电脑里突然产生大量heapdump.和javacore.的文本文件,应该怎么处理?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了电脑里突然产生大量heapdump.和javacore.的文本文件,应该怎么处理?相关的知识,希望对你有一定的参考价值。
今天在电脑桌面上发现大量的heapdump.和javacore.的文本文件,貌似很多很多,里面没什么内容,也不知道可不可以删除,删除是不是解决问题……
在百度里查找了一下,似乎这是一个比较严重的系统问题,会导致什么的崩溃……我不怎么懂得电脑的操作系统啊,那些别人建议的处理方法看不懂,而且也不知道可不可以那样处理……
各位可否用稍微通俗的语言解释一下问题的产生原因和处理办法?
电脑还可以上网,其他的功能是否受影响还不知道……
如果问题解决了,积分还会追加的!
谢谢各位啦!
可否具体告知操作办法,浅显一点的,我不知道什么是was管理控制台呢!
放到回收站再删除可以吗?置之不理呢?会有影响吗?
ibm网站上有不少关于这个问题的信息。
根据我的经验,解决这个问题的方法为:
1.进入was管理控制台,选择 应用程序服务器 > server1 > 进程定义 > Java 虚拟机,将"最大堆大小"改为768或1024以上(跟机器内存相关,你的机器最好有较大内存)。保存。
2.优化你的程序,减少要求分配较大内存的设计,优化数据连接池。
3.给was打补丁。ibm网站上有相关补丁下载,不过最好升级到同系列的最新版本
前两步多数可以改善websphere的运行情况,但最好执行第三步。
一般这个问题也与操作系统有关,要彻底解决,还得综合分析 参考技术A 这个问题在websphere上并不少见,简单来说,就是出现过多内存泄漏,或者分配过多大内存等,websphere的垃圾回收功能失败而导致。除了产生heapdump****.txt,还会产生javacore***.txt,偶尔产生Core文件。heapdump期间,websphere失去响应,过后,websphere可能恢复正常,也可能崩溃。
ibm网站上有不少关于这个问题的信息。
根据我的经验,解决这个问题的方法为:
1.进入was管理控制台,选择 应用程序服务器 > server1 > 进程定义 > Java 虚拟机,将"最大堆大小"改为768或1024以上(跟机器内存相关,你的机器最好有较大内存)。保存。
2.优化你的程序,减少要求分配较大内存的设计,优化数据连接池。
3.给was打补丁。ibm网站上有相关补丁下载,不过最好升级到同系列的最新版本
前两步多数可以改善websphere的运行情况,但最好执行第三步。
一般这个问题也与操作系统有关,要彻底解决,还得综合分析. 参考技术B 如果你装杀毒软件,那么进行杀毒,如果还不可以,那么就只有重装系统了。 参考技术C 可以置之不理吧!我的电脑也是这样,不过没管,倒也没事……本回答被提问者采纳 参考技术D 重装好了,但如果现在系统一切正常的话你就不要管了.
