R语言用nls做非线性回归以及函数模型的参数估计
Posted 苦瓜的甜
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R语言用nls做非线性回归以及函数模型的参数估计相关的知识,希望对你有一定的参考价值。
非线性回归是在对变量的非线性关系有一定认识前提下,对非线性函数的参数进行最优化的过程,最优化后的参数会使得模型的RSS(残差平方和)达到最小。在R语言中最为常用的非线性回归建模函数是nls,下面以car包中的USPop数据集为例来讲解其用法。数据中population表示人口数,year表示年份。如果将二者绘制散点图可以发现它们之间的非线性关系。在建立非线性回归模型时需要事先确定两件事,一个是非线性函数形式,另一个是参数初始值。
一、模型拟合
对于人口模型可以采用Logistic增长函数形式,它考虑了初期的指数增长以及总资源的限制。其函数形式如下。

首先载入car包以便读取数据,然后使用nls函数进行建模,其中theta1、theta2、theta3表示三个待估计参数,start设置了参数初始值,设定trace为真以显示迭代过程。nls函数默认采用Gauss-Newton方法寻找极值,迭代过程中第一列为RSS值,后面三列是各参数估计值。然后用summary返回回归结果。
library(car) pop.mod1 <- nls(population ~ theta1/(1+exp(-(theta2+theta3*year))),start=list(theta1 = 400, theta2 = -49, theta3 = 0.025), data=USPop, trace=T) summary(pop.mod)
还有一种更为简便的方法就是采用内置自启动模型(self-starting Models),此时我们只需要指定函数形式,而不需要指定参数初始值。本例的logistic函数所对应的selfstarting函数名为SSlogis
pop.mod2 <- nls(population ~ SSlogis(year,phi1,phi2,phi3),data=USPop)
二、判断拟合效果
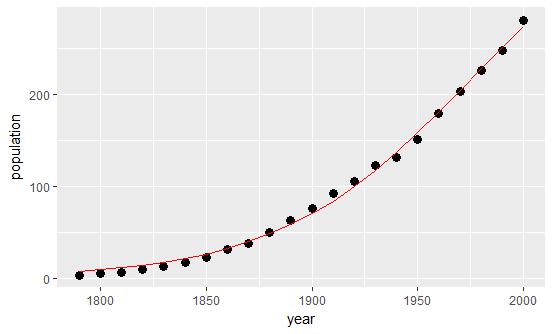
非线性回归模型建立后需要判断拟合效果,因为有时候参数最优化过程会捕捉到局部极值点而非全局极值点。最直观的方法是在原始数据点上绘制拟合曲线。
library(ggplot2) p <- ggplot(USPop,aes(year, population)) p+geom_point(size=3)+geom_line(aes(year,fitted(pop.mod1)),col=\'red\')
附注:关于fitted详细讲解转——一个不错的博客
若比较多个模型的拟合效果可使用AIC函数,取最小值为佳。(AIC是赤池系数用于比较模型的好坏,类似的BIC是贝叶斯系数)
三、残差诊断
为了检测这些假设是否成立我们用拟合模型的残差来代替误差进行判断。
plot(fitted(pop.mod1) , resid(pop.mod1),type=\'b\')
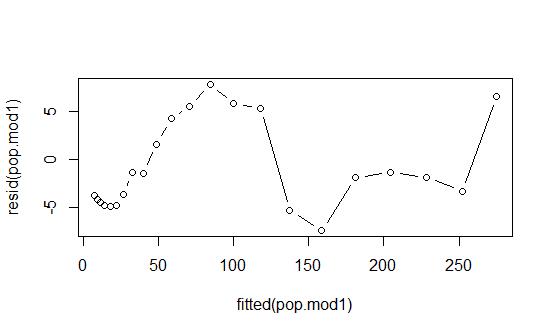
fitted是拟合值(predict是预测值) resid和residuals表示残差
四、函数模型的参数估计
关于函数估计至少有这么几个问题是需要关心的:
1、知道函数的一个大概的模型,需要估计函数的参数;
2、不知道模型,但想用一个不坏的模型刻画它;
3、不知道模型,不太关心其显式表达是什么,只想知道它在没观测到的点的取值。
这三个问题第一个是拟合或者叫参数估计,第二个叫函数逼近,第三个叫函数插值。从统计的角度来看,第一个是参数问题,剩下的是非参数的问题
以含常数项的指数函数为例
模拟模型( y=x^beta+mu +varepsilon ),这里假设( beta=3,mu=5.2 )
产生仿真数据
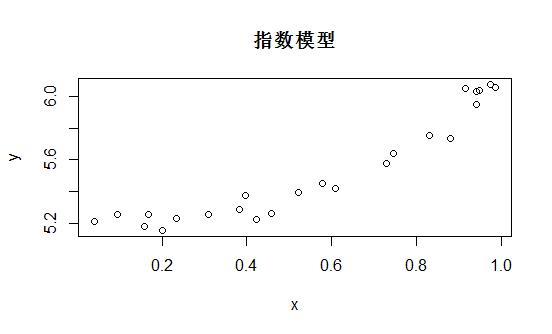
len <- 24 x <- runif(len) y <- x^3 + 5.2 + rnorm(len, 0, 0.06) ds <- data.frame(x = x, y = y) str(ds)
\'data.frame\': 24 obs. of 2 variables:
$ x: num 0.3961 0.2004 0.0407 0.9873 0.83 ...
