分布式数据访问服务之2—数据实时分析篇
Posted I love .net
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式数据访问服务之2—数据实时分析篇相关的知识,希望对你有一定的参考价值。
上篇博文中,我们横向对比了业界主流的分布式数据访问服务,可以说是各有所长:
在数据库分库分表实现横向伸缩后,数据的综合查询、分析,业界都有哪些解决方案?这是一个值得研究和讨论的主题。
所以,本篇文章中继续研究分库分表后的数据库综合查询和实时分析技术。
去年我们参加了阿里的云栖大会,参会期间咨询了阿里中间件团队的专家,总结了一下,业界有以下三种技术方案:
1. 大数据:大数据中更多的是Hadoop离线分析、Hive、 Spark 、JStorm等实时分析技术
2. 数据仓库
3. 分析型数据库:
大数据是一个比较大的范畴,我们团队目前也在做应用和落地。但是基于大数据实现分库分表后的综合查询和数据分析,还有很长的路要研究。
但是数据仓库和分析型数据库是一个比较可行的方案,本文中我们主要介绍两种:Druid和GreenPlum
一、Druid
Druid是一个为大型冷数据集上实时探索查询而设计的开源数据分析和存储系统,用于大数据实时查询和分析的高容错、高性能开源分布式系统,旨在快速处理大规模的数据,并能够实现快速查询和分析。
- 为分析而设计——Druid是为OLAP工作流的探索性分析而构建,它支持各种过滤、聚合和查询等类;
- 快速的交互式查询——Druid的低延迟数据摄取架构允许事件在它们创建后毫秒内可被查询到;
- 高可用性——Druid的数据在系统更新时依然可用,规模的扩大和缩小都不会造成数据丢失;
- 可扩展——Druid已实现每天能够处理数十亿事件和TB级数据。
Druid主要应用场景:广告分析、互联网广告系统监控以及网络监控等。
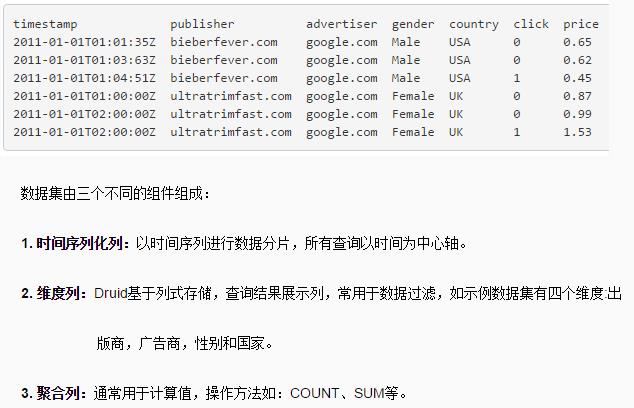
使用Druid,我们比较关注的是:是否支持类SQL查询、聚合操作?
Druid 查询
Druid的本地查询语言是JSON通过HTTP,虽然社区在众多的语言中提供了查询库,包括SQL查询贡献库;
Druid设计用于单表操作,目前不支持联接。许多产品准备在ETL集成,数据加载到Druid之前需要规范化。
Druid 聚合
GROUP BY timestamp, publisher, advertiser, gender, country
:: impressions = COUNT(1), clicks = SUM(click), revenue = SUM(price)
参考链接: http://yangyangmyself.iteye.com/blog/2320502
综合来讲,Druid是一个不错的OLAP解决方案,但同时不支持关联查询,需要改造原有SQL查询写法。
二、GreenPlum
