RabbitMQ队列
Posted Talk is cheap
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了RabbitMQ队列相关的知识,希望对你有一定的参考价值。
RabbitMQ是什么?
RabbitMQ是一个在AMQP基础上完整的,可复用的企业消息系统。他遵循Mozilla Public License开源协议。
MQ全称为Message Queue, 消息队列(MQ)是一种应用程序对应用程序的通信方法。应用程序通过读写出入队列的消息(针对应用程序的数据)来通信,而无需专用连接来链接它们。消 息传递指的是程序之间通过在消息中发送数据进行通信,而不是通过直接调用彼此来通信,直接调用通常是用于诸如远程过程调用的技术。排队指的是应用程序通过 队列来通信。队列的使用除去了接收和发送应用程序同时执行的要求。
RabbitMQ的安装
首先说明,RabbitMQ在win上安装是一件颇为麻烦的事情。试了很长时间都没有成功,后来就转战linux了。在linux的安装中也可能会出现一点问题,下面会贴出一个网址有安装中出现问题的解决办法。
linux上都是直接install rabbitmq-server
当然可能会在安装中和后来的使用上出现这样或者是那样的问题,解决办法参见这篇博客http://www.cnblogs.com/kaituorensheng/p/4985767.html
RabbitMQ的语法以及实例
1.基本实例
基于Queue实现生产者消费者模型


1 import Queue 2 import threading 3 4 5 message = Queue.Queue(10) 6 7 8 def producer(i): 9 while True: 10 message.put(i) 11 12 13 def consumer(i): 14 while True: 15 msg = message.get() 16 17 18 for i in range(12): 19 t = threading.Thread(target=producer, args=(i,)) 20 t.start() 21 22 for i in range(10): 23 t = threading.Thread(target=consumer, args=(i,)) 24 t.start()
对于RabbitMQ来说,生产和消费不再针对内存里的一个Queue对象,而是某台服务器上的RabbitMQ Server实现的消息队列。
import pika connection = pika.BlockingConnection(pika.ConnectionParameters( host=\'localhost\')) channel = connection.channel()#开通一个管道 #声明queue channel.queue_declare(queue=\'hello\') channel.basic_publish(exchange=\'\', routing_key=\'hello\',#queue名字 body=\'Hello World!\')#消息内容 print(" [x] Sent \'Hello World!\'") connection.close()
import pika #建立连接 connection = pika.BlockingConnection(pika.ConnectionParameters( host=\'localhost\')) channel = connection.channel() channel.queue_declare(queue=\'hello\') def callback(ch, method, properties, body): print(" [x] Received %r" % body) channel.basic_consume(#消费消息 callback,#如果收到消息就调用callback函数处理消息 queue=\'hello\', no_ack=True) print(\' [*] Waiting for messages. To exit press CTRL+C\') channel.start_consuming()
2.消息发布轮询
- 上面的只是一个生产者、一个消费者,能不能一个生产者多个消费者呢?
可以上面的例子,多启动几个消费者consumer,看一下消息的接收情况。
采用轮询机制;把消息依次分发
- 假如消费者处理消息需要15秒,如果当机了,那这个消息处理明显还没处理完,怎么处理?
(可以模拟消费端断了,分别注释和不注释 no_ack=True 看一下)
你没给我回复确认,就代表消息没处理完。
- 上面的效果消费端断了就转到另外一个消费端去了,但是生产者怎么知道消费端断了呢?
因为生产者和消费者是通过socket连接的,socket断了,就说明消费端断开了。
- 上面的模式只是依次分发,实际情况是机器配置不一样。怎么设置类似权重的操作?
RabbitMQ怎么办呢,RabbitMQ做了简单的处理就能实现公平的分发。
就是RabbitMQ给消费者发消息的时候检测下消费者里的消息数量,如果超过指定值(比如1条),就不给你发了。
只需要在消费者端,channel.basic_consume前加上就可以了。
channel.basic_qos(prefetch_count=1) # 类似权重,按能力分发,如果有一个消息,就不在给你发
3. acknowledgment 消息持久化
no-ack = False
如果消费者遇到情况(its channel is closed, connection is closed, or TCP connection is lost)挂掉了,那么,RabbitMQ会重新将该任务添加到队列中。
import pika connection = pika.BlockingConnection(pika.ConnectionParameters( host=\'localhost\')) channel = connection.channel() channel.queue_declare(queue=\'hello\') def callback(ch, method, properties, body): print(" [x] Received %r" % body) import time time.sleep(10) print (\'ok\') ch.basic_ack(delivery_tag = method.delivery_tag) channel.basic_consume(callback, queue=\'hello\', no_ack=False) print(\' [*] Waiting for messages. To exit press CTRL+C\') channel.start_consuming()
durable
如果队列里还有消息,RabbitMQ 服务端宕机了呢?消息还在不在?
