词法分析器——哈工大编译原理课程
Posted 快乐的GTD吧
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了词法分析器——哈工大编译原理课程相关的知识,希望对你有一定的参考价值。
词法分析器——哈工大编译原理课程(一)
程序输入:从code.txt文件中读取内容
程序输出:识别出的单词序列,格式为:(种别码,属性值)
①对于关键字和运算符、分隔符来说,输出格式为(种别码,0),因为每个种别码能唯一地标识出是哪个单词
②对于标识符来说,输出格式为(id的种别码即36,在哈希桶中的位置)
③对于常量(整数、浮点数、字符串)来说,输出格式为(种别码,在数组中的位置)


1 #include<stdio.h>
2 #include<stdlib.h>
3 #include<ctype.h>
4 #include<string.h>
5 #include<math.h>
6 #include<de.h>
7 #define PRIME 211
8 #define EOS \'\\0\'
9 #define N 1000
10
11 typedef struct idnode{
12 char *name;
13 int kind; /*符号种类,如函数、形参等*/
14 int type; /*类型,如int、int*等*/
15 int firline;
16 struct idnode *next_hash; /*指向下一节点的指针*/
17 }Identifier;
18 Identifier *SymbolTable[PRIME] = {NULL};
19
20 char *string[500];
21 int pstr = -1;
22 int int_num[1000];
23 int pint = -1;
24 float real_num[1000];
25 int preal = -1;
26
27 int lexeme_beginning = 0; /*开始指针*/
28 int forward = 0; /*向前指针*/
29 char *buffer = NULL;
30
31 int hashpjw(char *s);
32 int insert_hash(char *idname);
33 int token_scan(int *temp);
34 void ReadFile();
35 char mgetchar();
36 char *copy_token(int flag);
37 int install_id(char *token);
38 int install_num(int token);
39 int install_real(float token);
40 float matof(char *token);
41 int install_string(char *token);
42 int check_ktable(char *token);
43 char *get_substr(char *token,int start,int end);
44 void error_handle();
45
46 int line = 1; /*行数*/
47 int flength;
48 int error[N][2];
49 int perr = 0;
50 char error_ch;
51
52 int main()
53 {
54 int i,temp[2];
55 ReadFile();
56 i = token_scan(temp);
57 if(i == 0)
58 {
59 printf("(%d,%d)\\n",temp[0],temp[1]);
60 }
61
62 while(i>-2 && forward<flength)
63 {
64 lexeme_beginning = forward;
65 i = token_scan(temp);
66 if(i == 0)
67 {
68 printf("(%d,%d)\\n",temp[0],temp[1]);
69 }
70 }
71
72 error_handle();
73 return 0;
74 }
75
76 int token_scan(int *temp)
77 {
78 char ch;
79 char *token;
80 int count = 0;
81 float token_num;
82 int comment_line;
83
84 ch = mgetchar();
85 while(ch == \' \'||ch == \'\\t\'||ch == \'\\n\')
86 {
87 if(ch == \'\\n\')
88 {
89 line++;
90 }
91 ch = mgetchar(); /*forward总比ch多一,ch和lexeme_begin指向同一个*/
92 lexeme_beginning++;
93 }
94
95 if(ch == \'{\')
96 {
97 comment_line = line;
98 ch = mgetchar();
99 lexeme_beginning++;
100 if(ch == \'}\')
101 {
102 return -1;
103 }
104 else if(ch == \'*\')
105 {
106 while(1)
107 {
108 while(ch != \'*\')
109 {
110 if(ch ==\'\\0\')
111 {
112 printf("Line %d ERROR:unterminated comment!\\n",comment_line);
113 return -2;
114 }
115 ch = mgetchar();
116 lexeme_beginning++;
117 if(ch == \'\\n\')
118 {
119 line++;
120 }
121 }
122 ch = mgetchar();
123 lexeme_beginning++;
124 if(ch == \'\\n\')
125 {
126 line++;
127 }
128 if(ch == \'}\')
129 {
130 return -1;
131 }
132 }
133
134 }
135 else
136 {
137 while(ch != \'}\'&&ch != \'\\0\'&&ch != \'\\n\')
