R语言:有关差异分析的检验方法
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R语言:有关差异分析的检验方法相关的知识,希望对你有一定的参考价值。
参考技术A1 读取,计算均值,箱图观察
2 查看数据分布
2.1 hist直方图
2.2 qqnorm散点图
3 Shapiro-Wilk正态性检验
4 方差齐性检验
意义:方差分析就是在大家误差水平差不多的条件下看控制和对照组是不是有显著差异。那方差其实就是误差水平了。当方差不一致的时候,这个方法就没法分辨出究竟是控制造成的差异还是,内在的波动造成的差异。
参考: https://www.zhihu.com/question/21195390
参考: https://blog.csdn.net/tiaaaaa/article/details/58130363
4.1 F检验
使用条件:数据正态分布,只可以检验两个样本
4.2 bartlett检验
使用条件:正态分布的数据,多个样本
4.3 levene检验
没有条件:数据可不具正态性,可以检验多个总体的方差齐性
SPSS的默认方差齐性检验方法
5 差异检验
5.1 参数检验:T检验
使用条件:两样本来自正太分布总体,方差齐
5.2 非参数检验:Wilcoxon秩和检验(两样本)
参数:
参考: https://www.jianshu.com/p/f30d1fe877ea
5.3 非参数检验:Kruskal-Wallis(KS)秩和检验(多样本)
5.4 Deseq两组reads count差异分析
R语言 | 差异显著性检验
差异显著性检验是我们在分析数据的时候应用最多的统计学方法。
我们经常要比较两组或多组数据是否具有显著差异,同时我们还会用差异显著性检验识别不同组样品中具有显著差异的变量。
这篇推文会分别介绍经常使用的差异显著性检验方法在R语言中的实现。
方法选择
差异显著性检验具有多种方法,分别针对不同的情况,我们要根据自身情况选择合适的方法进行分析。
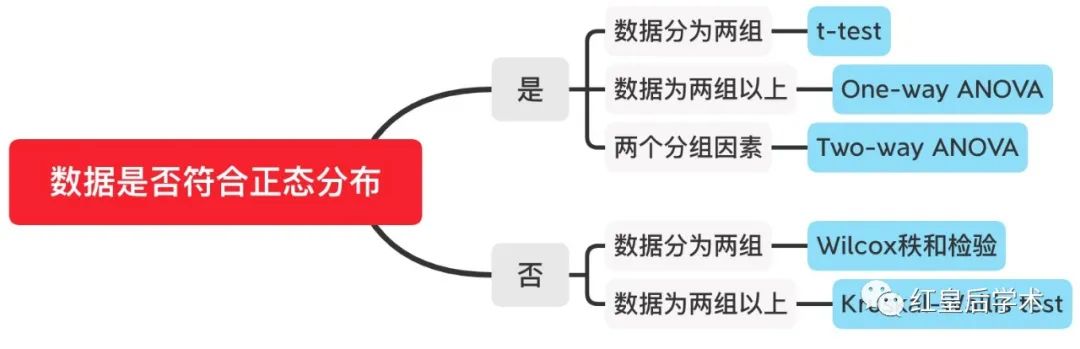
⚠️以上方法均为比较不同组数据见均值的差异显著性。
正态分布检验
可以看出在进行差异显著性检验之前,最重要的一步就是要评估数据是否符合正态分布。
QQ图
