hostname = H32 a1.sinks.k1.port = 5141a1.sinks.k2.type = avro a1.sinks.k2.channel = c1 a1.sinks.k2.hostname = H33 a1.sinks.k2.port = 5141# 这个是配置failover的关键,需要有一个sink groupa1.sinkgroups = g1 a1.sinkgroups.g1.sinks = k1 k2# 处理的类型是load_balancea1.sinkgroups.g1.processor.type = load_balance a1.sinkgroups.g1.processor.backoff = true a1.sinkgroups.g1.processor.selector = round_robin
在H32创建Load_balancing_Sink_Processors_avro配置文件
# vi /usr/local/flume170/conf/Load_balancing_Sink_Processors_avro.conf
a1.sources = r1 a1.channels = c1 a1.sinks = k1# Describe/configure the sourcea1.sources.r1.type = avro a1.sources.r1.channels = c1 a1.sources.r1.bind = 0.0.0.0a1.sources.r1.port = 5141# Use a channel which buffers events in memorya1.channels.c1.type = memory a1.channels.c1.capacity = 1000a1.channels.c1.transactionCapacity = 100# Describe the sinka1.sinks.k1.type = logger a1.sinks.k1.channel = c1
将2个配置文件复制到H33上一份
/usr/local/flume170# scp -r /usr/local/flume170/conf/Load_balancing_Sink_Processors.conf H33:/usr/local/flume170/conf/Load_balancing_Sink_Processors.conf
/usr/local/flume170# scp -r /usr/local/flume170/conf/Load_balancing_Sink_Processors_avro.conf H33:/usr/local/flume170/conf/Load_balancing_Sink_Processors_avro.conf
打开4个窗口,在H32和H33上同时启动两个flume agent
# /usr/local/flume170/bin/flume-ng agent -c . -f /usr/local/flume170/conf/Load_balancing_Sink_Processors_avro.conf -n a1 -Dflume.root.logger=INFO,console
# /usr/local/flume170/bin/flume-ng agent -c . -f /usr/local/flume170/conf/Load_balancing_Sink_Processors.conf -n a1 -Dflume.root.logger=INFO,console
然后在H32或H33的任意一台机器上,测试产生log,一行一行输入,输入太快,容易落到一台机器上
# echo "idoall.org test1" | nc H32 5140
# echo "idoall.org test2" | nc H32 5140
# echo "idoall.org test3" | nc H32 5140
# echo "idoall.org test4" | nc H32 5140
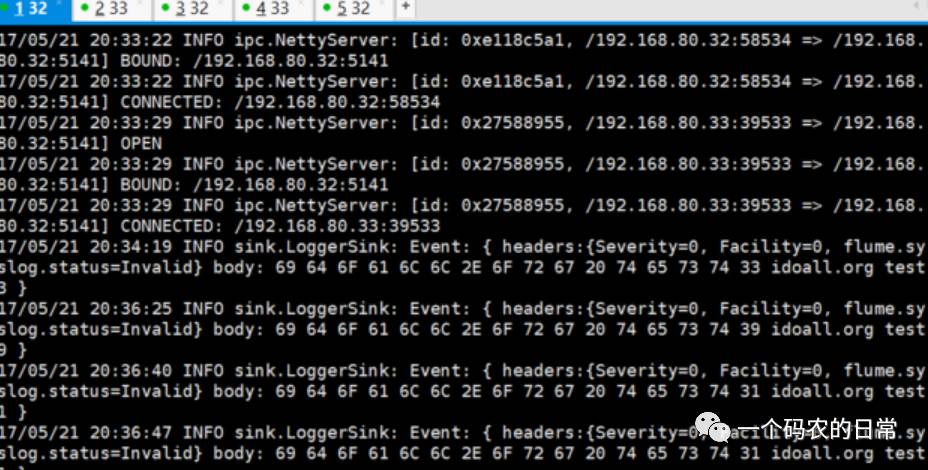
在H32的sink窗口,可以看到以下信息
1. 14/08/10 15:35:29 INFO sink.LoggerSink: Event: { headers:{Severity=0, flume.syslog.status=Invalid, Facility=0} body: 69 64 6F 61 6C 6C 2E 6F 72 67 20 74 65 73 74 32 idoall.org test2 }
2. 14/08/10 15:35:33 INFO sink.LoggerSink: Event: { headers:{Severity=0, flume.syslog.status=Invalid, Facility=0} body: 69 64 6F 61 6C 6C 2E 6F 72 67 20 74 65 73 74 34 idoall.org test4 }
在H33的sink窗口,可以看到以下信息:
1. 14/08/10 15:35:27 INFO sink.LoggerSink: Event: { headers:{Severity=0, flume.syslog.status=Invalid, Facility=0} body: 69 64 6F 61 6C 6C 2E 6F 72 67 20 74 65 73 74 31 idoall.org test1 }
2. 14/08/10 15:35:29 INFO sink.LoggerSink: Event: { headers:{Severity=0, flume.syslog.status=Invalid, Facility=0} body: 69 64 6F 61 6C 6C 2E 6F 72 67 20 74 65 73 74 33 idoall.org test3 }
说明轮询模式起到了作用。
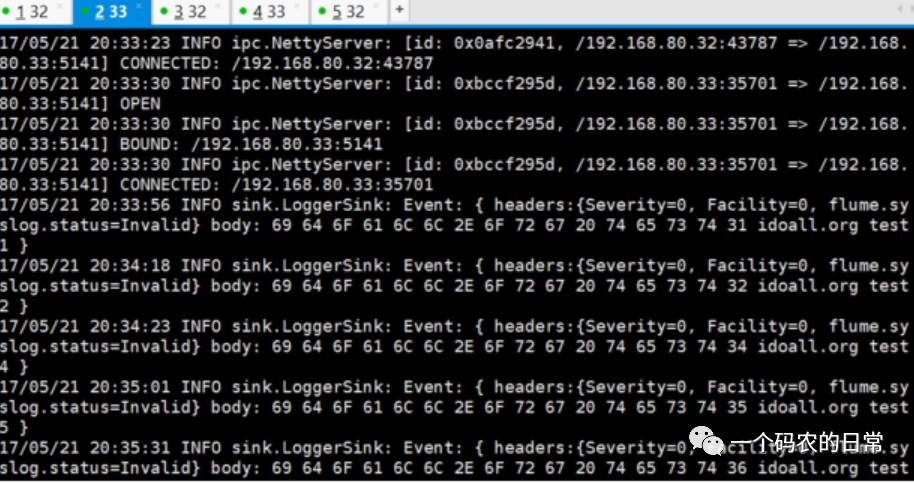
以上均是建立在H32和H33能互通,且Flume配置都正确的情况下运行,且都是非常简单的场景应用,值得注意的一点是Flume说是日志收集,其实还可以广泛的认为“日志”可以当作是信息流,不局限于认知的日志。
一个码农的日常 分享干货知识、互联网+、创业知识、码农的人生感悟
2号群: 340250479
以上是关于如何监控flume的重复读取数据的问题的主要内容,如果未能解决你的问题,请参考以下文章