138 {
139 ch = mgetchar();
140 lexeme_beginning++;
141 }
142 if(ch == \'\\n\')
143 {
144 if(perr < N)
145 {
146 error[perr][0] = 6;
147 error[perr][1] = line;
148 perr++;
149 return 1;
150 }
151 else
152 {
153 printf("Too much Error!Please check your program!\\n");
154 return -2;
155 }
156 }
157 if(ch == \'\\0\')
158 {
159 printf("Line %d ERROR:unterminated comment!\\n",comment_line);
160 return -2;
161 }
162 return -1;
163 }
164 }
165
166 if(isalpha(ch)) /*标识符类型*/
167 {
168 ch = mgetchar();
169 count++;
170 while(isalpha(ch)||isdigit(ch))
171 {
172 ch = mgetchar();
173 count++;
174 }
175 if(count > 127) /*最大长度为127*/
176 {
177 if(perr < N)
178 {
179 error[perr][0] = 1;
180 error[perr][1] = line;
181 perr++;
182 }
183 else
184 {
185 printf("Too much Error!Please check your program!\\n");
186 return -2;
187 }
188 /*printf("Line %d ERROR:Too long identifier!\\n",line);*/
189 }
190
191 forward--; /*forward指向other字符*/
192 token = copy_token(0);
193 printf("%s ",token);
194 if(check_ktable(token) != -1)
195 {
196 temp[0] = check_ktable(token); /*种别*/
197 temp[1] = 0; /*属性值*/
198 return 0;
199 }
200 else
201 {
202 temp[0] = ID; /*种别*/
203 temp[1] = install_id(token); /*属性值*/
204 if(temp[1] == -1)
205 {
206 return 1;
207 }
208 return 0;
209 }
210 }
211
212 if(isdigit(ch)) /*无符号整数与无符号浮点数(含科学计数法)*/
213 {
214 ch = mgetchar();
215 while(isdigit(ch))
216 {
217 ch = mgetchar();
218 }
219 if(ch == \'.\')
220 {
221 ch = mgetchar();
222 if(isdigit(ch))
223 {
224 ch = mgetchar();
225 while(isdigit(ch))
226 {
227 ch = mgetchar();
228 }
229 if(ch != \'E\')
230 {
231 forward--;
232 token = copy_token(1);
233 temp[0] = REAL;
234 temp[1] = install_real(atof(token));
235 printf("%f ",atof(token));
236 return 0;
237 }
238 }
239 else
240 {
241 forward--;
242 if(perr < N)
243 {
244 error[perr][0] = 2;
245 error[perr][1] = line;
246 perr++;
247 return 1;
248 }
249 else
250 {
251 printf("Too much Error!Please check your program!\\n");
252 return -2;
253 }
254 /*printf("Line %d ERROR:Illeagle float num!\\n",line);*/
255 }
256 }
257
258 if(ch == \'E\')
259 {
260 ch = mgetchar();
261 if(ch == \'+\' || ch == \'-\')
262 {
263 ch = mgetchar();
264 if(!isdigit(ch))
265 {
266 forward--;
267 if(perr < N)
268 {
269 error[perr][0] = 2;
270 error[perr][1] = line;
271 perr++;
272 return 1;
273 }
274 else
275 {
276 printf("Too much Error!Please check your program!\\n");
277 return -2;
278 }
279 /*printf("Line %d ERROR:Illeagle float num!\\n",line);*/
280 }
281 }
282 if(isdigit(ch))
283 {
284 ch = mgetchar();
285 while(isdigit(ch))
286 {
287 ch = mgetchar();
288 }
289 forward--;
290 token = copy_token(1);
291 token_num = matof(token); /*token_num为浮点数类型*/
292 temp[0] = REAL;
293 temp[1] = install_real(token_num);
294 printf("%f ",token_num);
295 return 0;
296 }
