朴素贝叶斯(Naive Bayes)及Python实现
Posted 肉鹅阿笨
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了朴素贝叶斯(Naive Bayes)及Python实现相关的知识,希望对你有一定的参考价值。
朴素贝叶斯(Naive Bayes)
1.模型
在GDA 中,我们要求特征向量 x 是连续实数向量。如果 x 是离散值的话,可以考虑采用朴素贝叶斯的分类方法。
以垃圾邮件分类为例子,采用最简单的特征描述方法,首先找一部英语词典,将里面的单词全部列出来。然后将每封邮件表示成一个向量,向量中每一维都是字典中的一个词的 0/1值,1 表示该词在邮件中出现,0 表示未出现。
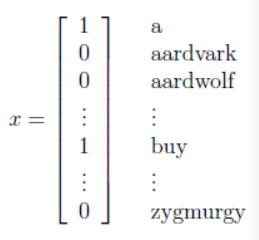
比如一封邮件中出现了“ a”和“ buy”,没有出现“ aardvark”、“ aardwolf”和“ zygmurgy”,
那么可以形式化表示为:
如果像GDA那么去建模的话,那么特征向量x是服从一个多项式分布,如果有5000个单词的话,那么x就有2^5000种可能,建模就需要2^5000-1个参数,参数太多。因此,需要在建模中改变假设,朴素贝叶斯模型不对特征向量x作出假设,而是对它的每个分量xi进行假设,并且假设各个分量之间独立。
朴素贝叶斯模型对特征向量x的各个分量xi和y有如下假设:

因此我们得到:
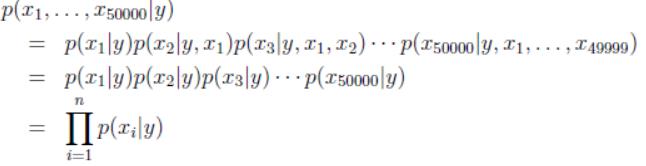
这里只需要5000个参数,远少于之前所需的参数个数。
2.评价
该模型的对数似然函数如下:

3.优化
对各个参数进行求导后令等式为0,得到:
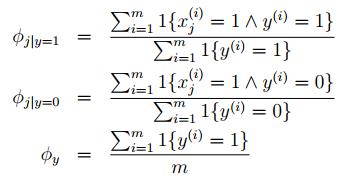
当然,朴素贝叶斯方法可以扩展到 x 和 y 都有多个离散值的情况。对于特征是连续值的情况,我们也可以采用分段的方法来将连续值转化为离散值,这时xi|y就是服从多项分布而不是伯努利分布了。具体怎么转化能够最优,我们可以采用信息增益的度量方法来确定。
以上是关于朴素贝叶斯(Naive Bayes)及Python实现的主要内容,如果未能解决你的问题,请参考以下文章
Spark MLlib速成宝典模型篇04朴素贝叶斯Naive Bayes(Python版)