性能分析之如何高效解决 SQL 产生的内存溢出
一、问题现象
今天在测试环境有过代码升级。升级后,在群里有人反映系统访问很慢。运维人员反映服务器 CPU 使用率很高。
运维重启后,没有多久,又有人反映系统访问很慢,这时运维人员说有大量的 Full GC 产生。
二、全局监控
先 TOP 一下,发现单 cpu %us一直处于 100%
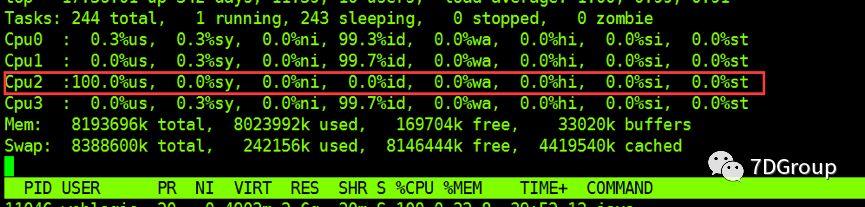
在执行 TOP 时,要习惯性的点下1,这样才能看到每个 CPU 的使用率,如果不点,则看到的是所有 CPU 的平均值,像这样单 CPU 高的情况就会被平均掉,会有遗漏。
通过全局监控,发现是 PID 为 7313 的 Java 进程消耗 CPU 比较厉害。
扩展知识:
三、定向监控
1、分析GC
实时查看 GC 状态:
jstat -gcutil 7313 1000
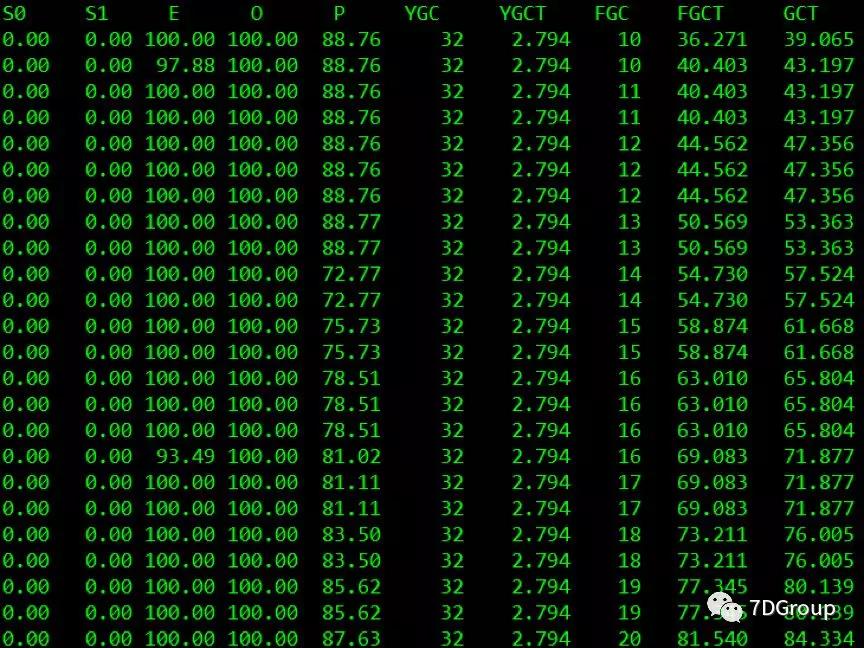
从上图来看,JVM 一直在频繁的 FGC。新生代内存爆满。老年代内存爆满!怎么回事?难道是不断创建大对象,一直回收不了?
从单 CPU 高到查看 JVM 的 GC,是考虑到对于串行 FGC 来说,会导致单 CPU 高的情况。
扩展知识:
2、分析应用日志
接着查看后台日志,出现大量的 SQL 相关报错:

因为日志中有堆栈信息,和 SQL 相关,并且 jstat 中看到 heap 也已经满了,所以接下来就要查看 heapdump。
3、Heap dump 分析