我们可以使用QQ图的方法来评估数据是否符合或接近正态分布。
QQ图是由观测值与按正态分布的预期值做出来的散点图,散点图组成的回归线越接近于标准线,表示实际观测数据越接近正态分布。
QQ图使用qqnorm和qqline两个函数完成,其参数比较简单,基本不需要修改和调整。
qqnorm(y, ylim, main = "Normal Q-Q Plot",
xlab = "Theoretical Quantiles", ylab = "Sample Quantiles",
plot.it = TRUE, datax = FALSE, ...)各参数意义:
y为待分析数据;
ylim为y轴范围;
main为图像标题;
xlab和ylab为x和y轴标签;
plot.it是否要绘图;
datax是否数据值为x轴数据。
qqline(y, datax = FALSE, distribution = qnorm,
probs = c(0.25, 0.75), qtype = 7, ...)各参数意义:
y为待分析数据;
datax是否数据值为x轴数据;
distribution定义数据的参考理论分布;
probs为两个数字的向量,代表可能性;
qtype定义用于计算的分位数的类型。
使用一组随机数据绘制一个QQ图的示例。
x <- rnorm(10)
qqnorm(x)
qqline(x)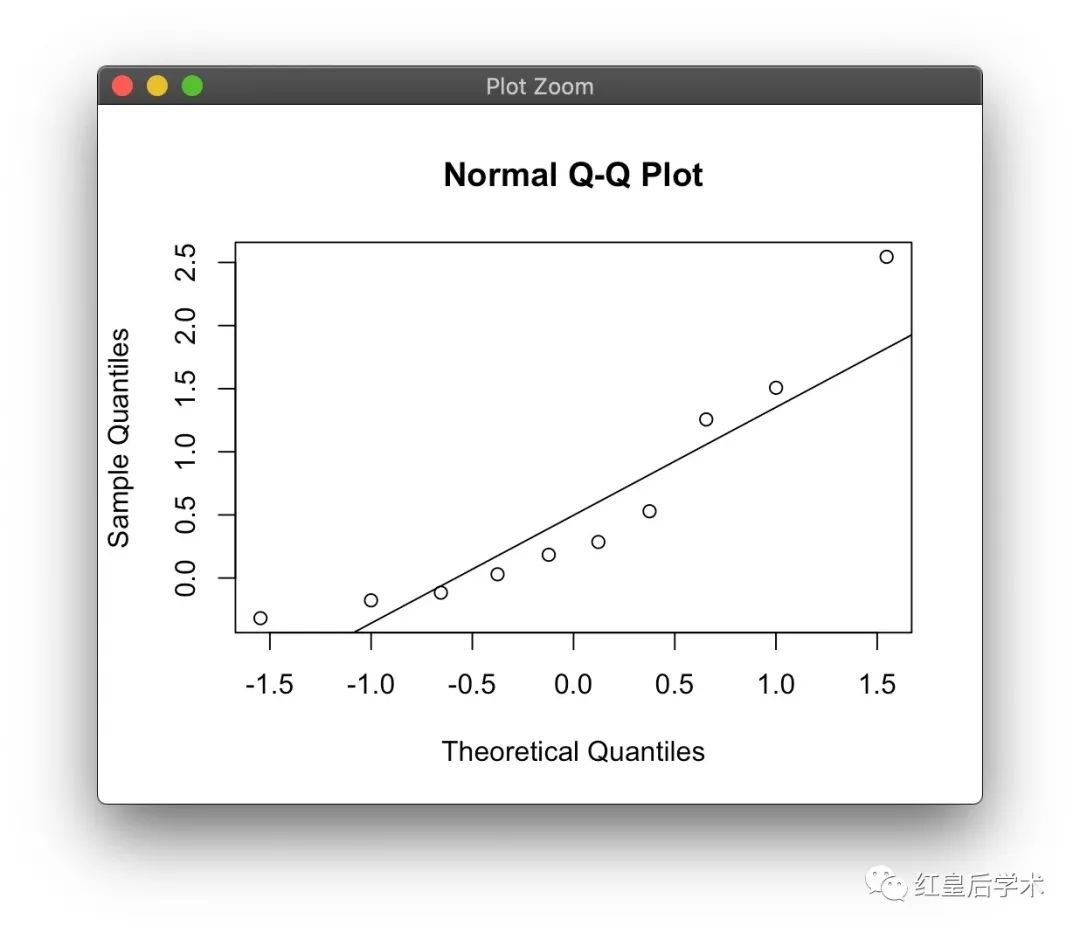
shapiro.test
虽然QQ图可以用于评估数据是否符合正态分布,但是其并没有确定的标准,因而在使用时会有一定的限制。
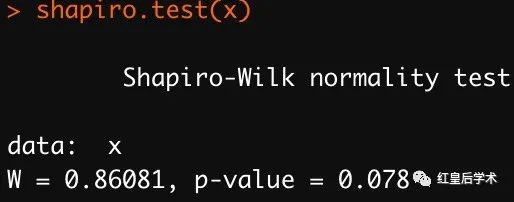
我们还可以使用shapiro.test函数来判断数据是否符合正态分布。
shapiro.test的零假设是变量符合正态分布,当结果的p-value > 0.05时,不能拒绝原假设,表明变量服从正态分布。
两组样本差异比较
确定数据是否符合正态分布之后,就可以对其进行组间差异显著性比较了。
t-test
当数据分为两组并且两组数据均符合正态分布时,使用t-test进行差异显著性比较,该分析由t.test函数完成。
t.test(x, y = NULL,
alternative = c("two.sided", "less", "greater"),