297 else
298 {
299 forward--;
300 if(perr < N)
301 {
302 error[perr][0] = 2;
303 error[perr][1] = line;
304 perr++;
305 return 1;
306 }
307 else
308 {
309 printf("Too much Error!Please check your program!\\n");
310 return -2;
311 }
312 }
313 }
314
315 forward--;
316 token = copy_token(1);
317 temp[0] = INT;
318 temp[1] = install_num(atoi(token));
319 printf("%d ",atoi(token));
320 return 0;
321 /*
322 forward--;
323 token = copy_token(1);
324 temp[0] = INT;
325 temp[1] = install_num(token);
326 */
327 }
328
329 switch(ch) /*运算符*/
330 {
331 case \'+\':
332 {
333 temp[0] = PLUS;
334 temp[1] = 0;
335 return 0;
336 break;
337 }
338 case \'-\':
339 {
340 temp[0] = MINUS;
341 temp[1] = 0;
342 return 0;
343 break;
344 }
345 case \'/\':
346 {
347 temp[0] = RDIV;
348 temp[1] = 0;
349 return 0;
350 break;
351 }
352 case \'*\':
353 {
354 ch = mgetchar();
355 if(ch == \'*\')
356 {
357 temp[0] = EXP;
358 temp[1] = 0;
359 }
360 else
361 {
362 forward--;
363 temp[0] = MULTI;
364 temp[1] = 0;
365 }
366 return 0;
367 break;
368 }
369 case \'=\':
370 {
371 temp[0] = EQ;
372 temp[1] = 0;
373 return 0;
374 break;
375 }
376 case \'<\':
377 {
378 ch = mgetchar();
379 if(ch == \'=\')
380 {
381 temp[0] = LE;
382 temp[1] = 0;
383 }
384 else if(ch == \'>\')
385 {
386 temp[0] = NE;
387 temp[1] = 0;
388 }
389 else
390 {
391 forward--;
392 temp[0] = LT;
393 temp[1] = 0;
394 }
395 return 0;
396 break;
397 }
398 case \'>\':
399 {
400 ch = mgetchar();
401 if(ch == \'=\')
402 {
403 temp[0] = GE;
404 temp[1] = 0;
405 }
406 else
407 {
408 forward--;
409 temp[0] = GT;
410 temp[1] = 0;
411 }
412 return 0;
413 break;
414 }
415 case \'(\':
416 {
417 temp[0] = LR_BRAC;
418 temp[1] = 0;
419 return 0;
420 break;
421 }
422 case \')\':
423 {
424 temp[0] = RR_BRAC;
425 temp[1] = 0;
426 return 0;
427 break;
428 }
429 case \',\':
430 {
431 temp[0] = COMMA;
432 temp[1] = 0;
433 return 0;
434 break;
435 }
436 case \'`\': /*编码表里的P_MARK是啥?顿号?*/
437 {
438 temp[0] = P_MARK;
439 temp[1] = 0;
440 return 0;
441 break;
442 }
443 case \'.\':
444 {
445 ch = mgetchar();
446 if(ch == \'.\')
447 {
448 temp[0] = RANGE;
449 temp[1] = 0;
450 }
451 else
452 {
453 forward--;
454 temp[0] = F_STOP;
455 temp[1] = 0;
456 }
457 return 0;
458 break;
459 }
460 case \':\':
461 {
462 ch = mgetchar();
463 if(ch == \'=\')
464 {
465 temp[0] = ASSIGN;
466 temp[1] = 0;
467 }
468 else
469 {
470 forward--;
471 temp[0] = COLON;
472 temp[1] = 0;
473 }
474 return 0;
475 break;
476 }
477 case \';\':
478 {
479 temp[0] = SEMIC;
480 temp[1] = 0;
481 return 0;
482 break;
483 }
484 case \'^\':
485 {
486 temp[0] = CAP;
487 temp[1] = 0;
488 return 0;
489 break;
490 }
491 case \'[\':
492 {
493 temp[0] = LS_BRAC;
494 temp[1] = 0;
495 return 0;
496 break;
497 }
498 case \']\':
499 {
500 temp[0] = RS_BRAC;
501 temp[1] = 0;
502 return 0;