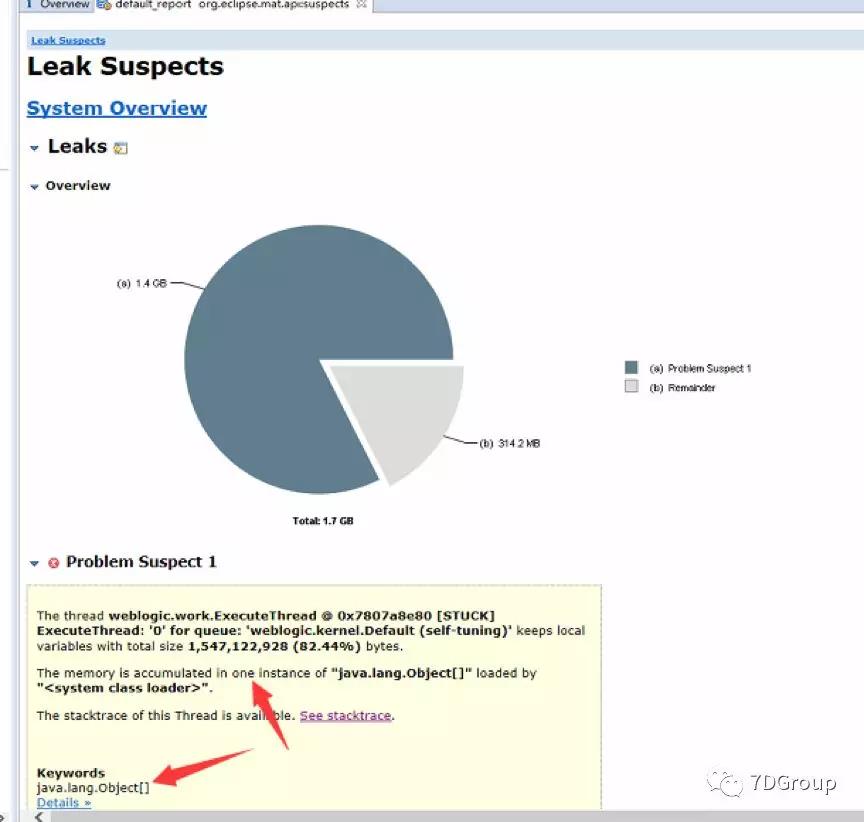
打印相关进程的 heap dump。开始借助 MAT 工具进行分析。
命令:
jmap-dump:format=b,file=test.hprof 7313
发现 ExecuteThread: '0' for queue: 'weblogic.kernel.Default(self-tuning)'占用内存 1.4 G,总的内存才 1.7 G
根据可疑的问题点,查看一下 Threadstack:

这里主要是查看和业务代码相关的行,从而找到调用点。
从上图可以看出,执行程序代码 PreparedSQLQuery 导致的问题。这段是 SQL 代码,是否可以定位到具体的 SQL 语句呢?
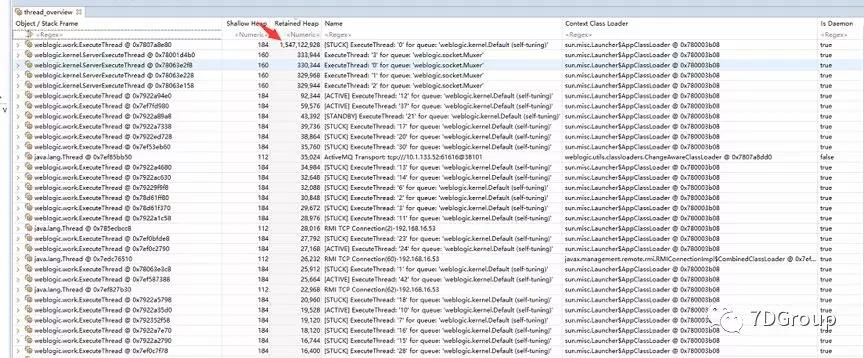
从上图可以看到有一 个 Thread 消耗掉了 1.5G 的内容。展开查看其中的正在执行的 SQL。
从上图的左边的属性值中,可以看到当前正在执行的 SQL。
扩展知识:
4、应用分析
结合后台日志大量提示 SQL 问题,可以确定,这条 SQL 是本次问题的关键所在。

既然拿到了具体 的SQL ,那么就去相应的库中看一下!
拿着 SQL 到相应的数据库中执行。
发现 SQL 长时间没有响应,统计一下数据量大小,SQL 查询出来的数据量是 537755 行,表1中的数据总量是 810093,表 2 中的数据总量是 537755 行。
但是根据实际业务规则,这条 SQL 应该查询出来一条记录。这是怎么回事?