把RabbitMQ服务重启,看一下消息在不在。
上面的情况下,宕机了,消息就久了,下面看看如何把消息持久化。
每次声明队列的时候,都加上durable,注意每个队列都得写,客户端、服务端声明的时候都得写。
# 在管道里声明queue channel.queue_declare(queue=\'hello2\', durable=True)
durable的作用只是把队列持久化。离消息持久话还差一步:
发送端发送消息时,加上properties
properties=pika.BasicProperties( delivery_mode=2, # 消息持久化 )
#!/usr/bin/env python # -*- coding:utf-8 -*- import pika connection = pika.BlockingConnection(pika.ConnectionParameters(host=\'10.211.55.4\')) channel = connection.channel() # make message persistent channel.queue_declare(queue=\'hello\', durable=True) def callback(ch, method, properties, body): print(" [x] Received %r" % body) import time time.sleep(10) print \'ok\' ch.basic_ack(delivery_tag = method.delivery_tag) channel.basic_consume(callback, queue=\'hello\', no_ack=False) print(\' [*] Waiting for messages. To exit press CTRL+C\') channel.start_consuming() 消费者
import pika connection = pika.BlockingConnection(pika.ConnectionParameters(host=\'10.211.55.4\')) channel = connection.channel() # make message persistent channel.queue_declare(queue=\'hello\', durable=True) def callback(ch, method, properties, body): print(" [x] Received %r" % body) import time time.sleep(10) print( \'ok\') ch.basic_ack(delivery_tag = method.delivery_tag) channel.basic_consume(callback, queue=\'hello\', no_ack=False) print(\' [*] Waiting for messages. To exit press CTRL+C\') channel.start_consuming()
4.消息获取顺序
默认消息队列里的数据是按照顺序被消费者拿走,例如:消费者1 去队列中获取 奇数 序列的任务,消费者2去队列中获取 偶数 序列的任务。
channel.basic_qos(prefetch_count=1) 表示谁来谁取,不再按照奇偶数排列
1 #Auther: Xiaoliuer Li 2 3 import pika 4 5 connection = pika.BlockingConnection(pika.ConnectionParameters(host=\'localhost\')) 6 channel = connection.channel() 7 8 # make message persistent 9 channel.queue_declare(queue=\'hello\') 10 11 12 def callback(ch, method, properties, body): 13 print(" [x] Received %r" % body) 14 import time 15 time.sleep(10) 16 print (\'ok\') 17 ch.basic_ack(delivery_tag = method.delivery_tag) 18 19 channel.basic_qos(prefetch_count=1) 20 21 channel.basic_consume(callback, 22 queue=\'hello\', 23 no_ack=False) 24 25 print(\' [*] Waiting for messages. To exit press CTRL+C\') 26 channel.start_consuming()
5.发布订阅(广播模式)
前面的效果都是一对一发,如果做一个广播效果可不可以,这时候就要用到exchange了
exchange必须精确的知道收到的消息要发给谁。exchange的类型决定了怎么处理,
类型有以下几种:
- fanout: 所有绑定到此exchange的queue都可以接收消息
- direct: 通过routingKey和exchange决定的那个唯一的queue可以接收消息
- topic: 所有符合routingKey(此时可以是一个表达式)的routingKey所bind的queue可以接收消息
fanout 纯广播、all
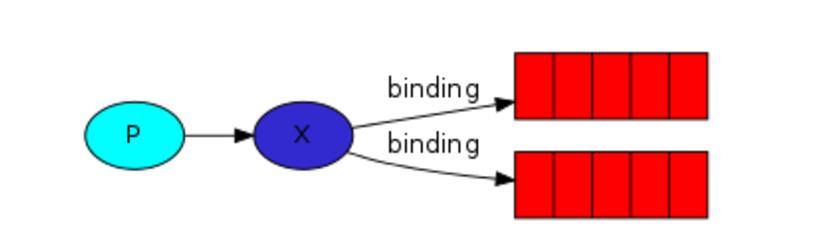
发布订阅和简单的消息队列区别在于,发布订阅会将消息发送给所有的订阅者,而消息队列中的数据被消费一次便消失。所以,RabbitMQ实现发布和订阅时,会为每一个订阅者创建一个队列,而发布者发布消息时,会将消息放置在所有相关队列中。
import pika import sys connection = pika.BlockingConnection(pika.ConnectionParameters( host=\'localhost\')) channel = connection.channel() channel.exchange_declare(exchange=\'logs\', type=\'fanout\') message = \' \'.join(sys.argv[1:]) or "info: Hello World!" channel.basic_publish(exchange=\'logs\', routing_key=\'\', body=message) print(" [x] Sent %r" % message) connection.close()
