并发下的事务处理
Posted yxwkaifa
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了并发下的事务处理相关的知识,希望对你有一定的参考价值。
事务保障。是软件行业必需要做的事情。
非常多金融公司,就是因为事务处理不得当而倒闭。
我们都知道,事务有四大特性:ACID。即:原子性、一致性、隔离性、持久性。
四大特性
原子性
事务是数据库的逻辑单位,事务总包含的诸操作那么所有运行。要么都不运行。
ps:原子操作能保证线程安全。非原子操作就是线程不安全,通过使用锁或其它非阻塞方式实现某个时间仅仅能有一个线程操作同一个资源。
一致性
职务运行的结果,必须使数据库从一个一直状态、变到还有一个一直状态。
一致性与原子性紧密关联。
隔离性
一个事务的运行。不能被其它事务干扰
持久性
一个事务一旦提交。它对数据库中的数据改变就应该是永久性的。
这就是事务的四大特性。
隔离级别
以下,我们来详细来说一说隔离性
我们都知道,事务控制的太严格,程序在并发訪问的情况下,会减少程序的性能。
所以。人们总是想让事务为性能做出让步。那么就分出了四中隔离级别:
为提交读、提交读、反复读、序列化。
可是。因为隔离界别限制的程度不同,那么就会产生脏读、不可反复读、幻读的情况。
1. 脏读:脏读就是指当一个事务正在訪问数据,而且对数据进行了改动,而这样的改动还没有提交到数据库中,这时。另外一个事务也訪问这个数据,然后使用了这个数据。
2. 不可反复读:是指在一个事务内,多次读同一数据。在这个事务还没有结束时。另外一个事务也訪问该同一数据。那么,在第一个事务中的两次读数据之间,因为第二个事务的改动,那么第一个事务两次读到的的数据可能是不一样的。
这样就发生了在一个事务内两次读到的数据是不一样的,因此称为是不可反复读。比如。一个编辑人员两次读取同一文档,但在两次读取之间,作者重写了该文档。当编辑人员第二次读取文档时,文档已更改。
原始读取不可反复。
假设仅仅有在作者所有完毕编写后编辑人员才干够读取文档,则能够 避免该问题。
3.幻读:是指当事务不是独立运行时发生的一种现象,比如第一个事务对一个表中的数据进行了改动,这样的改动涉及到表中的所有数据行。同一时候。第二个事务也改动这个表中的数据。这样的改动是向表中插入一行新数据。那么,以后就会发生操作第一个事务的用户发现表中还有没有改动的数据行,就好象发生了幻觉一样。
比如。一个编辑人员更改作者提交的文档。但当生产部门将其更改内容合并到该文档的主复本时,发现作者已将未编辑的新材料加入到该文档中。
假设在编辑人员和生产部门完毕对原始文档的处理之前,不论什么人都不能将新材料加入到文档中,则能够避免该问题。
以下看数据库事务的隔离级别,由低到高依次为未提交读、提交读、反复读、序列化。
这四个级别能够逐个解决脏读、不可反复读、幻读这几类问题。
√:可能出现 ×:不会出现
|
|
脏读 |
不可反复读 |
幻读 |
|
Read uncommitted |
√ |
√ |
√ |
|
Read committed |
× |
√ |
√ |
|
Repeatable read |
× |
× |
√ |
|
Serializable |
× |
× |
× |
注意:我们讨论隔离级别的场景,主要是在多个事务并发的情况下,因此,接下来的解说都环绕事务并发。
未提交读
公司发工资了,领导把5000元打到singo的账号上,但是该事务并未提交,而singo正好去查看账户,发现工资已经到账,是5000元整。很高兴。但是不幸的是。领导发现发给singo的工资金额不正确。是2000元。于是迅速回滚了事务,改动金额后,将事务提交,最后singo实际的工资仅仅有2000元,singo空欢喜一场。
出现上述情况,即我们所说的脏读。两个并发的事务,“事务A:领导给singo发工资”、“事务B:singo查询工资账户”,事务B读取了事务A尚未提交的数据。
当隔离级别设置为Readuncommitted时,就可能出现脏读,怎样避免脏读。请看下一个隔离级别。
读提交
singo拿着工资卡去消费。系统读取到卡里确实有2000元。而此时她的老婆也正好在网上转账,把singo工资卡的2000元转到还有一账户,并在singo之前提交了事务,当singo扣款时,系统检查到singo的工资卡已经没有钱,扣款失败,singo十分纳闷,明明卡里有钱,为何......
