通用报文解析服务的演进之路(基于磁盘目录的分布式消息消费者服务)之二
Posted Pleiades
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了通用报文解析服务的演进之路(基于磁盘目录的分布式消息消费者服务)之二相关的知识,希望对你有一定的参考价值。
 用多线程形成流水作业模式,挖掘服务器性能潜力,提升性能。
用多线程形成流水作业模式,挖掘服务器性能潜力,提升性能。
书接上回,继续分享。
通用报文解析服务,用C#开发,经历了三版更新,支撑起了关区内的绝大多数数据交换业务,截止至今,每日收发报文约20万,数据量约5G,平均延迟在1分钟内。
回想起那些半夜处理积压报文的场景,不胜唏嘘,决定把这个演进过程向大家讲述一下。回顾历史,展望未来,如果能给大家一些启发,是再好不过的了。
(第二版)
二、通用报文解析服务V2.0——数据库,多线程
开发第二版时,更换了底层框架,使用IOC控制反转、DDD领域驱动等设计思想,增加了将报文存放在数据库中的功能,并且分为运行时表和历史表,分别可以查询。数据库用的SQLServer2008 R2
不过这都不是重要的,最重要的是,变成多线程了,将多个操作通过线程形成流水作业,一共有以下几个线程:
- FileReceiver:报文接收线程,负责扫描接收目录,将报文内容插入报文数据库,再将报文文件移动到备份目录。主要瓶颈为本地磁盘和报文数据库的速度。
- FileParser:报文解析线程,负责从报文数据库中找到还未解析的报文,调用对应的解析器,执行对应的入库操作。分批执行,一次调取100个。主要瓶颈为报文数据库和具体业务数据库的速度,以及CPU。
- FileCleaner:文件清理线程,负责清理备份目录,只保留一定时间段内的文件。每日定时执行。
- DataBak:运行时表备份,负责将运行时表中一定时间之前的数据移动到历史表。每日定时执行。
- DataCleaner:历史报文清理线程,负责清理报文数据库中的历史报文以及移动运行时表中的报文到历史表。每日定时执行。
可见FileReceiver线程和FileParser线程无需互相等待,真正实现了流水作业。执行效率得到了很大提升。
流程图如下所示,包含了主要的线程FileReceiver和FileParser。之所以叫V2.1,是因为这是经过一次改进之后的流程。
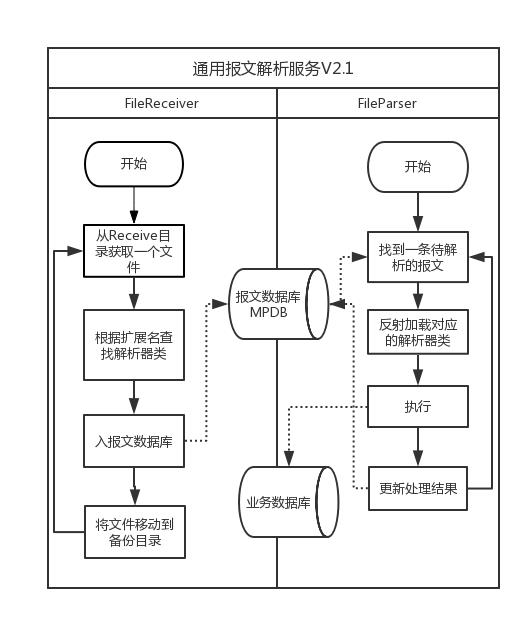
这个新的架构注定要历经磨难才能成熟,不断有新问题困扰着我们。
(1)文件枚举。
有个老问题没有解决,那就是接收目录中文件一多(5000以上),FileReceiver就像死了一样,好久才能读取一个文件,新的报文还在不断涌入,形成恶性循环,如果没人干预,就一直堵到天荒地老。
后来发现了原因,C#中的获取文件的方法是Directory.GetFiles(),这个方法用过的都知道,文件一多,执行速度是很慢的,因为他要把所有文件名都枚举出来后再返回结果。
还是多亏了小蔡,改成了调用Win32 API FindFirstFile、FindNextFile方法,读文件不再等待,秒回!
其实.Net4.0后可以用Directory.EnumerateFiles()方法啊,一样可以枚举到文件。当年还没有这个方法的说,后来为了稳妥就没有再改。
(2)报文优先级
改了文件枚举了之后,解析目录不再堵成一锅粥了,但是数据库中却排起了长队。就像景区大门变宽了,人进的多了,可是里边变堵了。
那段时间正好有新的报文种类,从预订系统发送过来,实时性要求不高,但量很大。这让那些需要及时解析的报文也跟着排起了长队,那段时间真是看着干着急,后来想了个办法建个临时表,每天将待解析的数据倒来倒去。于是就诞生了优先级的设置,FileParser线程优先扫描优先级高的报文,执行。等没有高优先级的报文时,再解析优先级低的报文。
某些报文的实时性算是保证了,但是其他优先级较低的报文却总是得不到光顾,一堵又是一整天。
FileParser就那么一个线程,处理能力已经大大跟不上报文的增长了,需要考虑再拆分了,于是诞生了报文分组。
(3)报文分组
逼迫我考虑报文分组的原因,除了上述原因外,还有一个关键原因,就是某种报文总是引起FileParser线程假死,catch不到异常,又不见动静,这时候只能重启服务。一周出现3-5次,时间不固定,又没有有效的手段及时发现,往往是业务上打电话来报故障了,才意识到报文已经积压了好几万。重启后,半天才能处理完。那阵子,一听到手机响就紧张。o(╯□╰)o
我认为,不能让一种报文的解析影响其他报文,比如某一个系统有2报文,都入他的业务数据,他的数据可能会故障,可能会慢,可能会引起假死,但其他报文也会受到牵连,整个系统就很容易瘫痪。系统故障的概率就变成了ρ = 1 - (1 - ρ1)(1 - ρ2)(1 - ρ3)...