mu = 0, paired = FALSE, var.equal = FALSE,
conf.level = 0.95, ...)各参数意义:
x和y为待分析数据;
alternative规定检测的类型;
mu为原假设,即定义两组数据均值的假设差异;
paired是否进行配对检验;
var.equal定义是否检测两组方差的一致性;
conf.level为显著性等级。
⚠️t.test默认使用的是Welch t-test,该方法不要求比较数据方差齐性。
如果想要使用要求数据方法齐性的Student‘s t-test,需要把var.equal设置为TRUE。
方差齐性检验
方差齐性应用F-test进行检验,该分析由var.test函数完成。
var.test(x, y, ratio = 1,
alternative = c("two.sided", "less", "greater"),
conf.level = 0.95, ...)各参数意义:
x为因变量数据;
y为响应变量数据;
ratio定义x和y方差的比值;
alternative定义检验的类型;
conf.level为置信水平。
t-test示例
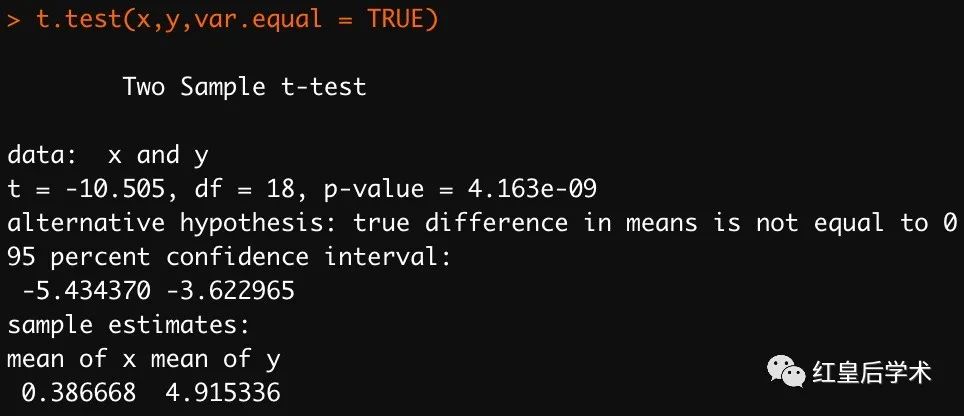
随机生成两个向量数据进行t-test。
x<- rnorm(10)
y <- rnorm(10,mean = 5)检验两组数据方差是否齐性,p-value > 0.05表示两组数据方差齐性。

进行t-test,p-value < 0.05表示两组数据的均值具有显著差异。
当两组数据数量一致并且具有匹配关系时,可以进行配对t-test。
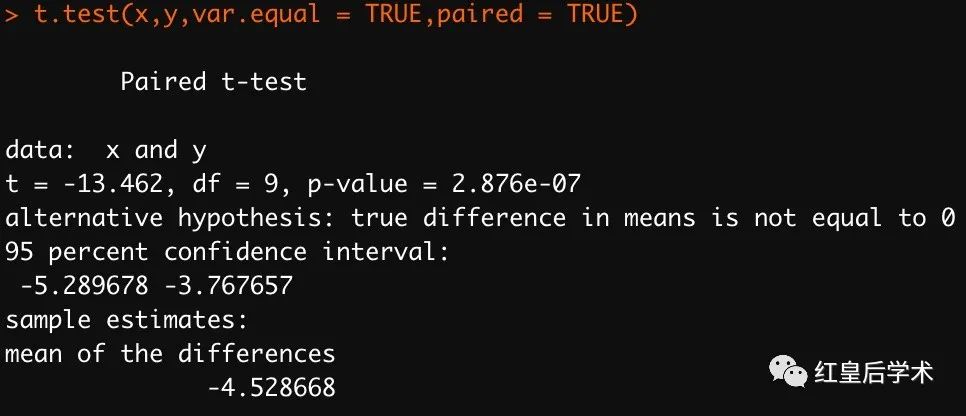
有时我们面对的是长数据,也就是在数据框中,一列代表需要分析的数据,而另一个因子列代表分组信息,此时可以使用公式的方式进行差异显著性检验。
以mtcars数据为例,数据中的vs列包含0和1两种分组,我们比较数据框中mpg数值在这两组中的差异。
data(mtcars)
mtcars$vs <- as.factor(mtcars$vs)
t.test(mpg~vs,data = mtcars)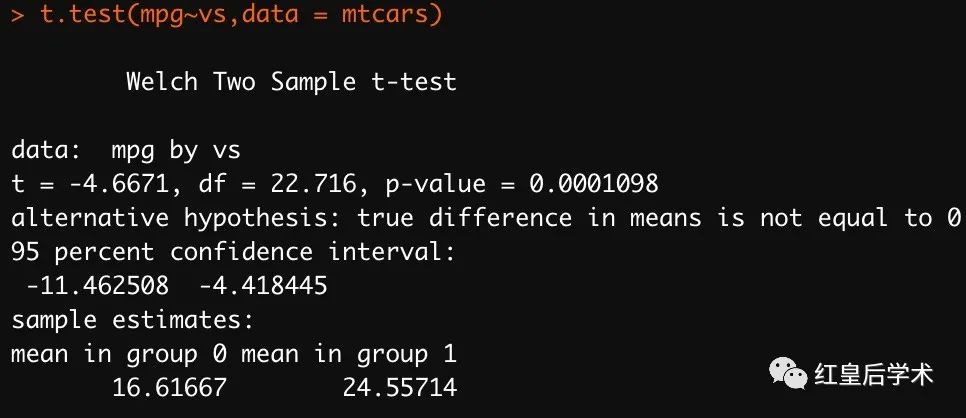