503 break;
504 }
505 case \'\\\'\':
506 {
507 ch = mgetchar();
508 while(ch != \'\\\'\')
509 {
510 ch = mgetchar();
511 if(ch == \'\\0\')
512 {
513 if(perr < N)
514 {
515 error[perr][0] = 3;
516 error[perr][1] = line;
517 perr++;
518 return 1;
519 }
520 else
521 {
522 printf("Too much Error!Please check your program!\\n");
523 return -2;
524 }
525 /*printf("Line %d ERROR:No end of string!\\n",line);*/
526 return 1;
527 }
528 }
529 token = copy_token(1);
530 printf("%s ",token);
531 temp[0] = STRING;
532 temp[1] = install_string(token);
533 return 0;
534 break;
535 }
536 case \'\\0\':
537 {
538 return -2;
539 break;
540 }
541 default:
542 {
543 if(perr < N)
544 {
545 error[perr][0] = 4;
546 error[perr][1] = line;
547 error_ch = ch;
548 perr++;
549 return 1;
550 }
551 else
552 {
553 printf("Too much Error!Please check your program!\\n");
554 return -2;
555 }
556 /*printf("Line %d ERROR:Illegal char \'%c\'\\n",line,ch);*/
557 }
558 }
559 }
560
561 void ReadFile()
562 {
563 FILE *pfile;
564
565 pfile = fopen("code.txt", "r");
566 if (pfile == NULL)
567 {
568 printf("Open file ERROR!\\n");
569 exit(0);
570 }
571 fseek(pfile, 0, SEEK_END);
572 flength = ftell(pfile);
573 buffer = (char *)malloc((flength + 1) * sizeof(char));
574 rewind(pfile);
575 flength = fread(buffer, 1, flength, pfile);
576 buffer[flength] = \'\\0\';
577 fclose(pfile);
578 }
579
580 char mgetchar()
581 {
582 char ch = *(buffer + forward);
583 forward++;
584 return ch;
585 }
586
587 char *copy_token(int flag)
588 {
589 int length = forward - lexeme_beginning; /*要拷贝的字符串长度*/
590 char* token = (char*)calloc(sizeof(char),length+1);
591 char* pcode = buffer + lexeme_beginning;
592 int i;
593
594 if(flag == 0 && length > 63)
595 {
596 if(perr < N)
597 {
598 error[perr][0] = 5;
599 error[perr][1] = line;
600 perr++;
601 }
602 else
603 {
604 printf("Too much Error!Please check your program!\\n");
605 }
606 /*printf("Line %d Warning:identifier will be cut off!\\n",line);*/
607 for(i=0;i<63;i++)
608 {
609 token[i]=*pcode;
610 pcode++;
611 }
612 token[63]=\'\\0\'; /*加上字符串结束符*/
613 }
614 else
615 {
616 for(i=0;i<length;i++)
617 {
618 token[i]=*pcode;
619 pcode++;
620 }
621 token[length]=\'\\0\'; /*加上字符串结束符*/
622 }
623 return token; /*返回分配的字符数组地址 */
624 }
625
626 int install_id(char *token)
627 {
628 int hash_ret = insert_hash(token);
629 if(hash_ret == 0)
630 {
631 return hashpjw(token);
632 }
633 printf("Line %d Error:There is a Same name!\\n",hash_ret);
634 return -1;
635
636 }
637
638 float matof(char *token)
639 {
640 int i;
641 float before;
642 int after;
643 int l = strlen(token);
644 for(i = 0;i < l;i++)
645 {
646 if(token[i] == \'E\')
647 {
648 before = atof(get_substr(token,0,i));
649 if(token[i+1] == \'+\')
650 {
651 after = atoi(get_substr(token,i+2,l));
652 return before*pow(10,after);
