Flume搭建及学习(基础篇)
Posted dark_saber
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flume搭建及学习(基础篇)相关的知识,希望对你有一定的参考价值。
转载请注明原文出处:http://www.cnblogs.com/lighten/p/6830439.html
1.简介
该文主要是翻译官方的相关文档,源地址点击这里。介绍一下Flume的一些基本知识和搭建方法。
Apache Flume是一种分布式,可靠和可用的系统,用于高效收集,聚合和将许多不同的来源的大量日志数据移动到集中式数据存储。
Apache Flume的使用不仅限于日志数据聚合。 由于数据源是可定制的,因此可以使用Flume来传输大量事件数据,包括但不限于网络流量数据,社交媒体生成数据,电子邮件消息以及几乎任何数据源。
目前有两个版本的代码行可用,0.9.x和1.x版本。“Flume 0.9.x用户指南”提供0.9.x跟踪的文档。本文档适用于1.4.x踪迹。
鼓励新用户和现有用户使用1.x版本,以便利用最新架构中提供的性能改进和配置灵活性。
2.环境要求
Java运行时环境 - Java 1.7或更高版本
内存 -sources, channels 或 sinks使用,需配置足够的内存
磁盘空间 - 用于channels 或sinks使用的配置的足够的磁盘空间
目录权限 - agent使用的目录的读/写权限
3.数据流模型
Flume事件被定义为数据流单元,其包含有效载荷字节和可选的一组字符串属性。Flume代理是一个(JVM)进程,它管理组件的事件流从外部源传递到下一个目标。
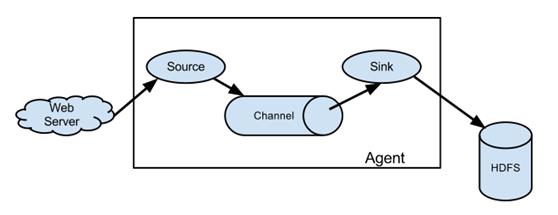
Flume源消耗由外部源(如Web服务器)传递给它的事件。外部源用特定的可以被目标Flume识别的格式发送给Flume。例如,一个Avro Flume源可以被用于接收来自Avro客户端或者是其它流中发送来自Avro sink事件的Flume代理的Avro事件。类似的流可以被定义使用一个Thrift Flume Source来接收来自Thrift Sink或Flume Thrift Rpc客户端,或者使用来自Flume thrift协议生成的任何语言编写的Thrift客户端的事件。当Flume源接收到一个事件时,它将其存储到一个或多个通道中。 该通道是一个被动存储,保持事件,直到它被Flume sink消耗。 文件通道是一个例子 - 它由本地文件系统支持。 接收器从通道中删除事件,并将其放入外部存储库(如HDFS(通过Flume HDFS sink)),或将其转发到流中下一个Flume代理(下一跳)的Flume源。 给定代理中的源和接收器与通道中分段的事件异步运行。
Flume允许用户建立多hop流,其中事件在到达最终目的地之前穿过多个代理。 它还允许为失败的hops提供fan-in和fan-out流,上下文路由和备份路由(故障切换)。
事件在每个代理的频道上进行。 然后将事件传递到流中的下一个代理或终端存储库(如HDFS)。 事件只有在存储在下一个代理的通道或终端存储库中之后才从通道中删除。 这是Flume中单跳消息传递语义如何提供流的端到端可靠性。
Flume采用transactional方式来保证事件的可靠传递。 source和sink分别在事务中封装存储/检索,由通道提供的事务来放置或提供事件。 这确保了事件集可以在流程中从点到点可靠地传递。 在多hop流程的情况下,来自上一hop的汇聚和来自下一跳的源都具有其事务运行,以确保数据被安全地存储在下一跳的信道中。
这些事件是在通道中进行的,它管理从故障中恢复。 Flume支持由本地文件系统支持的持久文件通道。 还有一个内存通道,它将事件简单地存储在内存中的队列中,速度更快,但当代理进程死机时仍然保留在内存通道中的任何事件都无法恢复。
4.下载
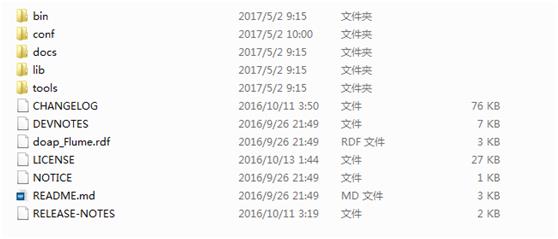
点击这里,下载二进制包,解压安装包,目录结构如下:
5.配置
