数据同步这点事
Posted 超级核弹头
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据同步这点事相关的知识,希望对你有一定的参考价值。
最近一段时间,在做数据ETL相关的事,结合实践以及自己的思考,记录下来,以做参考。
概述
一般来说,数据团队自己是很少生产数据的,一般都是对业务线的数据进行分析加工,从而让数据产生价值。一方面,业务线的数据会存到关系数据(如mysql),磁盘(日志)等存储介质;另一方面,基于大数据的分析一般会将数据存储到hdfs,hbase,es。因此,不可避免地我们需要在这些不同的存储介质间同步数据。
从同步时效性来说,可以分为离线同步和实时同步。离线同步,相当于某个时候对源数据做一个快照。而实时同步,一般是通过监控源数据变更操作,通过在目标端实时重放操作,从而达到实时同步的目的(如通过Binlog,EditLog)。
离线同步
离线数据同步目前已经有开源的实现,比较流行的主要是sqoop和datax,关于她们的历史,这里不做介绍。本文主要说一下使用sqoop和datax以及自研的一些实践。
背景
组里最原始的数据同步主要由以下部分组成:
1,用sqoop从mysql导入到hdfs。
2,用自研的工具从hdfs导出到mysql(至于为什么不用sqoop?主要是导出需要做一些ETL处理,sqoop不能满足需求)。
3,另一套自研的工具从分库mysql导出到hbase。
通过这个三个独立的系统,基本能够满足日常的数据同步需求。但是存在一些问题:
a, 工具太分散,好几套独立的系统不太好维护。
b, 扩展性很差,当初设计时,没有考虑考虑扩展性,字眼的系统嵌入到了调度系统,很难抽象出来,作为独立的服务。
c, 服务服务:告警监控不完善等。
改造
随着处理数据量以及任务的越来越大,越来越多,针对以上问题,决定基于开源的datax做深度定制。从而将数据同步服务统一起来。主要的改造点如下:
1,将导入导出服务统一到datax,包括对失败任务重试,删除增量删除等。
2,监控指标和日志统一接入数据平台。
3,数据质量处理:脏数据告警,默认的类型转换。
4,schema检验等。
实时同步
目标
实现可配置实时同步
设计
输入和输出变化很大,但是实时数据同步的核心却只有两个问题:
a, 数据不能丢失
b, 对数据乱序进行处理,不能出现旧的数据把新的数据覆盖了
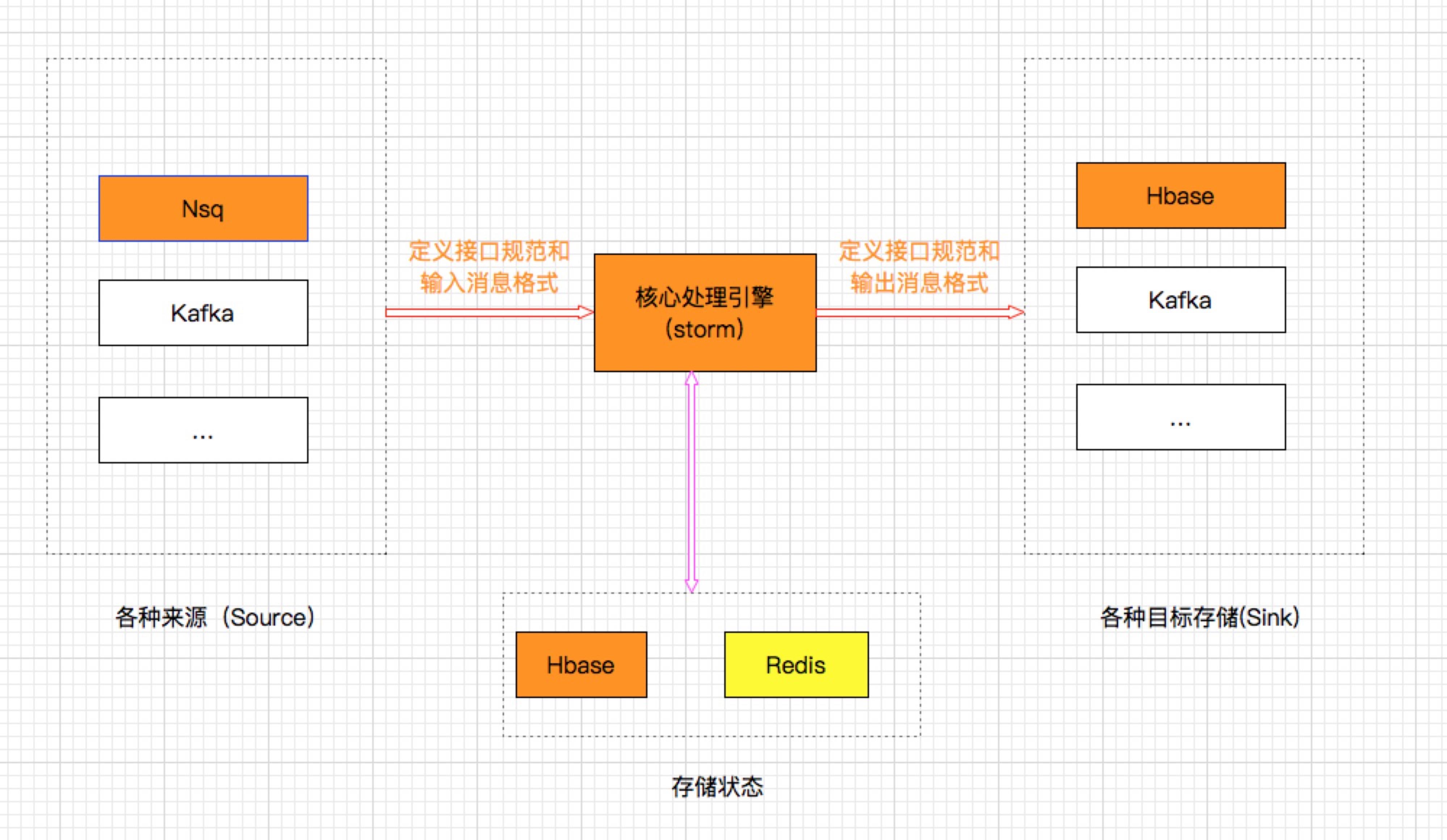
设计思路主要基于以下两点:
1,针对不通的输入和输出,则必须和核心的处理单元进行解耦,因此源端和目标端因不同的系统,差异很大,所以提供各自的实现。但是必须通过定义好的接口和消息格式,实现统一。
2,核心处理引擎,主要基于storm,然后通过外部存储系统来保存中间状态。
小结
总的来说,基于datax改造还是蛮顺利的,简单有效。而基于实时同步系统的设计,可以说也借助了离线同步系统的开源设计思想,通过source和sink分离,核心引擎共享的设计来实现。目前两套系统已经成功上线,并且效果不错。
以上是关于数据同步这点事的主要内容,如果未能解决你的问题,请参考以下文章