653 }
654 else if(token[i+1] == \'-\')
655 {
656 after = atoi(get_substr(token,i+2,l));
657 return before*pow(10,-after);
658 }
659 else
660 {
661 after = atoi(get_substr(token,i+1,l));
662 return before*pow(10,after);
663 }
664 }
665 }
666 return atof(token);
667 }
668
669 int install_num(int token)
670 {
671 pint++;
672 int_num[pint] = token;
673 return pint;
674
675 }
676
677 int install_real(float token)
678 {
679 preal++;
680 real_num[preal] = token;
681 return preal;
682 }
683
684 int install_string(char *token)
685 {
686 pstr++;
687 string[pstr] = token;
688 return pstr;
689 }
690
691 int check_ktable(char *token)
692 {
693 int i;
694 for(i=1;i<36;i++)
695 {
696 if(strcmp(key_table[i],token) == 0)
697 {
698 return i;
699 }
700 }
701 return -1;
702 }
703
704 char *get_substr(char *token,int start,int end) /*含左不含右*/
705 {
706 int length = end - start; /*要拷贝的字符串长度*/
707 char* ret = (char*)calloc(sizeof(char),length+1);
708 char* pcode = token + start;
709 int i;
710
711 for(i=0;i<length;i++)
712 {
713 ret[i]=*pcode;
714 pcode++;
715 }
716 ret[length]=\'\\0\'; /*加上字符串结束符*/
717 return ret; /*返回分配的字符数组地址 */
718 }
719
720 int insert_hash(char *idname)
721 {
722 int ret;
723 Identifier *id = (Identifier*)malloc(sizeof(Identifier)),*p,*pb;
724
725 ret = hashpjw(idname);
726 id->name = idname;
727 id->firline = line;
728
729 p = SymbolTable[ret];
730
731 if(p == NULL||strcmp(p->name,idname)>0)
732 {
733 id->next_hash = p;
734 SymbolTable[ret] = id;
735 return 0;
736 }
737
738 while(p != NULL)
739 {
740 if(strcmp(p->name,idname) < 0)
741 {
742 pb = p;
743 p = p->next_hash;
744 }
745 else
746 {
747 break;
748 }
749 }
750
751 if(p == NULL)
752 {
753 id->next_hash = NULL;
754 pb->next_hash = id;
755 return 0;
756 }
757 else if(strcmp(p->name,idname)>0)
758 {
759 id->next_hash = p;
760 pb->next_hash = id;
761 return 0;
762 }
763 else
764 {
765 /*出错处理*/
766 /*return p->firline;*/
767 return 0;
768 }
769 }
770
771 int hashpjw(char *s)
772 {
773 char *p;
774 unsigned h = 0,g;
775 for(p = s;*p!=EOS;p=p+1)
776 {
777 h = (h<<4) + (*p);
778 if((g = (h & 0xF0000000)))
779 {
780 h = h^(g>>24);
781 h = h^g;
782 }
783 }
784 return h % PRIME;
785 }
786
787 void error_handle()
788 {
789 int i;
790 for(i = 0;i < perr;i++)
791 {
792 switch(error[i][0])
793 {
794 case 1:
795 {
796 printf("Line %d ERROR:Too long identifier!\\n",error[i][1]);
797 break;
798 }
799 case 2:
800 {
801 printf("Line %d ERROR:Illeagle float num!\\n",error[i][1]);
802 break;
803 }
804 case 3:
805 {
806 printf("Line %d ERROR:No end of string!\\n",error[i][1]);
807 break;
808 }
809 case 4:
810 {
811 printf("Line %d ERROR:Illegal char \'%c\'\\n",error[i][1],error_ch);
812 break;
813 }
814 case 5:
815 {
816 printf("Line %d Warning:identifier will be cut off!\\n",error[i][1]);
817 break;
818 }
