定位元素
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了定位元素相关的知识,希望对你有一定的参考价值。
WebDriver 属于 Selenium 体系中设计出来python操作浏览器的一套 API。
webdriver 提供8种定位元素的方法:
- id
- name
- class name
- tag name
- link text
- partial link text
- xpath
- css selector
Python 语言中对应的定位方法如下:
- find_element_by_id()
- find_element_by_name()
- find_element_by_class_name()
- find_element_by_tag_name()
- find_element_by_link_text()
- find_element_by_partial_link_text()
- find_element_by_xpath()
- find_element_by_css_selector()
ID
唯一值
find_element_by_id("标签中的id属性值")
name
如果没给定该属性则不能通过该方法查找
find_element_by_name("标签中的name属性值")
class name
通过类名,有可能有多个相同的类名,返回一个数组
find_element_by_class_name("标签中的class name值")
tag name
通过标签名,一般都有多个相同的标签名,返回一个数组
find_element_by_tag_name("标签名")
link text
专门用来定位文本链接,通过元素标签对之间的文本信息来定位元素。
<a class="mnav" name="tj_trmap" href="http://map.baidu.com">地图</a> <a class="mnav" name="tj_trvideo" href="http://v.baidu.com">视频</a> <a class="mnav" name="tj_trtieba" href="http://tieba.baidu.com">贴吧>
Python 对于中文的支持并不好,如查 Python 在执行中文的地方出现在乱码,可以在中文件字符串的前面加个小"u"可以有效的避免乱码的问题,加 u 的作用是把中文字符串转换中 unicode 编码,
find_element_by_link_text(u"新闻")
partial link
对link text,有些文本连接会比较长,可以取文本链接的一部分定位,只要这一部分信息可以唯一的标识这个链接。
<a class="mnav" name="tj_lang" href="#">如果链接的文本很长很长,你可以选取一部分进行唯一定位</a>
定位:
find_element_by_partial_link_text("进行唯一定位")
Xpath定位
XPath 是一种在 XML 文档中定位元素的语言。因为 html 可以看做 XML 的一种实现,所以 selenium用户可是使用这种强大语言在 web 应用中定位元素。
1)层级绝对定位:通过标签寻路定位
寻找html下->body->div->第2个div->div->div->div->from->span->input.找到该input元素:
find_element_by_xpath("/html/body/div/div[2]/div/div/div/from/span/input")
2)元素属性定位
find_element_by_xpath("//input[@class=‘s_ipt‘]") #查找当前页面下某个目录中,标签名为input,class属性的值为s_ipt的元素 find_element_by_xpath("//*[@id=‘wd‘]") #查找当前页面下某个目录中,所有标签,id属性值为wd的元素
// :表示当前页面某个目录下
所有属性都可以用来定位,当然该属性最好具有唯一性
3)层级与属性结合
如果一个元素本身并没有可以唯一标识这个元素的属性值,但是它的上级有可以唯一标识属性的值。
可以这样用:
find_element_by_xpath("//span[@class=‘bg s_btn_wr‘]/input") #先定位input标签的父标签,即class属性为bg s_btn_wr的span标签,然后再取得其下面的input标签元素
如果父级也不能唯一标识,那就先定位父级的父级,依此往上推。
4)逻辑运算符: 联合多个属性定位
#<input id="kw" class="su" name="ie"> find_element_by_xpath("//input[@id=‘kw‘ and @class=‘su‘]/span/input")
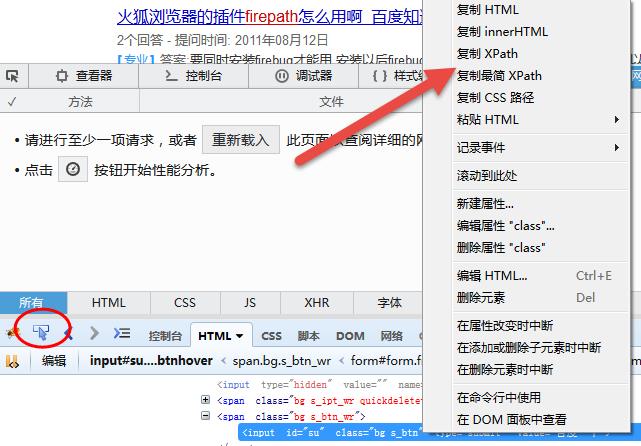
Firebug 前端调试工具和 FirePath 插件可以方便的辅助 XPath 语法。打开 FireFox 浏览器的 FireBug 插件,点击插件左上角的鼠标箭头,再点击页面上需要定位的元素,在元素行上右键弹出快捷菜单,选择“复制 XPath”,将会获得当前元素的 XPath 语法:
css 定位
CSS 可以比较灵活选择控件的任意属性,一般情况下定位速度要比 XPath 快。
- .class : class 选择器
- #id: id 选择器
- * : 选择所有元素
- element: 标签元素
- element1 > element2: 直系,选择父元素为 element1元素的所有elment2元素
- element1 + element2: 非直系,选择紧接在element1 元素之后的所有element2 元素
- element[attribute=value] : 选择attribute="value" 的所有element元素。
组合定位:
find_element_by_css_selector("span.bg s_ipt_wr>input.s_ipt") #选择span标签,类名为bg s_ipt_wr,该span标签下面的input标签类名为s_ipt
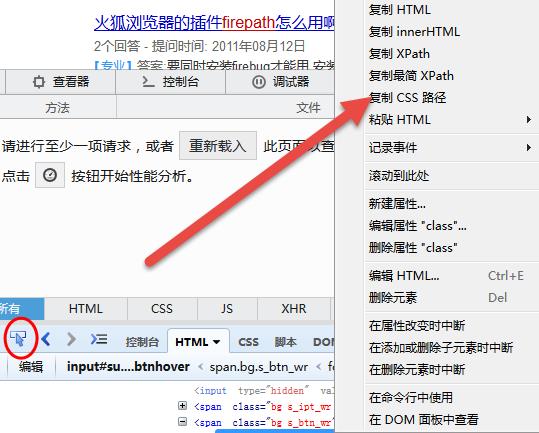
我们通过可以使用 Firebug 工具帮助我们生成 CSS 语法。通过 Firebug 定位元素,在元素上右键点击选择“复制 CSS”
find_element()与 By 定位元素
在使用 By 时需要将 By 类导入:from selenium.webdriver.common.by import By
- 参数1:定位方式
- 参数2:定位的值
find_element(By.ID,"kw") find_element(By.NAME,"wd") find_element(By.CLASS_NAME,"s_ipt") find_element(By.TAG_NAME,"input") find_element(By.LINK_TEXT,u"新闻") find_element(By.PARTIAL_LINK_TEXT,u"新") find_element(By.XPATH,"//*[@class=‘bg s_btn‘]") find_element(By.CSS_SELECTOR,"span.bg s_btn_wr>input#su")
以上是关于定位元素的主要内容,如果未能解决你的问题,请参考以下文章