Java线程池
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java线程池相关的知识,希望对你有一定的参考价值。
为什么需要线程池?
- 对于需要频繁创建执行时间很短的线程的程序,创建线程的开销会很大,可以复用线程减少线程创建的开销
- 线程池限制了创建的线程个最大个数,避免了线程个数过多导致的资源耗尽、线程上下文频繁切换的等潜在问题
Java线程池实现——ThreadPoolExecutor
- 创建线程池
1 public ThreadPoolExecutor(int corePoolSize, 2 int maximumPoolSize, 3 long keepAliveTime, 4 TimeUnit unit, 5 BlockingQueue<Runnable> workQueue, 6 ThreadFactory threadFactory, 7 RejectedExecutionHandler handler)
corePoolSize:线程池核心线程个数。线程池在创建后默认情况下线程个数为0,当有新的任务到来时,如果池中当前线程个数小于corePoolSize,则创建一个新的线程。(tips:如果希望在线程池初始化时启动线程,可以调用prestartCoreThread()或者prestartAllCoreThreads()方法启动一个线程或者所有核心线程。)
maximumPoolSize:线程池最大线程个数
keepAliveTime:线程空闲时最大存活时间,默认情况下,keepAliveTime只对maximumPoolSize这部分的线程有效,如果希望keepAliveTime对corePoolSize线程也有效,可以调用allowCoreThreadTimeOut(boolean)方法。
unit:keepAliveTime的单位
workQueue:任务队列,这是一个阻塞队列(等价于非阻塞队列通过sychronized和wait/notify集成了同步以及empty/full判断的功能),用来保存来不及处理的任务。
threadFactory:线程创建工厂,线程池通过调用它的newThread方法创建新的线程,可以定义自己的线程创建工厂实现ThreadFactory接口。默认的ThreadFactory的newThread方法会给池中的线程命名。还记得我们在log日志中记录的当前线程名字吗?如果你的程序中使用了线程池,那么日志上打印的线程名字就是在这个方法里命名的。
handler:拒绝策略,当线程池的任务队列满了且线程个数达到最大线程个数的时候,需要对新到达的任务按拒绝策略处理。线程池中已经提供的拒绝策略有:
AbortPolicy——丢弃该任务,并抛出 RejectedExecutionException异常
DiscardPolicy——直接丢弃该任务
DiscardOldestPolicy——丢弃任务队列中最旧的任务,并尝试重新执行execute方法
CallerRunsPolicy——有调用线程执行该任务
默认情况下,线程池采用AbortPolicy,可以更改线程池的拒绝策略,也可以通过实现RejectedExecutionHandler接口定义自己的的拒绝策略。
- 线程池任务执行
我们先来直观了解一个任务被提交到线程池之后,他的执行流程:
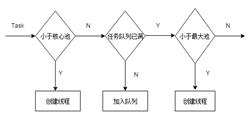
通过调用ThreadPoolExecutor类中execute()方法可以提交任务到线程池执行,另外submit()方法也可以向线程池提交任务,两者的区别在于execute()方法不关心任务的执行结果,而submit()方法可以得到任务的执行结果,并且其内部调用的也是execute()方法,因此我们重点分析execute()方法。源码奉上:
1 public void execute(Runnable command) { 2 if (command == null) 3 throw new NullPointerException(); 4 // 如果线程个数小于核心池大小,则创建核心线程 5 if (poolSize >= corePoolSize || !addIfUnderCorePoolSize(command)) { 6 // 如果线程个数大于等于核心池大小,则添加到任务队列 7 if (runState == RUNNING && workQueue.offer(command)) { 8 // 防止其他线程关闭了线程池,确保新加入的任务能得到执行 9 if (runState != RUNNING || poolSize == 0) 10 ensureQueuedTaskHandled(command); 11 //如果添加到任务队列失败(队列已满),且线程个数小于最大池,则创建最大池线程 12 } else if (!addIfUnderMaximumPoolSize(command)) 13 //如果任务队列和线程个数都达到上限,则采用拒绝策略 14 reject(command); // is shutdown or saturated 15 } 16 }
注意execute()方法调用的方法:
addInUderCorePoolSize
1 private boolean addIfUnderCorePoolSize(Runnable firstTask) { 2 Thread t = null; 3 final ReentrantLock mainLock = this.mainLock; 4 mainLock.lock(); 5 try { 6 // 同步判断线程个数是否小于核心池,小于则创建新线程 7 if (poolSize < corePoolSize && runState == RUNNING) 8 t = addThread(firstTask); 9 } finally { 10 mainLock.unlock(); 11 } 12 if (t == null) 13 return false; 14 t.start(); 15 return true; 16 }
addIfUnderMaximumPoolSize
private boolean addIfUnderMaximumPoolSize(Runnable firstTask) { Thread t = null; final ReentrantLock mainLock = this.mainLock; mainLock.lock(); try { // 同步判断线程个数是否小于最大池,小于则创建新线程 if (poolSize < maximumPoolSize && runState == RUNNING) t = addThread(firstTask); } finally { mainLock.unlock(); } if (t == null) return false; t.start(); return true; }
不难看出,addInUderCorePoolSize和addIfUnderMaximumPoolSize方法的实现代码非常相似,事实上他们的功能也基本相同———判断是否要创建新线程,如果需要则创建,否则返回false,区别在于创建线程的条件不同。并且,他们都调用了addThread()方法来创建线程,那么addThread()干了些什么呢?
