python 爬虫 ip池怎么做
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python 爬虫 ip池怎么做相关的知识,希望对你有一定的参考价值。
无论是爬取IP,都能在本地设计动态代理IP池。这样既方便使用,又可以提升工作效率。那么怎么在本地设计一个代理IP池呢?IPIDEA为大家简述本地代理IP池的设计和日常维护。代理IP获取接口,如果是普通代理IP,使用ProxyGetter接口,从代理源网站抓取最新代理IP;如果是需耗费代理IP,一般都有提供获取IP的API,会有一定的限制,比如每次提取多少个,提取间隔多少秒。
代理IP数据库,用以存放在动态VPS上获取到的代理IP,建议选择SSDB。SSDB的性能很突出,与Redis基本相当了,Redis是内存型,容量问题是弱项,并且内存成本太高,SSDB针对这个弱点,使用硬盘存储,使用Google高性能的存储引擎LevelDB,适合大数据量处理并把性能优化到Redis级别。
代理IP检验计划,代理IP具备时效性,过有效期就会失效,因此 需要去检验有效性。设置一个定时检验计划,检验代理IP有效性,删除无效IP、高延时IP,同时预警,当IP池里的IP少于某个阈值时,根据代理IP获取接口获取新的IP。
代理IP池外部接口除代理拨号服务器获取的代理IP池,还需要设计一个外部接口,通过这个接口调用IP池里的IP给爬虫使用。代理IP池功能比较简单,使用Flask就可以搞定。功能可以是给爬虫提供get/delete/refresh等接口,方便爬虫直接使用。 参考技术A 自己做个代理服务器。例如618爬虫代理,再指向次一级代理。或者是直接让爬虫通过http proxy的参数设置去先把一个代理。 代理池通常是租来的,或者是扫描出来的。扫描出来的往往大部分都不可用。 爬虫的实现有几百种方案。通常建议直接从SCRAPY入手。 参考技术B 扫描当前目前下所有的gz文件
currDir = os.getcwd()
files = os.listdir(currDir)
dstDir = "201301_09"
if not os.path.exists(dstDir):
os.mkdir(dstDir)
for fileName in files:
if os.path.isfile(fileName) and tarfile.is_tarfile(fileName):
print fileName
try:
tar = tarfile.open(file)#这里应该是fileName而不是file
names = tar.getnames()
for name in names:
tar.extract(name,path=dstDir)
tar.close()
except tarfile.ReadError:
print "not a tarFile"
pass本回答被提问者采纳 参考技术C 如今,网络中有很多的爬虫工作者,那么大家知道如何维护爬虫ip池吗?下面就跟随小编一起来了解下吧:
一、自行购买IP地址,做代理池。
能利用各种云能换IP的api(弹性IP),采用几个实例做出口,如果被封了就换IP,大概看看IP的价格吧,大概看一下IP的价格,这实在太不切实际,理论上这比上个便宜,但仍然很贵。
二、直购代理。
这些代理有扫描得来的,价格最便宜,但可用度低,需要自己核实,其次是自建机房拨出去的,这种IP质量还可以,最好的是家庭IP,通过家庭宽带产生的IP,这种IP与普通网民使用的IP一致,可用率高,不易被封。
三、销售代理网站。
一般,销售代理网站往往都会提供一些免费的代理在首页吸引流量,少则几十,多则几百,初步测试几个就可以用了。现在直接购买代理也需要验证,那不如直接抓取他们网站上提供的免费代理。确认入库后,使用时直接选择一台即可。
自办一个代理池其实并不难,怎么维护才是问题,很多人由于平时太忙而没有足够的时间对IP池进行维护,所以都是选择直接购买代理池。 参考技术D 爬虫使用了代理了ip被封的原因有以下几点:
1、请求的频次太多
一般来说,爬虫工作者的任务量是很大的,有很多的爬虫工作者想要快速的完成任务就会在一定的时间内多次的请求,这样就会给目标服务器带来很大的压力,就很容易受到限制。
2、代理IP使用人数过多
当一个代理IP池中使用人数过多的时候也会存在被封的情况,比如,有许多人使用同一个代理IP来访问同一个网站,这样目标网站就会监测到,代理IP就会被限制。
3、代理IP不是高匿代理
不是高匿代理代理IP是指透明代理IP和普通代理IP,透明代理IP会暴露本机真实的IP地址,普通代理IP会暴露当前正在使用的代理IP,这两者代理IP都很容易被限制,而兔子IP则会隐藏真实的IP,躲过网站的反爬机制。
快速构建Python爬虫IP代理池服务
在公司做分布式深网爬虫,搭建了一套稳定的代理池服务,为上千个爬虫提供有效的代理,保证各个爬虫拿到的都是对应网站有效的代理IP,从而保证爬虫快速稳定的运行,当然在公司做的东西不能开源出来。不过呢,闲暇时间手痒,所以就想利用一些免费的资源搞一个简单的代理池服务。
1、问题
代理IP从何而来?
刚自学爬虫的时候没有代理IP就去西刺、快代理之类有免费代理的网站去爬,还是有个别代理能用。当然,如果你有更好的代理接口也可以自己接入。
免费代理的采集也很简单,无非就是:访问页面页面 —> 正则/xpath提取 —> 保存
如何保证代理质量?
可以肯定免费的代理IP大部分都是不能用的,不然别人为什么还提供付费的(不过事实是很多代理商的付费IP也不稳定,也有很多是不能用)。所以采集回来的代理IP不能直接使用,可以写检测程序不断的去用这些代理访问一个稳定的网站,看是否可以正常使用。这个过程可以使用多线程或异步的方式,因为检测代理是个很慢的过程。
采集回来的代理如何存储?
这里不得不推荐一个高性能支持多种数据结构的NoSQL数据库SSDB,用于代理Redis。支持队列、hash、set、k-v对,支持T级别数据。是做分布式爬虫很好中间存储工具。
如何让爬虫更简单的使用这些代理?
答案肯定是做成服务咯,python有这么多的web框架,随便拿一个来写个api供爬虫调用。这样有很多好处,比如:当爬虫发现代理不能使用可以主动通过api去delete代理IP,当爬虫发现代理池IP不够用时可以主动去refresh代理池。这样比检测程序更加靠谱。
2、代理池设计
代理池由四部分组成:
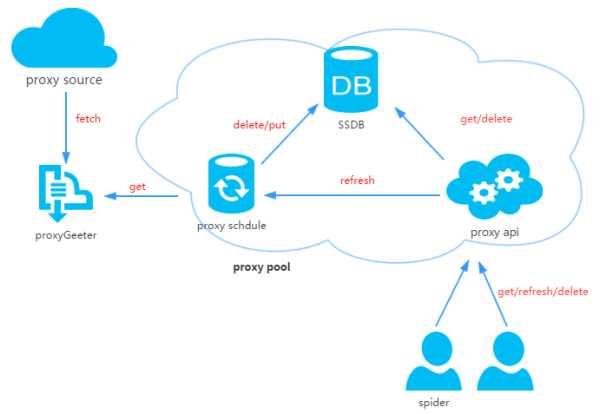
ProxyGetter:
代理获取接口,目前有5个免费代理源,每调用一次就会抓取这个5个网站的最新代理放入DB,可自行添加额外的代理获取接口;
DB:
用于存放代理IP,现在暂时只支持SSDB。至于为什么选择SSDB,大家可以参考这篇文章,个人觉得SSDB是个不错的Redis替代方案,如果你没有用过SSDB,安装起来也很简单,可以参考这里;
Schedule:
计划任务用户定时去检测DB中的代理可用性,删除不可用的代理。同时也会主动通过ProxyGetter去获取最新代理放入DB;
ProxyApi:
代理池的外部接口,由于现在这么代理池功能比较简单,花两个小时看了下Flask,愉快的决定用Flask搞定。功能是给爬虫提供get/delete/refresh等接口,方便爬虫直接使用。
3、代码模块
Python中高层次的数据结构,动态类型和动态绑定,使得它非常适合于快速应用开发,也适合于作为胶水语言连接已有的软件部件。用Python来搞这个代理IP池也很简单,代码分为6个模块:
Api:
api接口相关代码,目前api是由Flask实现,代码也非常简单。客户端请求传给Flask,Flask调用ProxyManager中的实现,包括get/delete/refresh/get_all;
DB:
数据库相关代码,目前数据库是采用SSDB。代码用工厂模式实现,方便日后扩展其他类型数据库;
Manager:
get/delete/refresh/get_all等接口的具体实现类,目前代理池只负责管理proxy,日后可能会有更多功能,比如代理和爬虫的绑定,代理和账号的绑定等等;
ProxyGetter:
代理获取的相关代码,目前抓取了快代理、代理66、有代理、西刺代理、guobanjia这个五个网站的免费代理,经测试这个5个网站每天更新的可用代理只有六七十个,当然也支持自己扩展代理接口;
Schedule:
定时任务相关代码,现在只是实现定时去刷新代码,并验证可用代理,采用多进程方式;
Util:
存放一些公共的模块方法或函数,包含GetConfig:读取配置文件config.ini的类,ConfigParse: 集成重写ConfigParser的类,使其对大小写敏感, Singleton:实现单例,LazyProperty:实现类属性惰性计算。等等;
其他文件:
配置文件:Config.ini,数据库配置和代理获取接口配置,可以在GetFreeProxy中添加新的代理获取方法,并在Config.ini中注册即可使用;
4、安装
下载代码:

或者直接到https://github.com/jhao104/proxy_pool 下载zip文件
安装依赖:

启动:
需要分别启动定时任务和api
到Config.ini中配置你的SSDB
到Schedule目录下:

到Api目录下:

5、使用
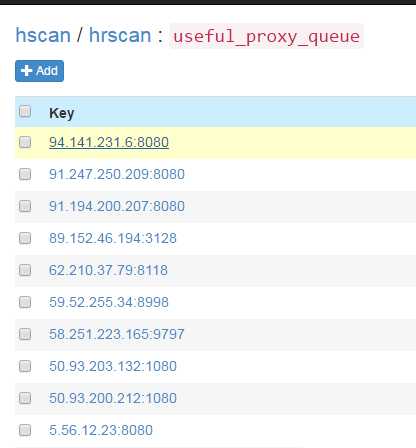
定时任务启动后,会通过代理获取方法fetch所有代理放入数据库并验证。此后默认每20分钟会重复执行一次。定时任务启动大概一两分钟后,便可在SSDB中看到刷新出来的可用的代理:
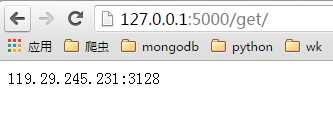
启动ProxyApi.py后即可在浏览器中使用接口获取代理,一下是浏览器中的截图:
get页面:
get_all页面:


爬虫中使用,如果要在爬虫代码中使用的话, 可以将此api封装成函数直接使用,例如:

6、最后
时间仓促,功能和代码都比较简陋,以后有时间再改进。喜欢的在github上给个star。感谢!
以上是关于python 爬虫 ip池怎么做的主要内容,如果未能解决你的问题,请参考以下文章