Greenplum分布式数据库是为了支持新一代数据仓库和分析处理大规模数据而设计的。
Greenplum支持SQL和MapReduce的并行处理功能,支持50PB(1PB=1000TB)级海量数据的存储和处理。
高并发、线性扩展
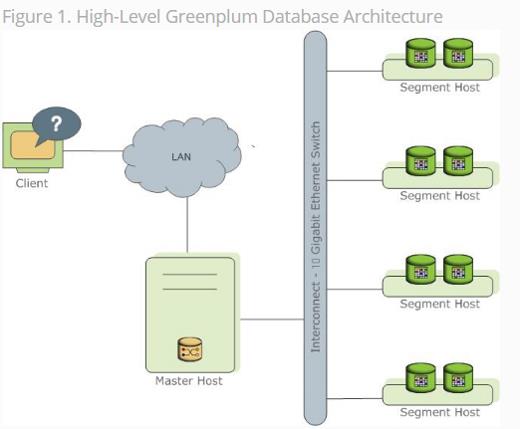
Greenplum的架构采用了MPP(大规模并行处理)。在 MPP 系统中,每个 SMP节点也可以运行自己的操作系统、数据库等。在MPP架构中增加节点就可以线性提高系统的存储容量和处理能力。Greenplum在扩展节点时操作简单,在很短时间内就能完成数据的重新分布。
实时查询
通过准实时、实时的数据加载方式,实现数据仓库的实时更新,进而实现动态数据仓库(ADW)。
基于动态数据仓库,业务用户能对当前业务数据进行BI实时分析-“Just In Time BI”。
高可用性
在已有案例中最多使用了96台机器的集群MPP环境。除了硬件级的Raid技术外,Greenplum还提供数据库层Mirror机制保护,即每个节点数据在另外的节点中同步镜像,单个节点的错误不影响整个系统的使用。
简单易用
Greenplum产品是基于流行的PostgreSQL之上开发,几乎所有的PostgreSQL客户端工具及PostgreSQL应用都能运行在Greenplum平台上,在Internet上有着丰富的PostgreSQL资源供用户参考。
数据处理
支持数据查询,机器学习,文本挖掘,统计计算等
使用业界标准的语言(SQL,MapReduce,R),在各个数据层级进行并行分析
GreenPlum MPP架构:
GreenPlum数据分布:
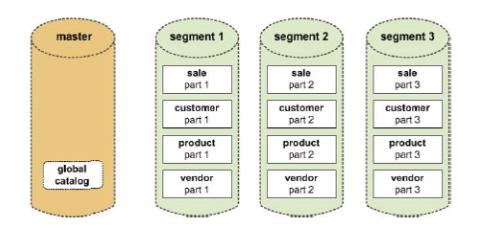
在greenplum中每个表都是分布在所有节点上的。Master host首先通过对表的某个或多个列进行hash运算,然后根据hash结果将表的数据分布到segment host中。整个过程中master host不存放任何用户数据,只是对客户端进行访问控制和存储表分布逻辑的元数据。
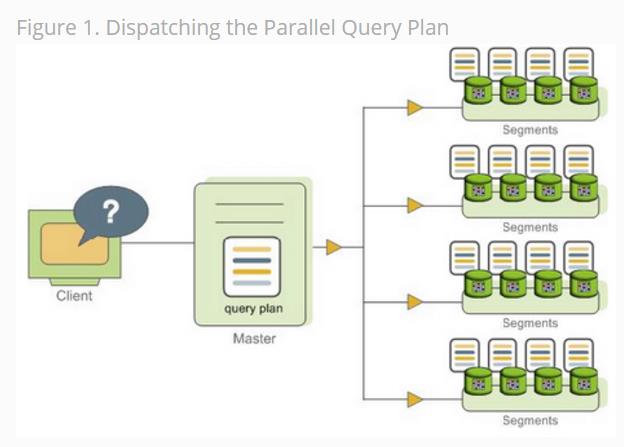
GreenPlum并行执行计划分发:
Postgre SQL聚合查询

Apache MADLib 查询
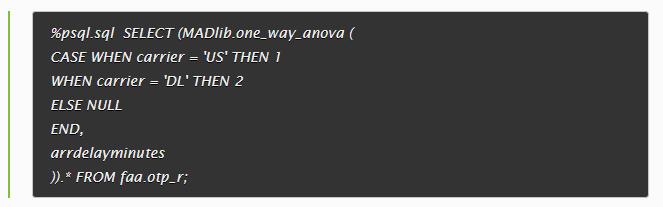
对比Druid和GreenPlum:
Druid更适用于大数据(冷数据)分析,GreenPlum更适用于业务数据实时分析。
基于GreenPlum实现业务综合查询:数据同步(SQLServer->GreenPlum),官方提供的解决方案:数据CSV-定时导入GreenPlum,有数据延迟、增量同步问题。
周国庆
2017/5/11
以上是关于分布式数据访问服务之2—数据实时分析篇的主要内容,如果未能解决你的问题,请参考以下文章
69_缓存预热解决方案:基于storm实时热点统计的分布式并行缓存预热