import pika connection = pika.BlockingConnection(pika.ConnectionParameters( host=\'localhost\')) channel = connection.channel() channel.exchange_declare(exchange=\'logs\', type=\'fanout\') result = channel.queue_declare(exclusive=True) queue_name = result.method.queue channel.queue_bind(exchange=\'logs\', queue=queue_name) print(\' [*] Waiting for logs. To exit press CTRL+C\') def callback(ch, method, properties, body): print(" [x] %r" % body) channel.basic_consume(callback, queue=queue_name, no_ack=True) channel.start_consuming()
注意:广播,是实时的,收不到就没了,消息不会存下来,类似收音机。
direct 有选择的接收消息
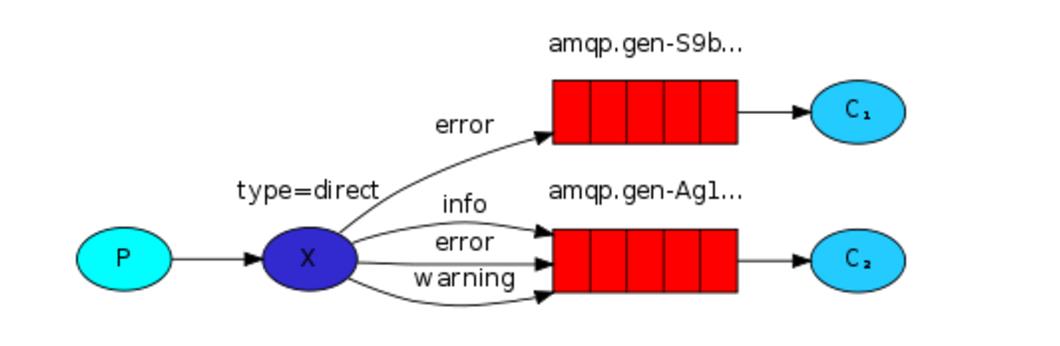
之前事例,发送消息时明确指定某个队列并向其中发送消息,RabbitMQ还支持根据关键字发送,即:队列绑定关键字,发送者将数据根据关键字发送到消息exchange,exchange根据 关键字 判定应该将数据发送至指定队列。
import pika import sys connection = pika.BlockingConnection(pika.ConnectionParameters( host=\'localhost\')) channel = connection.channel() channel.exchange_declare(exchange=\'direct_logs\', type=\'direct\') severity = sys.argv[1] if len(sys.argv) > 1 else \'info\' message = \' \'.join(sys.argv[2:]) or \'Hello World!\' channel.basic_publish(exchange=\'direct_logs\', routing_key=severity, body=message) print(" [x] Sent %r:%r" % (severity, message)) connection.close()
import pika import sys connection = pika.BlockingConnection(pika.ConnectionParameters( host=\'localhost\')) channel = connection.channel() channel.exchange_declare(exchange=\'direct_logs\', type=\'direct\') result = channel.queue_declare(exclusive=True) queue_name = result.method.queue # 获取运行脚本所有的参数 severities = sys.argv[1:] if not severities: sys.stderr.write("Usage: %s [info] [warning] [error]\\n" % sys.argv[0]) sys.exit(1) # 循环列表去绑定 for severity in severities: channel.queue_bind(exchange=\'direct_logs\', queue=queue_name, routing_key=severity) print(\' [*] Waiting for logs. To exit press CTRL+C\') def callback(ch, method, properties, body): print(" [x] %r:%r" % (method.routing_key, body)) channel.basic_consume(callback, queue=queue_name, no_ack=True) channel.start_consuming()
运行接收端,指定接收级别的参数,例:
python direct_sonsumer.py info warning
python direct_sonsumer.py warning error
topic 更细致的过滤
在topic类型下,可以让队列绑定几个模糊的关键字,之后发送者将数据发送到exchange,exchange将传入”路由值“和 ”关键字“进行匹配,匹配成功,则将数据发送到指定队列。
- # 表示可以匹配 0 个 或 多个 单词
- * 表示只能匹配 一个 单词
发送者路由值 队列中 old.boy.python old.* -- 不匹配 old.boy.python old.# -- 匹配
import pika import sys connection = pika.BlockingConnection(pika.ConnectionParameters( host=\'localhost\')) channel = connection.channel() channel.exchange_declare(exchange=\'topic_logs\', type=\'topic\') routing_key = sys.argv[1] if len(sys.argv) > 1 else \'anonymous.info\' message = \' \'.join(sys.argv[2:]) or \'Hello World!\' channel.basic_publish(exchange=\'topic_logs\', routing_key=routing_key, body=message) print(" [x] Sent %r:%r" % (routing_key, message)) connection.close()
import pika import sys connection = pika.BlockingConnection(pika.ConnectionParameters( host=\'localhost\')) channel = connection.channel() channel.exchange_declare(exchange=\'topic_logs\', type=\'topic\') routing_key = sys.argv[1] if len(sys.argv) > 1 else \'anonymous.info\' message = \' \'.join(sys.argv[2:]) or \'Hello World!\' channel.basic_publish(exchange=\'topic_logs\', routing_key=routing_key, body=message) print(" [x] Sent %r:%r" % (routing_key, message)) connection.close()