出现上述情况,即我们所说的不可反复读。两个并发的事务,“事务A:singo消费”、“事务B:singo的老婆网上转账”。事务A事先读取了数据。事务B紧接了更新了数据,并提交了事务,而事务A再次读取该数据时,数据已经发生了改变。
当隔离级别设置为Readcommitted时,避免了脏读。可是可能会造成不可反复读。
大多数数据库的默认级别就是Readcommitted。比方Sql Server , Oracle。怎样解决不可反复读这一问题。请看下一个隔离级别。
反复读
当隔离级别设置为Repeatableread时。能够避免不可反复读。当singo拿着工资卡去消费时。一旦系统開始读取工资卡信息(即事务開始)。singo的老婆就不可能对该记录进行改动,也就是singo的老婆不能在此时转账。
尽管Repeatableread避免了不可反复读,但还有可能出现幻读。
singo的老婆工作在银行部门。她时常通过银行内部系统查看singo的信用卡消费记录。有一天,她正在查询到singo当月信用卡的总消费金额(select sum(amount) from transaction where month =本月)为80元。而singo此时正好在外面胡吃海塞后在收银台买单。消费1000元,即新增了一条1000元的消费记录(insert transaction... )。并提交了事务。随后singo的老婆将singo当月信用卡消费的明细打印到A4纸上。却发现消费总额为1080元,singo的老婆非常诧异,以为出现了幻觉。幻读就这样产生了。
注:mysql的默认隔离级别就是Repeatableread。
序列化
Serializable是最高的事务隔离级别。同一时候代价也花费最高,性能非常低,一般非常少使用,在该级别下,事务顺序运行,不仅能够避免脏读、不可反复读,还避免了幻像读。
PS:大多数数据库都是使用提交读。作为默认的隔离级别,如Oracle、SqlServer。
由于在数据量訪问的情况下,这样的方式性能较好,同一时候防止了脏读的情况发生。虽然有不可反复读的情况,可是在可承受的范围内。也有一些数据採用反复读。作为默认的隔离级别。假设採用默认配置。那么使用MySql的性能会稍低一些。
MySql隔离级别的默认配置实现,原理是数据訪问时加了读写锁,并发读取时,分别加锁。可是仅仅有第一个加锁的事务。才干改动事务,其它事务不能改动,它避免了可反复读的情况。
序列化相同是加锁,可是它加的是独占锁。不管哪个线程读取到数据,立刻会将其霸占,直至其操作完毕。这样的方式一致性高,可是并发性不好,非常少使用。
事务的传播特性
在开发中,我们一个action中,可能调用多个Service。那么这样的情况。是怎样保证事务的呢?事务的传播特性。以下我们来看看Spring事务的传播特性:
1. PROPAGATION_REQUIRED:支持当前事务,假设当前没有事务,就新建一个事务。这是最常见的选择。
2. PROPAGATION_SUPPORTS:支持当前事务,假设当前没有事务,就以非事务方式运行。
3. PROPAGATION_MANDATORY:支持当前事务,假设当前没有事务,就抛出异常。
4. PROPAGATION_REQUIRES_NEW:新建事务,假设当前存在事务,把当前事务挂起。
5. PROPAGATION_NOT_SUPPORTED:以非事务方式运行操作,假设当前存在事务,就把当前事务挂起。
6. PROPAGATION_NEVER:以非事务方式运行,假设当前存在事务,则抛出异常。
7. PROPAGATION_NESTED:支持当前事务。新增Savepoint点。与当前事务同步提交或回滚。
详细解释一下:
1. PROPAGATION_REQUIRED:增加当前正要执行的事务不在另外一个事务里,那么就起一个新的事务。
比方说,ServiceB.methodB的事务级别定义为PROPAGATION_REQUIRED,那么因为执行ServiceA.methodA的时候,ServiceA.methodA已经起了事务,这时调用ServiceB.methodB,ServiceB.methodB看到自己已经执行在ServiceA.methodA的事务内部。就不再起新的事务。
而假如ServiceA.methodA执行的时候发现自己没有在事务中,他就会为自己分配一个事务。这样,在ServiceA.methodA或者在ServiceB.methodB内的不论什么地方出现异常。事务都会被回滚。即使ServiceB.methodB的事务已经被提交。可是ServiceA.methodA在接下来fail要回滚。ServiceB.methodB也要回滚。
2. PROPAGATION_SUPPORTS:假设当前在事务中。即以事务的形式执行,假设当前不再一个事务中,那么就以非事务的形式执行。
