推荐算法学习笔记
Posted Donser
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了推荐算法学习笔记相关的知识,希望对你有一定的参考价值。
推荐算法举个简单的例子,比如有个用户进来看了一堆内容,我们把他看的所有的历史行为,嵌入到推荐引擎当中去。这个推荐引擎就会生成个性化的频道,下次这个用户再登录,或者都不用下一次,过几分钟之后,他看到的内容就会根据他最近发生的历史行为发生变化,这就是推荐系统的基本逻辑。这种方法叫基于用户行为的推荐,当然是有一定局限性的。比如你只有一个用户行为的时候,你就不知道他会不会看一个从来没人看过的内容,这其实就是长尾问题。当你可以积累越来越多的用户,用户的历史行为会有助于你对长尾内容的理解。
推荐系统本质是在用户需求不明确的情况下,解决信息过载的问题,联系用户和信息,一方面帮助用户发现对自己有价值的信息,另一方面让信息能够展现在对它感兴趣的用户面前,从而实现信息消费者和信息生产者的双赢(这里的信息的含义可以非常广泛,比如图书、电影和商品等,下文中统称为item)。
推荐系统实际上在为三类不同的利益相关方在服务:
第一个:用户。用户是为了能够更方便找到他想看的东西。
第二个:平台本身。平台希望连接服务提供商、内容提供商和用户,他希望赚钱。
第三个:内容提供商,因为内容提供商如果能有更多露出,他在这个渠道上,就会获得点击量或者/和品牌效应,那么他就可以通过一些方法变现,无论是广告的方法还是在一些离线渠道收买的方法。
所以一个推荐算法要同时服务三个利益各不相同的相关方,这本身导致了一个矛盾性。
解决方法之一是协同滤波,比如用一个 interactive 的方法train,两边互相学,然后收链,这是一个比较标准的方法:
Top picks for you 这是一个最标准的 record train,就是推荐 train。
第二个是 you may also like,你可能也会喜欢,这也是一个推荐的 train。
第三个就是一个子类别。比如说电影一般大的类别就是言情、动作片,其实这个类别还分了一些小类别,比如说这个叫做法庭判案,实际上是动作片下面的一个主类别,这个也可以用推荐算法来产生。
推荐引擎是用深度学习的方法,展示的有效性很大程度上是取决于你有没有打动用户,你要给她一个很好的理由,所以深度学习就是一个工具,可以用来做很多的事,掌握好这个工具,灵活性更大。
比如一些浅层的分布式表示模型。目前在文本领域,浅层分布式表示模型得到了广泛的使用,例如word2vec、GloVec等 。与传统词袋模型对比,词嵌入模型可以将词或者其他信息单元(例如短语、句子和文档等)映射到一个低维的隐含空间。在这个隐含空间中,每个信息单元的表示都是稠密的特征向量。词嵌入表示模型的基本思想实际还是上来自于传统的“Distributional semantics”,概括起来讲就是当前词的语义与其相邻的背景词紧密相关。因此,词嵌入的建模方法就是利用嵌入式表示来构建当前词和背景词之间的语义关联。相比多层神经网络,词嵌入模型的训练过程非常高效,而且实践效果很好、可解释性也不错,因此得到了广泛的应用。
-----------------------------------------------------------------------------------------------
基于背景或者特征的推荐 (Context-aware recommendation)
推荐系统的不断发展进一步丰富了可供推荐算法使用的信息。如对于新闻推荐,物品的属性则有可能是新闻的文本内容、关键词、时间等,同时包括用户的点击、收藏和浏览行为等等。在电商网站上,还可能包含很多信息评论文本(Review Text)、用户查看的历史记录、用户购买的记录等。还可能获得用户的反馈信息,总体上可以分为两类:一是显式的用户反馈(Explicit Feedback),这是用户对商品或信息给出的显式反馈信息,评分、评论属于该类;另一类是隐式的用户反馈(Implicit Feedback),这类一般是用户在使用网站的过程中产生的数据,它们也反映了用户对物品的喜好,比如用户查看了某物品的信息,用户在某一页面上的停留时间,等等。对于基于背景敏感的推荐,可以使用SVD++, SVDFeature , libFM 等基于特征的推荐算法。