⚠️使用公式的时候,待分析的数据在~之前,分组列在~之后。
⚠️在进行分析之前一定要将分组列设为factor。
wilcox秩和检验
当分析的数据不符合正态分布并且分组为两组时,使用wilcox秩和检验来判断两组数据的均值是否具有显著差异,该分析由wilcox.test函数完成。
wilcox.test(x, y = NULL,
alternative = c("two.sided", "less", "greater"),
mu = 0, paired = FALSE, exact = NULL, correct = TRUE,
conf.int = FALSE, conf.level = 0.95,
tol.root = 1e-4, digits.rank = Inf, ...)各参数意义:
x和y为进行分析的数据;
alternative定义检验的类型;
paired定义是否进行配对检验;
exact定义是否生成exact的p-value;
correct定义是否对p-value进行连续型校正;
conf.int定义是否计算置信区间;
conf.level定义置信区间的置信水平。
wilcox.test函数的使用方法与t.test基本上一致,只是由于属于不符合正态分布,因此无需检验两组数据的方差时候齐性。
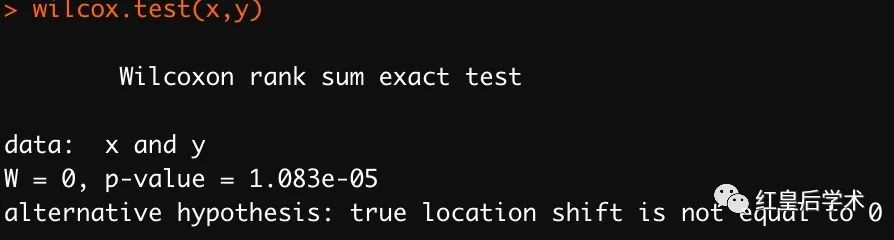
与t-test一样,wilcox秩和检验结果中p-value < 0.05代表两组数据的均值具有显著差异。
当面对长数据时,同样可以使用公式的方式进行分析。
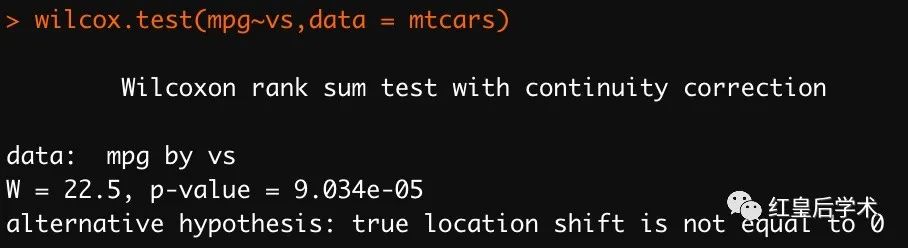
多个变量的批量检验
上面介绍的都是基本的使用方法,只能一个变量一个变量的进行差异检验,但大多数时候我们可能需要检验很多个变量的差异,此时我们只需要写一个简单的循环就可以了。
这里以以iris的前100行数据为例,其被最后一列Species分为两组。
data("iris")
data <- iris[1:100,]
M <- colnames(data)[1:ncol(data)-1]
test <- c()for (i in M) {
fit1 <- t.test(as.formula(sprintf("%s ~ Species",i)),
data = data)