private Thread addThread(Runnable firstTask) { // 创建一个工作任务Worker,实现了runnable接口 Worker w = new Worker(firstTask); // 使用worker创建工作线程 Thread t = threadFactory.newThread(w); if (t != null) { w.thread = t; // 将工作任务加入工作集 workers.add(w); // 线程个数增加 int nt = ++poolSize; if (nt > largestPoolSize) largestPoolSize = nt; } return t; }
上面的代码中,最重要是Worker对象,它实现了Runnable接口 ,并作为参数创建线程,看下Worker的主要代码:
1 private void runTask(Runnable task) { 2 final ReentrantLock runLock = this.runLock; 3 runLock.lock(); 4 try { 5 if (runState < STOP && 6 Thread.interrupted() && 7 runState >= STOP) 8 thread.interrupt(); 9 boolean ran = false; 10 // 可以通过重写此方法,做一些线程前置操作 11 beforeExecute(thread, task); 12 try { 13 task.run(); 14 ran = true; 15 // 可以通过重写此方法,做些线程后置操作 16 afterExecute(task, null); 17 ++completedTasks; 18 } catch (RuntimeException ex) { 19 if (!ran) 20 afterExecute(task, ex); 21 throw ex; 22 } 23 } finally { 24 runLock.unlock(); 25 } 26 } 27 28 public void run() { 29 try { 30 // 第一个task,也就是触发现成创建的task 31 Runnable task = firstTask; 32 firstTask = null; 33 // 循环从任务队列中取task 34 while (task != null || (task = getTask()) != null) { 35 // 执行task 36 runTask(task); 37 task = null; 38 } 39 } finally { 40 workerDone(this); 41 } 42 } 43 } 44 45 Runnable getTask() { 46 for (;;) { 47 try { 48 int state = runState; 49 // 如果是stop或者teminate状态,任务队列中的任务不会再处理,返回null 50 if (state > SHUTDOWN) 51 return null; 52 Runnable r; 53 // 如果是shutdown状态,处理完任务队列的任务,不会接受新任务 54 if (state == SHUTDOWN) 55 r = workQueue.poll(); 56 // 如果线程个数大于核心池或者核心线程允许超时,则取任务队列时加上超时时间 57 else if (poolSize > corePoolSize || allowCoreThreadTimeOut) 58 r = workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS); 59 // 否则取任务队列直至取到任务(阻塞) 60 else 61 r = workQueue.take(); 62 if (r != null) 63 return r; 64 if (workerCanExit()) { 65 if (runState >= SHUTDOWN) 66 interruptIdleWorkers(); 67 return null; 68 } 69 } catch (InterruptedException ie) { 70 } 71 } 72 }
上面的代码已经很清楚的展示线程池中每个工作线程是怎么运行的。工作线程启动后,首先执行本次提交的任务(代码中的firsttask),然后循环去任务队列读取新的待执行任务,可以根据线程池当前状态设置不同的读取队列元素的方式,如果读取队列失败,说明该工作线程处于空闲状态,可以关闭。
线程池使用
- 优先使用有界队列
- 线程池大小的选择
常见方法——计算密集型,设为CPU个数+1;IO密集型,设为2*CPU个数+1
精确计算——( IO等待时间/CPU计算时间 + 1 )* CPU个数
- 单例模式线程池封装类实例
1 public class ThreadPool { 2 private LinkedBlockingQueue<Runnable> queue = new LinkedBlockingQueue<Runnable>(100000);; 3 private ThreadPoolExecutor threadPoolExecutor; 4 // 被拒绝的任务计数,可能有多个线程向同一个线程池中添加任务,保证线程安全 5 private AtomicInteger rejectTaskNum = new AtomicInteger(0); 6 private static ThreadPool instance; 7 8 private ThreadPool() { 9 // 拒绝策略,是ThreadPoolExecutor的静态内部类,AbortPolicy策略拒绝任务并抛出RejectedExecutionException异常 10 threadPoolExecutor = new ThreadPoolExecutor(2 * Runtime.getRuntime().availableProcessors(), 4 * Runtime.getRuntime().availableProcessors(), 11 1000L, TimeUnit.MILLISECONDS, queue, new ThreadPoolExecutor.AbortPolicy()); 12 } 13 14 public static ThreadPool getInstace() { 15 // 第一个判断为了提高效率,不用每次都走同步判断,大多数情况下instance不为null,直接返回instance 16 if (instance == null) { 17 // 多线程创建单例时保证线程安全 18 synchronized (ThreadPool.class) { 19 if (instance == null) { 20 instance = new ThreadPool(); 21 } 22 } 23 } 24 return instance; 25 } 26 27 /** 28 * 如果在添加任务的过程中抛出RejectedExecutionException异常 ,说明触发拒绝策略 29 * 30 * @param task 31 * @return 32 */ 33 public boolean addTask(Runnable task) { 34 boolean reject = false; 35 try { 36 threadPoolExecutor.execute(task); 37 } catch (RejectedExecutionException e) { 38 rejectTaskNum.getAndIncrement(); 39 reject = true; 40 } 41 return reject; 42 } 43 44 /** 45 * 获取线程池中队列的剩余容量大小 46 * 47 * @return 48 */ 49 public int getRemaining() { 50 return queue.remainingCapacity(); 51 } 52 53 /** 54 * 获取线程池中当前的线程个数 55 * 56 * @return 57 */ 58 public int getPoolSize() { 59 return threadPoolExecutor.getPoolSize(); 60 } 61 62 /** 63 * 获取线程池从启动开始拒绝的任务个数 64 * 65 * @return 66 */ 67 public int getRejectTaskNum() { 68 return rejectTaskNum.get(); 69 } 70 71 }
以上是关于Java线程池的主要内容,如果未能解决你的问题,请参考以下文章