复杂推荐任务
在真实的推荐中,往往要面临很多复杂的推荐任务。例如,基于session的推荐任务。在这个任务中,用户在一个时间片段内连续做出相应的操作和选择,需要连续考虑用户整体的兴趣偏好和在一个特定session内的行为。这种任务的解决方法往往和序列模型相关。另一种复杂任务叫做基于页面的推荐。上述所提到的推荐任务的返回结果都是一个单一列表,而实际上往往需要进行基于用户UI方面的结果展示。例如,在一个电商平台,如何将推荐产品合理地展示在页面的各个部分,可能的策略如按照类别分类展示、重点区域突出个性化推荐结果。这种任务目前在研究中还很少被关注,主要原因是很难得到相关的科研数据。
达观相关推荐的常用算法
1 Content-based相关推荐
基于内容的推荐一般依赖于一套好的标签系统,通过计算item之间tag集合的相似性来衡量item之间的相似性,一套好的标签系统需要各方面的打磨,一方面需要好的编辑,一方面也依赖于产品的设计,引导用户在使用产品的过程中,对item提供优质的tag。
2 基于协同过滤的相关推荐
协同过滤主要分为基于领域以及基于隐语义模型,上面也有将到。
基于领域的算法中,ItemCF是目前业界应用最多的算法,其主要思想为“喜欢item A的用户大都喜欢用户 item B”,通过挖掘用户历史的操作日志,利用群体智慧,生成item的候选推荐列表。主要统计2个item的共现频率,加以时间的考量,以及热门用户以及热门item的过滤以及降权。
LFM(latent factor model)隐语义模型是最近几年推荐系统领域最为热门的研究话题,该算法最早在文本挖掘领域被提出,用于找到文本隐含的语义,在推荐领域中,其核心思想是通过隐含特征联系用户和物品的兴趣。主要的算法有pLSA、LDA、matrix factorization(SVD,SVD++)等,这些技术和方法在本质上是相通的,以LFM为例,通过如下公式计算用户u对物品i的兴趣:
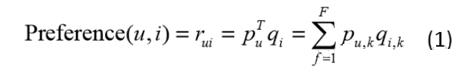
公式中pu,k和qi,k是模型的参数,其中pu,k度量了用户u的兴趣和第k个隐类的关系,而qi,k度量了第k个隐类和物品i之间的关系。而其中的qi,k可视为将item投射到隐类组成的空间中去,item的相似度也由此转换为在隐空间中的距离。
item2vec:NEURAL ITEM EMBEDDING
1 word2vec
2013年中,Google发布的word2vec工具引起了大家的热捧,很多互联网公司跟进,产出了不少成果。16年Oren Barkan以及Noam Koenigstein借鉴word2vec的思想,提出item2vec,通过浅层的神经网络结合SGNS(skip-gram with negative sampling)训练之后,将item映射到固定维度的向量空间中,通过向量的运算来衡量item之间的相似性。
2 item2vec
由于wordvec在NLP领域的巨大成功,Oren Barkan and Noam Koenigstein受此启发,利用item-based CF学习item在低维latent space的embedding representation,优化item的相关推荐。词的上下文即为邻近词的序列,很容易想到,词的序列其实等价于一系列连续操作的item序列,因此,训练语料只需将句子改为连续操作的item序列即可,item间的共现为正样本,并按照item的频率分布进行负样本采样。
-----------------------------------------------------------------------------------------------
本次软件工程设计任务涉及到了推荐算法,杰神派俺写推荐算法,首先简单分析一下,图书馆图书管理系统推荐书籍,
参考资料
https://www.ibm.com/developerworks/cn/web/1103_zhaoct_recommstudy1/index.html
以上是关于推荐算法学习笔记的主要内容,如果未能解决你的问题,请参考以下文章