$ y: num 5.37 5.15 5.21 6.06 5.75 ...
plot(y ~ x, main = "指数模型") s <- seq(0, 1, length = 100) lines(s, s^3, lty = 2, col = "red")
使用nls函数估计如下:
rhs <- function(x, b0, b1) {
b0 + x^b1
}
m.1 <- nls(y ~ rhs(x, intercept, power), data = ds, start = list(intercept = 0,
power = 2), trace = T)
回显如下:
629.9495 : 0 2
0.08918652 : 5.174334 2.526742
0.08346069 : 5.184992 2.786072
0.08303884 : 5.188992 2.870896
0.08301127 : 5.190252 2.894080
0.08300947 : 5.190594 2.900075
0.08300935 : 5.190683 2.901602
0.08300934 : 5.190705 2.901989
0.08300934 : 5.190711 2.902088
0.08300934 : 5.190713 2.902112
summary(m.1)
回显如下:
Formula: y ~ rhs(x, intercept, power)
Parameters:
Estimate Std. Error t value Pr(>|t|)
intercept 5.19071 0.02189 237.150 < 2e-16
power 2.90211 0.30825 9.415 3.58e-09
intercept ***
power ***
---
Signif. codes:
0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.06143 on 22 degrees of freedom
Number of iterations to convergence: 9
Achieved convergence tolerance: 4.296e-06
如果采用最小二乘估计方法,得到的结果是:
model <- lm(I(log(y)) ~ I(log(x))) summary(model)
回显如下:
Call:
lm(formula = I(log(y)) ~ I(log(x)))
Residuals:
Min 1Q Median 3Q Max
-0.054991 -0.029944 -0.008994 0.037530 0.073063
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.755422 0.011128 157.755 < 2e-16
I(log(x)) 0.055445 0.009502 5.835 7.17e-06
(Intercept) ***
I(log(x)) ***
---
Signif. codes:
0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.03851 on 22 degrees of freedom
Multiple R-squared: 0.6075, Adjusted R-squared: 0.5897
F-statistic: 34.05 on 1 and 22 DF, p-value: 7.166e-06
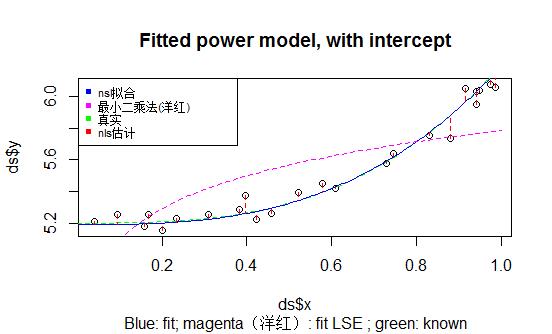
我们可以将估计数据、真实模型、nls估计模型、最小二乘模型得到的结果展示在下图中,来拟合好坏有个直观的判断:
plot(ds$y ~ ds$x, main = "Fitted power model, with intercept", sub = "Blue: fit; magenta(洋红): fit LSE ; green: known") lines(s, s^3 + 5.2, lty = 2, col = "green") lines(s, predict(m.2, list(x = s)), lty = 1, col = "blue") lines(s, exp(predict(model, list(x = s))), lty = 2, col = "magenta") segments(x, y, x, fitted(m.2), lty = 2, col = "red")
legend("topleft",c("nsl拟合","最小二乘法(洋红)","真实","nls估计"),col=c("blue","magenta","green","red"),pch=15:15,cex = 0.7)
以上是关于R语言用nls做非线性回归以及函数模型的参数估计的主要内容,如果未能解决你的问题,请参考以下文章
R语言广义线性模型函数GLMglm函数构建泊松回归模型(Poisson regression)输出提供偏差(deviances)回归参数和标准误差以及系数的显著性p值