819 case 6:
820 {
821 printf("Line %d ERROR:unterminated comment!\\n",error[i][1]);
822 break;
823 }
824 default:
825 {
826 continue;
827 }
828 }
829 }
830 }
1 #define ID 36
2 #define INT 37
3 #define REAL 38
4 #define STRING 39
5 #define PLUS 40
6 #define MINUS 41
7 #define MULTI 42
8 #define RDIV 43
9 #define EQ 44
10 #define LT 45
11 #define GT 46
12 #define LE 47
13 #define GE 48
14 #define NE 49
15 #define LR_BRAC 50
16 #define RR_BRAC 51
17 #define COMMA 52
18 #define P_MARK 53
19 #define F_STOP 54
20 #define RANGE 55
21 #define COLON 56
22 #define ASSIGN 57
23 #define SEMIC 58
24 #define CAP 59
25 #define EXP 60
26 #define LS_BRAC 61
27 #define RS_BRAC 62
28 #define Q_MARK 63
29
30 char* key_table[36] = {"","and","array","begin","case","const","div","do","downto","else",
31 "end","file","for","function","goto","if","in","label","mod","nil","not","of","or",
32 "packed","procedure","program","record","repeat","set","then","to","type","until",
33 "var","while","with"};
一、支持类型
能识别关键字、标识符、常量(整常数、浮常数、字符串)、运算符、分隔符。能处理单行和多行注释。支持识别的各单词种别码及宏定义如下表
|
单词 |
种别码 |
宏 |
单词 |
种别码 |
宏 |
单词 |
种别码 |
宏 |
|
and |
1 |
AND |
Or |
22 |
OR |
/ |
43 |
RDIV |
|
array |
2 |
ARRAY |
Packed |
23 |
PACKED |
= |
44 |
EQ |
|
begin |
3 |
BEGIN |
procedure |
24 |
PROC |
< |
45 |
LT |
|
case |
4 |
CASE |
Program |
25 |
PROG |
> |
46 |
GT |
|
const |
5 |
CONST |
Record |
26 |
RECORD |
<= |
47 |
LE |
|
div |
6 |
DIV |
Repeat |
27 |
REPEAT |
>= |
48 |
GE |
|
do |
7 |
DO |
Set |
28 |
SET |
<> |
49 |
NE |
|
downto |
8 |
DOWNTO |
Then |
29 |
THEN |
( |
50 |
LA_BRAC |
|
else |
9 |
ELSE |
To |
30 |
TO |
) |
51 |
BR_BRAC |
|
end |
10 |
END |
Type |
31 |
TYPE |
, |
52 |
COMMA |
|
file |
11 |
FILE |
Until |
32 |
UNTIL |
、 |
53 |
P_MARK |
|
for |
12 |
FOR |
Car |
33 |
CAR |
. |
54 |
F_STOP |
|
function |
13 |
FUNC |
While |
34 |
WHILE |
.. |
55 |
RANGE |
|
goto |
14 |
GOTO |
With |
35 |
WITH |
: |
56 |
COLON |
|
if |
15 |
IF |
标识符 |
36 |
ID |
:= |
57 |
ASSIGN |
|
in |
16 |
IN |
整常数 |
37 |
INT |
; |
58 |
SEMIC |
|
label |
17 |
LABEL |
实常数 |
38 |
REAL |
^ |
59 |
CAP |
|
mod |
18 |
MOD |
字符串 |
39 |
STRING |
** |
60 |
EXP |
|
nil |
19 |
NIL |
+ |
40 |
PLUS |
[ |
61 |
LS_BRAC |
|
not |
20 |
NOT |
- |
41 |
MINUS |
] |
62 |
RS_BRAC |
|
of |
21 |
OF |
* |
|
MULTI |
‘ |
63 |
Q_MARK |
二、各种成分的定义
1、关键字
标准Pascal定义的35个关键字,表中种别码为1~35的单词
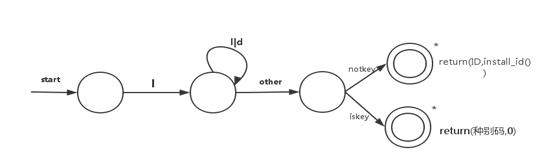
2、标识符
以字母开头的字母数字串。最长由127个字符组成,但只有前63个字符有效,多余部分将被截断;其中不允许有空格
状态转换图
3、常量
①整常数
十进制无符号整数,如11
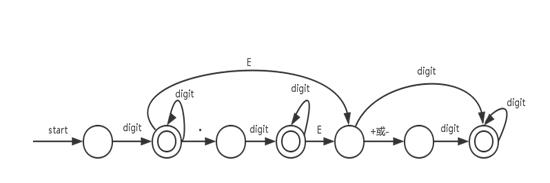
②实常数
十进制无符号浮点数,支持科学计数法的表示形式,如11.2、11E2、11E+2、11E-2、11.3E+2
、11.3E-2等
状态转换图
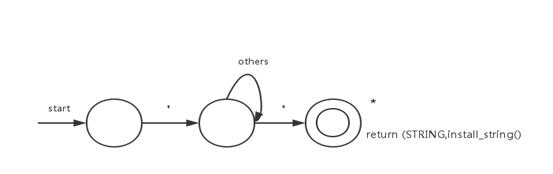
③字符串
用单引号””引起来的字符序列,如\'Hello, world.\'等,最大长度为1024(data_struct.h定义)
4、运算符及分隔符
如上表种别码为40~63的单词
5、注释
单行注释{…}
多行注释{*…\\n…\\n…*}
三、错误提示
1、标识符长度超出127,提示:Line 行数 ERROR:Too long identifier!