3. PROPAGATION_MANDATORY:必须在一个事务中执行。
也就是说,他仅仅能被一个父事务调用。否则,他就要抛出异常。
4. PROPAGATION_REQUIRES_NEW:这个就比較绕口了。 比方我们设计ServiceA.methodA的事务级别为PROPAGATION_REQUIRED。ServiceB.methodB的事务级别为PROPAGATION_REQUIRES_NEW,那么当运行到ServiceB.methodB的时候,ServiceA.methodA所在的事务就会挂起。ServiceB.methodB会起一个新的事务。等待ServiceB.methodB的事务完毕以后,他才继续运行。
他与PROPAGATION_REQUIRED的事务差别在于事务的回滚程度了。由于ServiceB.methodB是新起一个事务,那么就是存在两个不同的事务。
假设ServiceB.methodB已经提交,那么ServiceA.methodA失败回滚,ServiceB.methodB是不会回滚的。
假设ServiceB.methodB失败回滚,假设他抛出的异常被ServiceA.methodA捕获。ServiceA.methodA事务仍然可能提交。
5. PROPAGATION_NOT_SUPPORTED:当前不支持事务。
比方ServiceA.methodA的事务级别是PROPAGATION_REQUIRED ,而ServiceB.methodB的事务级别是PROPAGATION_NOT_SUPPORTED 。那么当执行到ServiceB.methodB时。ServiceA.methodA的事务挂起,而他以非事务的状态执行完。再继续ServiceA.methodA的事务。
6. PROPAGATION_NEVER:不能在事务中执行。
如果ServiceA.methodA的事务级别是PROPAGATION_REQUIRED。 而ServiceB.methodB的事务级别是PROPAGATION_NEVER ,那么ServiceB.methodB就要抛出异常了。
7. PROPAGATION_NEST:理解Nested的关键是savepoint。
他与PROPAGATION_REQUIRES_NEW的差别是。PROPAGATION_REQUIRES_NEW另起一个事务,将会与他的父事务相互独立。 而Nested的事务和他的父事务是相依的。他的提交是要等和他的父事务一块提交的。
也就是说,假设父事务最后回滚。他也要回滚的。而Nested事务的优点是他有一个savepoint。也就是说ServiceB.methodB失败回滚,那么ServiceA.methodA也会回滚到savepoint点上,ServiceA.methodA能够选择另外一个分支,比方 ServiceC.methodC,继续运行。来尝试完毕自己的事务。 可是这个事务并没有在EJB标准中定义。
PS:我们最经常使用的传播特性就是PROPAGATION_REQUIRED。
支持当前事务,假设当前没有事务。就新建一个事务。
分布式事务
1.XA
XA 是由X/Open组织提出的分布式事务的规范。XA规范主要定义了(全局)事务管理器(Transaction Manager)和(局部)资源管理器(Resource Manager)之间的接口。XA接口是双向的系统接口。在事务管理器(Transaction Manager)以及一个或多个资源管理器(Resource Manager)之间形成通信桥梁。XA之所以须要引入事务管理器是由于。在分布式系统中,从理论上讲,两台机器理论上无法达到一致的状态,须要引入一个单点进行协调。事务管理器控制着全局事务,管理事务生命周期,并协调资源。
资源管理器负责控制和管理实际资源(如数据库或
JMS队列)。
2.JTA
作 为java平台上事务规范JTA(Java Transaction API)也定义了对XA事务的支持,实际上,JTA是基于XA架构上建模的。在JTA 中,事务管理器抽象为javax.transaction.TransactionManager接口。并通过底层事务服务(即JTS)实现。像非常多其它 的java规范一样,JTA只定义了接口,详细的实现则是由供应商(如J2EE厂商)负责提供。眼下JTA的实现主要由下面几种:
1.J2EE容器所提供的JTA实现(JBoss)
2.独立的JTA实现:如JOTM,Atomikos.这些实现能够应用在那些不使用J2EE应用server的环境里用以提供分布事事务保证。如Tomcat,Jetty以及普通的java应用。
3.两阶段提交
全部关于分布式事务的介绍中都必定会讲到两阶段提交,由于它是实现XA分布式事务的关键(确切地说:两阶段提交主要保证了分布式事务的原子性:即全部结点要么全做要么全不做)。