Flume代理配置存储在本地配置文件中。 这是一个遵循Java属性文件格式的文本文件。 可以在同一配置文件中指定一个或多个代理的配置。 配置文件包括代理中每个源,宿和通道的属性,以及它们如何连接在一起以形成数据流。
流中的每个组件(源,宿或通道)具有特定类型和实例化的名称,类型和属性集。 例如,Avro源需要一个主机名(或IP地址)和一个端口号来接收数据。 内存通道可以具有最大队列大小(“容量”),并且HDFS接收器需要知道文件系统URI,创建文件的路径,文件轮换的频率(“hdfs.rollInterval”)等。组件的所有这些属性 需要在托管Flume代理的属性文件中设置。
代理需要知道要加载的单个组件以及它们如何连接以构成流。 这是通过列出代理中每个源,接收器和通道的名称,然后为每个接收器和源指定连接通道来完成的。 例如,代理程序通过称为文件通道的文件通道将来自Avro源的Avro源的事件流经HDFS sink hdfs-cluster1。 配置文件将包含这些组件的名称和文件通道作为avroWeb源和hdfs-cluster1 sink的共享通道。
开启一个代理:代理开启是通过使用一个shell脚本称为flume-ng,其位于Flume的bin目录下。你需要指定代理的名称,配置目录和配置文件,通过以下命令进行:
$ bin/flume-ng agent –n $agent_name –c conf –f conf/flume-conf.properties.template
在这里,我们给出一个示例配置文件,描述单节点Flume部署。 此配置允许用户生成事件,然后将其记录到控制台。
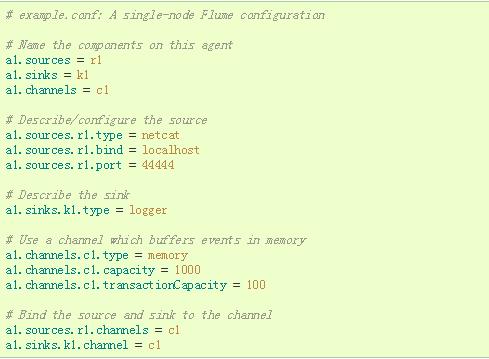
此配置定义了名为a1的单个代理。 a1有一个源,用于监听端口44444上的数据,缓冲区内存中的事件数据的通道和将事件数据记录到控制台的接收器。 配置文件命名各种组件,然后介绍其类型和配置参数。 给定的配置文件可以定义几个命名的代理; 当一个给定的Flume进程被启动时,一个标志被传递,告诉它哪个命名的代理显示。
给定这个配置文件,我们可以启动Flume,如下所示:
$ bin/flume-ng agent –conf conf –conf-file example.conf –name a1 –Dflume.root.logger=INFO,console
我是在windows上进行操作的,下面给出windows的相关处理方法:
Windows下,flume高版本集成了powershell,基础的flume配置文件不变,但是要在控制台输出相关的日志信息,还需要将conf文件夹下的flume-env.ps1.template重命名为flume-env.ps1,在里面添加如下:
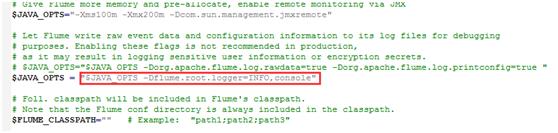
然后再执行下面的命令:
bin> flume-ng.cmd agent -conf ../conf -conf-file ../conf/flume-conf.properties -name a1
使用flume-ng.cmd help查看在windows下的用法:
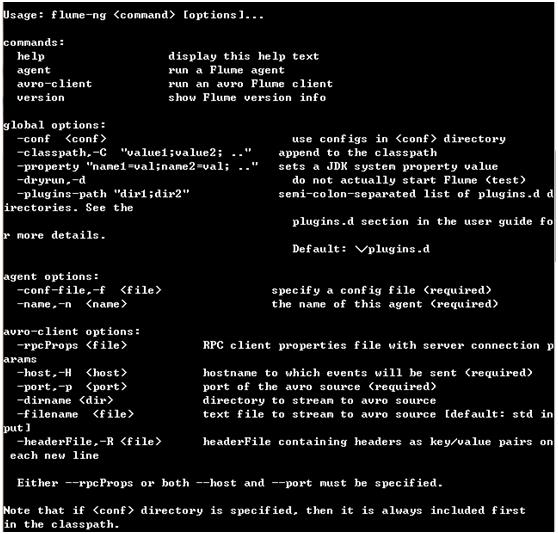
请注意,在完全部署中,我们通常会再包含一个选项:--conf = <conf-dir>。 <conf-dir>目录将包含shell脚本flume-env.sh和潜在的log4j属性文件。 在这个例子中,我们传递一个Java选项来强制Flume登录到控制台,而没有一个自定义的环境脚本。
从另一个单独的终端,我们可以telnet端口44444并发送Flume一个事件:
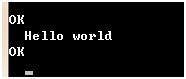
在之前的Flume的终端就可以看见:

这样就完成了简单的配置了。
6.后记
这篇文章主要是讲解一下flume的基础知识和搭建,后续可能会更进一步补充相关知识。
以上是关于Flume搭建及学习(基础篇)的主要内容,如果未能解决你的问题,请参考以下文章