test <- cbind(test,fit1$p.value)
}
test <- data.frame(var = M,p.value = t(test))得到的test就是每个变量的差异性检验结果。
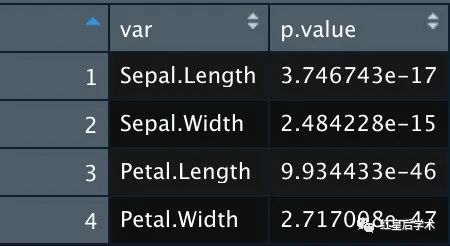
⚠️分组列要放在数据框的最后一列。
⚠️注意在对自己的数据使用的时候要将循环公式中的Species替换为自己的分组列的列名。
多组样本差异比较
有时我们面对的数据在的分组在两组以上,此时使用t-test或Wilcox秩和检验就并不合适了,需要用到方差分析。
One-way ANOVA
当分析数据符合正态分布并且分组在3组及以上时,需要用One-way ANOVA来检验各组间数据差异的显著性,该分析通过aov函数完成。
不同于t-test和秩和检验,由于ANOVA中分组超过了两组,因此该分析所需数据必须为数据框形式,数据框的其中一列为待分析数据,另外还需要有一个因子列作为分组信息。
aov(formula, data = NULL, projections = FALSE, qr = TRUE, contrasts = NULL, ...)各参数意义:
formula为进行分析的公式;
data为进行分析的数据;
projections定义是否要返回投影;
qr是否要返回QR分解结果。
⚠️ANOVA的分析必须以公式形式完成,公式中~前为待分析数据,~后为分组数据。
以iris数据为例进行分析。
data("iris")
fit <- aov(Sepal.Length~Species,data = iris)
summary(fit)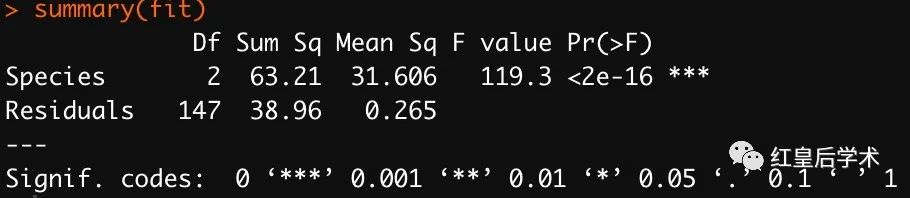
结果中如果Pr(>F)的值小于0.05,则表明不同组数据间存在显著的差异。
组间两两比较
在多组数据比较时,我们除了希望得到整体的差异显著性之外,更多的时候还需要获取不同组两两之间比较的差异显著性。
针对One-way ANOVA的检测,可以使用TukeyHSD和pairwise.t.test函数进行后续的组间两两差异性比较。
TukeyHSD使用比较简单,只需要对aov函数的结果使用该函数即可。
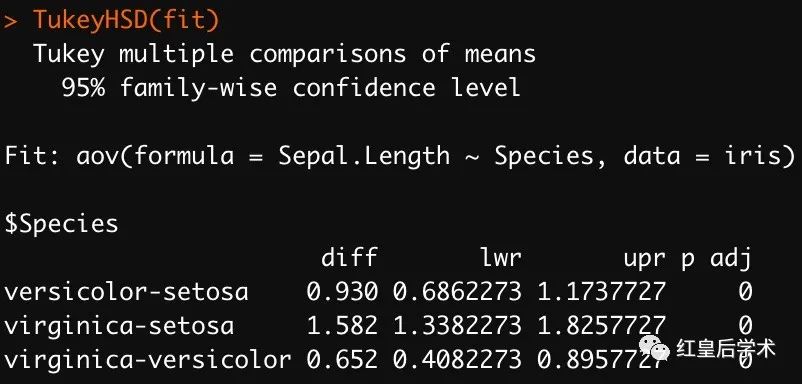