所谓的两个阶段是指:第一阶段:准备阶段和第二阶段:提交阶段。
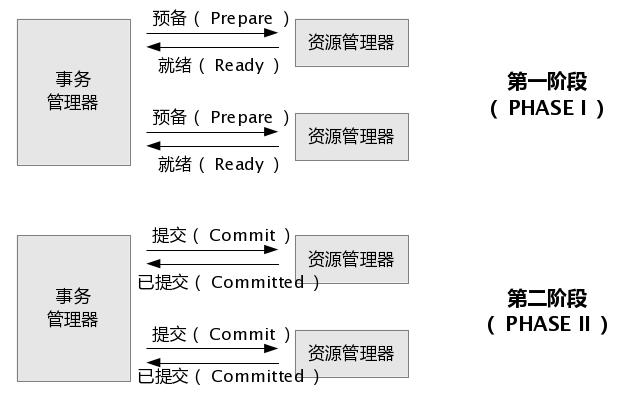
1.准备阶段: 事务协调者(事务管理器)给每一个參与者(资源管理器)发送Prepare消息,每一个參与者要么直接返回失败(如权限验证失败),要么在本地运行事务,写本 地的redo和undo日志,但不提交,到达一种“万事俱备。仅仅欠东风”的状态。(关于每一个參与者在准备阶段详细做了什么眼下我还没有參考到确切的资 料,可是有一点很确定:參与者在准备阶段完毕了差点儿全部正式提交的动作,有的材料上说是进行了“试探性的提交”。仅仅保留了最后一步耗时很短暂的正式提 交操作给第二阶段运行。)
2.提交阶段:假设协调者收到了參与者的失败消息或者超时,直接给每一个參与者发送回滚(Rollback)消息;否则,发送提交(Commit)消息;參与者依据协调者的指令运行提交或者回滚操作,释放全部事务处理过程中使用的锁资源。
(注意:必须在最后阶段释放锁资源)
总结二次提交:
将提交分成两阶段进行的目的很明白,就是尽可能晚地提交事务。让事务在提交前尽可能地完毕全部能完毕的工作,这样,最后的提交阶段将是一个耗时极短的微小操 作,这样的操作在一个分布式系统中失败的概率是很小的,也就是所谓的“网络通讯危急期”很的短暂。这是两阶段提交确保分布式事务原子性的关键所在。(唯 一理论上两阶段提交出现故障的情况是当协调者发出提交指令后当机并出现磁盘故障等永久性错误。导致事务不可追踪和恢复)
从两阶段提交的工 作方式来看。非常显然,在提交事务的过程中须要在多个节点之间进行协调。而各节点对锁资源的释放必须等到事务终于提交时。这样,比起一阶段提交。两阶段提交 在运行相同的事务时会消耗很多其它时间。事务运行时间的延长意味着锁资源发生冲突的概率添加,当事务的并发量达到一定数量的时候。就会出现大量事务积压甚至出 现死锁,系统性能就会严重下滑。这就是使用XA事务
4.一阶段提交(Best Efforts 1PC模式)
不像两阶段提交那样复杂。一阶段提交很直白。就是从应用程序向数据库发出提交请求到数据库完毕提交或回滚之后将结果返回给应用程序的过程。一阶段提交不需 要“协调者”角色。各结点之间不存在协调操作,因此其事务运行时间比两阶段提交要短。可是提交的“危急期”是每个事务的实际提交时间。相比于两阶段提 交,一阶段提交出如今“不一致”的概率就变大了。可是我们必须注意到:仅仅有当基础设施出现故障的时候(如网络中断,当机等),一阶段提交才可能会出现“不 一致”的情况,相比它的性能优势,许多团队都会选择这一方案。关于在spring环境下怎样实现一阶段提交,有一篇很优秀的文章值得參考:http://www.javaworld.com/javaworld/jw-01-2009/jw-01-spring-transactions.html?page=5
5.事务补偿机制
像best efforts 1PC这样的模式,前提是应用程序能获取全部的数据源,然后使用同一个事务管理器(这里指是的spring的事务管理器)管理事务。这样的模式最典型的应用场 景非数据库sharding莫属。可是对于那些基于web service/rpc/jms等构建的高度自治(autonomy)的分布式系统接口。best efforts 1PC模式是无能为力的,此类场景下,还有最后一种方法能够帮助我们实现“终于一致性”,那就是事务补偿机制。
关于事务补偿机制是一个大话题,本文仅仅简单 提及,以后会作专门的研究和介绍。
6.在基于两阶段提交的标准分布式事务和Best Efforts 1PC两者之间怎样选择
一 般而言,须要交互的子系统数量较少,而且整个系统在未来不会或非常少引入新的子系统且负载长期保持稳定。即无伸缩要求的话。考虑到开发复杂度和工作量。能够 选择使用分布式事务。
对于时间需求不是非常紧,对性能要求非常高的系统,应考虑使用Best Efforts 1PC或事务补偿机制。对于那些须要进行sharding改造的系统,基本上不应再考虑分布式事务,由于sharding打开了数据库水平伸缩的窗体,使 用分布式事务看起来好像是为新打开的窗体又加上了一把枷锁。
总结一下
事务的控制。是程序编写中必须进行的一步。我们编敲代码时。往往注意不到自己在使用事务。这是由于事务一般分为两种方式:编程式事务和声明式事务。
编程式事务尽管非常灵活,可是须要手动写JDBC模板式的代码来控制事务。所以我们不常常使用;我们常常使用声明式事务。以AOP的方式切入程序中,全然是基于配置的,在代码中没有体现,所以我们会看不到事务代码。
以上是关于并发下的事务处理的主要内容,如果未能解决你的问题,请参考以下文章