注意:
sudo rabbitmqctl add_user alex 123 # 设置用户为administrator角色 sudo rabbitmqctl set_user_tags alex administrator # 设置权限 sudo rabbitmqctl set_permissions -p "/" alex \'.\'\'.\'\'.\' # 然后重启rabbiMQ服务 sudo /etc/init.d/rabbitmq-server restart # 然后可以使用刚才的用户远程连接rabbitmq server了。 ------------------------------ credentials = pika.PlainCredentials("alex","123") connection = pika.BlockingConnection(pika.ConnectionParameters(\'192.168.14.47\',credentials=credentials))
6.RabbitMQ RPC 实现(Remote procedure call)
不知道你有没有发现,上面的流都是单向的,如果远程的机器执行完返回结果,就实现不了了。
如果返回,这种模式叫什么呢,RPC(远程过程调用),snmp就是典型的RPC
RabbitMQ能不能返回呢,怎么返回呢?既是发送端又是接收端。
但是接收端返回消息怎么返回?可以发送到发过来的queue里么?不可以。
返回时,再建立一个queue,把结果发送新的queue里
为了服务端返回的queue不写死,在客户端给服务端发指令的的时候,同时带一条消息说,你结果返回给哪个queue
import pika import uuid import time class FibonacciRpcClient(object): def __init__(self): self.connection = pika.BlockingConnection(pika.ConnectionParameters( host=\'localhost\')) self.channel = self.connection.channel() result = self.channel.queue_declare(exclusive=True) self.callback_queue = result.method.queue self.channel.basic_consume(self.on_response, # 只要一收到消息就调用on_response no_ack=True, queue=self.callback_queue) # 收这个queue的消息 def on_response(self, ch, method, props, body): # 必须四个参数 # 如果收到的ID和本机生成的相同,则返回的结果就是我想要的指令返回的结果 if self.corr_id == props.correlation_id: self.response = body def call(self, n): self.response = None # 初始self.response为None self.corr_id = str(uuid.uuid4()) # 随机唯一字符串 self.channel.basic_publish( exchange=\'\', routing_key=\'rpc_queue\', # 发消息到rpc_queue properties=pika.BasicProperties( # 消息持久化 reply_to = self.callback_queue, # 让服务端命令结果返回到callback_queue correlation_id = self.corr_id, # 把随机uuid同时发给服务器 ), body=str(n) ) while self.response is None: # 当没有数据,就一直循环 # 启动后,on_response函数接到消息,self.response 值就不为空了 self.connection.process_data_events() # 非阻塞版的start_consuming() # print("no msg……") # time.sleep(0.5) # 收到消息就调用on_response return int(self.response) if __name__ == \'__main__\': fibonacci_rpc = FibonacciRpcClient() print(" [x] Requesting fib(7)") response = fibonacci_rpc.call(7) print(" [.] Got %r" % response)
import pika import time def fib(n): if n == 0: return 0 elif n == 1: return 1 else: return fib(n-1) + fib(n-2) def on_request(ch, method, props, body): n = int(body) print(" [.] fib(%s)" % n) response = fib(n) ch.basic_publish( exchange=\'\', # 把执行结果发回给客户端 routing_key=props.reply_to, # 客户端要求返回想用的queue # 返回客户端发过来的correction_id 为了让客户端验证消息一致性 properties=pika.BasicProperties(correlation_id = props.correlation_id), body=str(response) ) ch.basic_ack(delivery_tag = method.delivery_tag) # 任务完成,告诉客户端 if __name__ == \'__main__\': connection = pika.BlockingConnection(pika.ConnectionParameters( host=\'localhost\')) channel = connection.channel() channel.queue_declare(queue=\'rpc_queue\') # 声明一个rpc_queue , channel.basic_qos(prefetch_count=1) # 在rpc_queue里收消息,收到消息就调用on_request channel.basic_consume(on_request, queue=\'rpc_queue\') print(" [x] Awaiting RPC requests") channel.start_consuming()
以上是关于RabbitMQ队列的主要内容,如果未能解决你的问题,请参考以下文章