结果中p adj的值即为不同组数据量量比较的显著性结果。
pairwise.t.test需要直接调用分析数据进行检验。
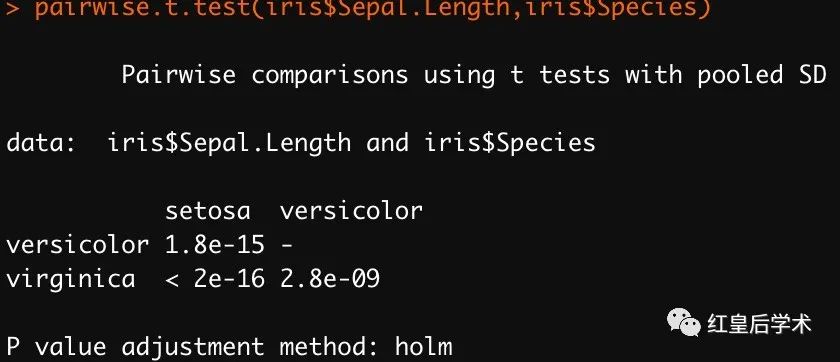
该函数得到的结果是不同组数据两两比较显著性p-value的矩阵。
Kruskal-Wallis test
当分析数据不符合正态分布并且分组在3组及以上时,需要用Kruskal-Wallis test来检验各组间数据差异的显著性,该分析通过kruskal.test函数完成。
该函数的使用方式与aov完全一致,但是该函数的结果是直接显示不需要使用summary函数。
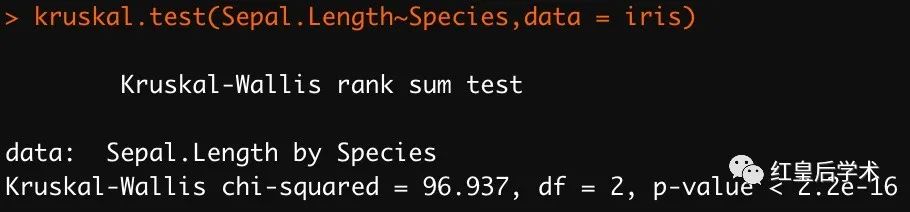
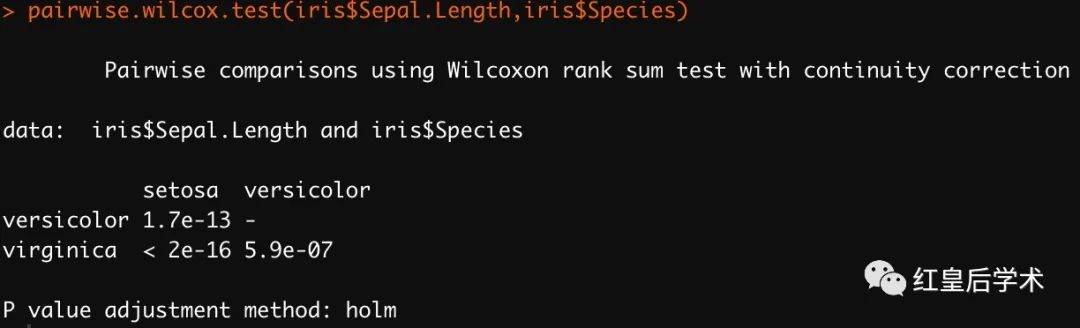
组间两两比较
对于使用Kruskal-Wallis test的数据进行不同组间两两比较时,使用pairwise.wilcox.test函数。
多个变量的批量检验
对于One-way ANOVA和Krusal-Wallis test的多个变量批量检验,其方法与上文提到的t-test和秩和检验一致,只需将上文循环脚本中对应的函数进行替换即可。
对于组间两两比较的批量操作和结果提取,在之前的推文中有过使用,。
两种分组方式
Two-way ANOVA
当数据符合正态分布并且有两种不同的分组方式时,需要使用Two-way ANOVA来检验变量在不同组间是否具有显著差异。
与One-way ANOVA一样,Two-way ANOVA同样使用aov函数完成。
与One-way ANOVA不同的是,Two-way ANOVA有两种分组方式,因此需要在公式的~之后添加两个分组。
使用mtcars数据为例进行Two-way ANOVA分析。
data("mtcars")
fit <- aov(mpg~cyl*vs,data = mtcars)
summary(fit)⚠️在~后的两个分组变量要用星号连接。
以上是关于R语言:有关差异分析的检验方法的主要内容,如果未能解决你的问题,请参考以下文章
R语言Kruskal-Wallis检验以及Dunn’s检验实战:Kruskal-Wallis检验是单因素方差分析的非参数等价方法Dunn’s检验以确定哪些组的中位数是有确定的统计差异的