2、标识符长度超过63,警告:Line 行数 Warning:identifier will be cut off!
3、浮点数格式不合法,如32.、32.E、32E+等,提示:Line 行数 ERROR:Illeagle float num!
4、字符串只有一个单引号,无另一个时,提示:Line 行数ERROR:No end of string!
5、程序中出现非法字符,提示:Line 行数 ERROR:Illegal char \'%c\'
6、注释不闭合,提示:Line 行数ERROR:unterminated comment!
四、程序说明与算法
程序指定读取文件code.txt,去掉其中的空格和注释,将其切分成一个个形如(种别码,属性值)的单词符号,输出到lex.txt中,若遇到错误,将其存入错误类型数组中,继续进行分析,这样做不会使分析到一个错误就终止程序,可以将整个分析扫描一遍,找出其中所有的错误,使用户使用起来更方便。
五、测试程序和运行截图
测试程序code.txt
program SumAverage;
{This is a program which gets the average of five numbers.}
const
NumberOfIntegers = 5;
var
A, B, C, D, E : integer;
Sum : integer;
Average,t : real;
{*test
comment*}
begin
A := 45;
B := 7;
C := 68;
D := 2;
E := 34;
Sum := A + B + C + D + E;
Average := Sum / NumberOfIntegers;
t := 11.3E+2;
writeln (\'Number of integers = \', NumberOfIntegers);
writeln (\'Number1 = \', A);
writeln (\'Number2 = \', B);
writeln (\'Number3 = \', C);
writeln (\'Number4 = \', D);
writeln (\'Number5 = \', E);
writeln (\'Sum = \', Sum);
writeln (\'Average = \', Average)
end.
运行结果截图(词法分析器在总体结构中不会打印此部分)
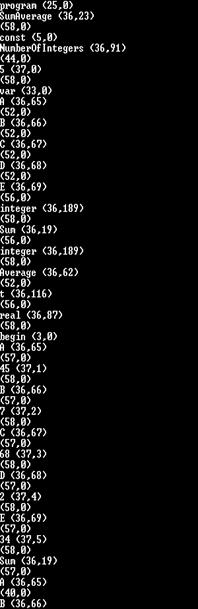
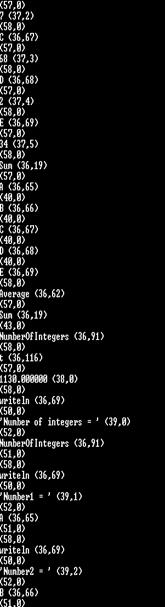
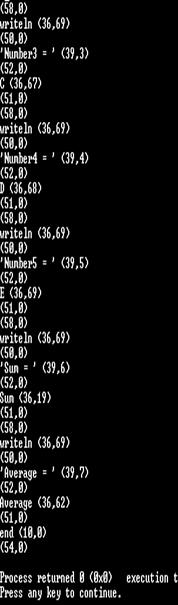
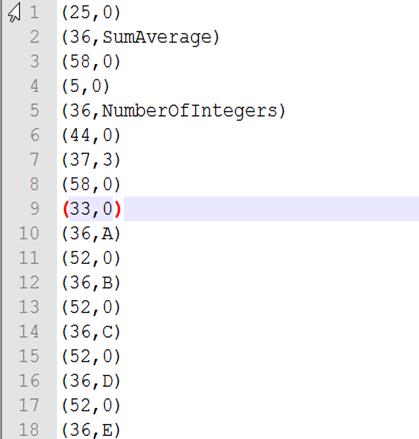
Lex.txt部分截图

以上是关于词法分析器——哈工大编译原理课程的主要内容,如果未能解决你的问题,请参考以下文章