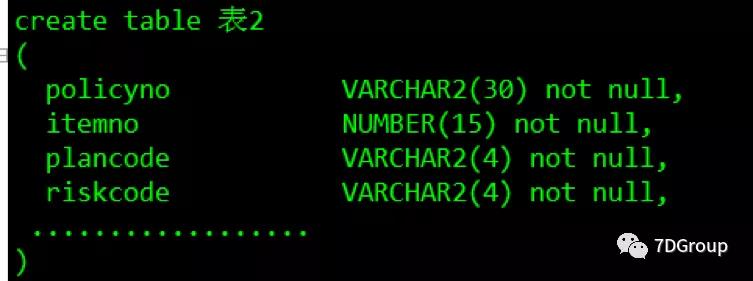
看一下两张表的结构(这里只列出 SQL 涉及到的列和索引):
表1:


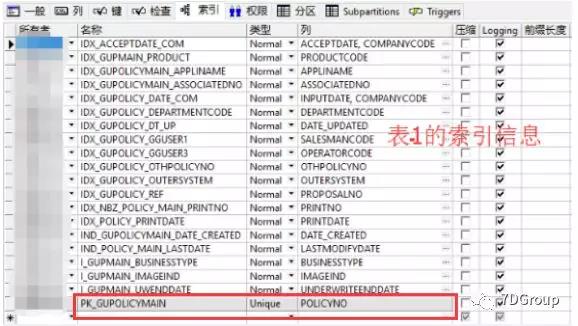
表2:


接下来看一下原 SQL 的执行计划:
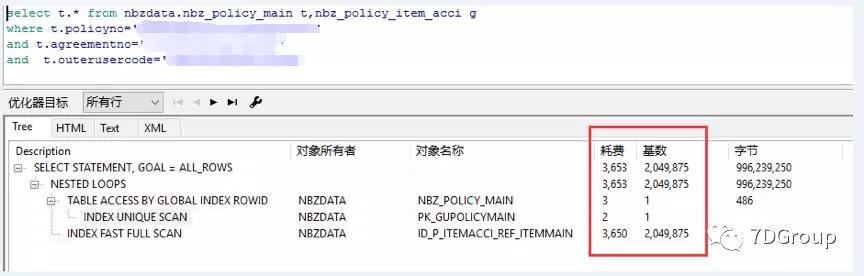
说明下执行计划的相关知识:

结合表结构和执行计划,第 1 张表进行了唯一索引扫描,第 2 张表则是索引快速扫描,似乎没有什么问题,但是cost 和 rows 很高,并且主要来自于第2 张表中。
分析一下原 SQL,最后发现关联表缺少了关联条件。
扩展知识:
四、应用优化
优化一下SQL,查询出来的记录确实是一条,执行时间在 180ms 左右。
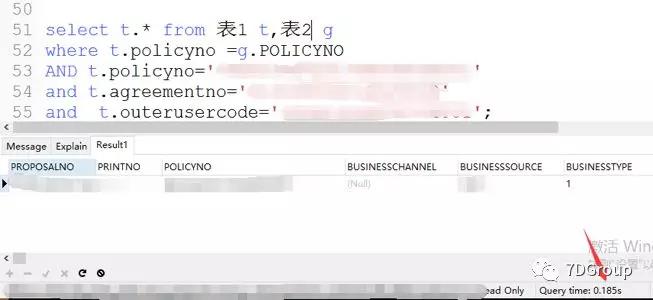
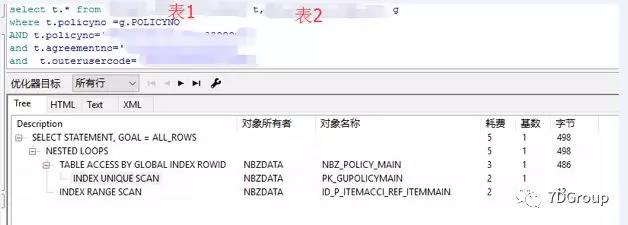
从执行计划来看,添加了关联条件后,成本值大大降低。
经跟开发沟通确认后,他们确实是在测试环境调整了这条 SQL,测试环境恢复正常。了解到在生产环境对应的 SQL 语句是正确的。
五、总结
经过这个例子,我们应该体会到性能分析思路的重要性,基础知识很重要,实践也很重要。只有通过不断地积累,不断地实践,才能把理论体系转化为自己的能力体系。
以上是关于电脑里突然产生大量heapdump.和javacore.的文本文件,应该怎么处理?的主要内容,如果未能解决你的问题,请参考以下文章
[Websphere]如何产生javacore文件和heapdump文件