(设ρn是第n个子系统的故障概率)
将各报文类型按照业务相关性进行分组GROUP1,GROUP2,GROUP3...。再按照分组分别建立FileParser线程,每个FileParser只扫描所属分组的报文,执行解析。这样某个报文的故障或缓慢只会影响所在分组,基本就只影响某一个系统。而且出现了问题也容易定位原因。
(4)线程监控
线程多了,运维的问题也随之而来,一个线程假死都会引起巨大的问题,如何及时发现这些问题成了当务之急。
我们的底层框架中Windows服务支持多线程,每个线程可以设定间隔自动执行,每次执行都会更新最近执行时间和执行结果,然后进入等待状态,等待下一次被调用。
于是在我的提议下,我们增加了线程状态监控功能,并且对外提供WCF接口,由Windows服务作为Host承载。结合我们单位的OAM监控系统,自动以短信方式推送,非常方便,让我养成了没事就看看短信的好习惯,感觉心(tí)旷(xīn)神(diào)怡(dǎn)。
总之这件事让系统在人工的维护下,就算bug不断,还是能够相对稳固运行的。
(5)轮询智能变速
报文分组了,FileParser线程也从一个变成了多个,这时新问题又来了,报文数据库的入库和查询速度都变得有些慢了,导致整体上效率比没分组时没高多少。用SqlProfilor分析,也没有显著比较慢的语句,但是现象就是大家都慢了,那段时间我百思不得其解,甚至开始合并一些分组来减少线程。
后来我对着配置文件终于参悟到了原因,当初为了提高效率,每个线程的轮询间隔时间都很短(最短20ms,长一点的250ms),FileParser线程一多,这让数据库根本难以承受啊,怪不得呢。
详细的原因应该是这样,某些分组的FileParser总会很闲,好久不来一个报文,于是就在那里20ms一次的去做SELECT,占用了大部分资源,使得那些有活等着干的FileParser线程被排挤,得不到应有的资源。
就像去工地搬砖,总是有几个人在不停轮流的问工头:“有没有我要搬的砖?”,工头:“没有o(╯□╰)o”。其他人就只能每次排着队等着问工头。解决的办法就是没活干的人可以偷点懒,歇五分钟再来问嘛。于是我让他们都来个智能变速,FileParser线程的当前查询结果是0条时,原地sleep10秒钟。同理,FileReceiver也这样处理。放到正式环境后,效果真是立竿见影。
(6)集群化改造
经过上面一系列的改进,已经能够比较稳定的运行了。但是每日的报文量在不断的增加,从一开始的一万份到两万,再到10万,高峰时的处理速度逐渐跟不上了,延迟有时候能达到1个多小时。
这时,本地磁盘接收目录的读写效率成为了瓶颈。同时,某些解析线程任务量格外大,导致跟不上报文接收的速度了。
于是我开始考虑系统的横向扩展,在一台新的虚拟机上部署新的报文解析服务,将一半报文改在那里接收,同时通过配置,让他启动一部分分组的FileParser线程,来缓解原来一台服务器的压力。
理论上,这样的扩展可以一直做下去,效率满意为止,或直到不能再细分。
(7)失败自动重试
报文解析过程中总会遇到各种意外问题,例如事务失败,网络超时,数据库无法连接,数据库根本无法连接等等,有些问题需要人工干预才能解决,但是像网络超时、事务失败这些一般通过重试就能自动解决的问题,却频繁出现,很是烦人。于是我想到在解析时如果抛出异常,就判断一下异常消息是否带有“事务”,“超时”,“timeout”等字样,如果是,就自动延时一定时间再解析一遍,最多重试3次。
到此几乎能做的改进都做完了,剩下的也就是小修小补的了。但始终有个问题还在困扰我,那就是程序集版本的问题。解析器程序集来自于不同的项目小组,他们会引用一些公共的组件库,这些组件库会有不同的版本,有时候一家更新了公共组件库,就导致更新后不能运行。有时我更新了报文解析服务的组件库,可能导致大家都不能运行,都得用我的组件库版本重新编译、发布。每当出现这种问题的时候,原因特别不好排查,不知道是谁家版本不一致。曾经用过一个折中的办法,就是我提供一套我的公共组件库版本,大家都统一用这个版本编译、发布。而我也基本上不能更新公共组件库了。
为了解决这个“终极问题”,我们引入了RabbitMQ。下一篇再详细讲讲。
虽然问题层出不穷,但是解决问题的过程很有乐趣,解决问题时也很有成就感,希望能给大家一些启发。
以上是关于通用报文解析服务的演进之路(基于磁盘目录的分布式消息消费者服务)之二的主要内容,如果未能解决你的问题,请参考以下文章