分布式机器学习的集群方案介绍之HPC实现
Posted 容器技术爱好者
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式机器学习的集群方案介绍之HPC实现相关的知识,希望对你有一定的参考价值。
机器学习的基本概念
机器学习方法是计算机利用已有的数据(经验),得出了某种模型(迟到的规律),并利用此模型预测未来(是否迟到)的一种方法。目前机器学习广泛应用于广告投放、趋势预测、图像识别、语音识别、自动驾驶和产品推荐等众多领域。

在确定了问题模型之后,根据已知数据寻找模型参数的过程就是训练,训练过程就是不断依据训练数据来调整参数的迭代,从而使依据模型作出的预测结果更加准确。

HPC的基本概念
HPC就是高性能计算或高性能计算集群的简写。为了追求高性能,HPC的工作负载一般直接运行在Linux系统上,有些甚至直接在裸机上运行。HPC应用一般将问题分解为可在集群节点上运行的较小的、并行的分布式问题。HPC应用通常大量使用进程间通信,通信通过共享存储或网络实现。HPC系统中同时运行着大量的应用,这些应用可通过集群调度系统进行管理。
以前HPC的主要应用是科学计算,近年来随着深度学习技术的发展,HPC上运行的深度学习应用也在增加。HPC的典型应用包括:
- 高能物理模拟
- 天气建模预测
- 流体、结构、材料分析
- 电磁与热力学模拟
- 沉积与储层模拟
- 3D渲染与可视化
- 深度学习的训练与预测
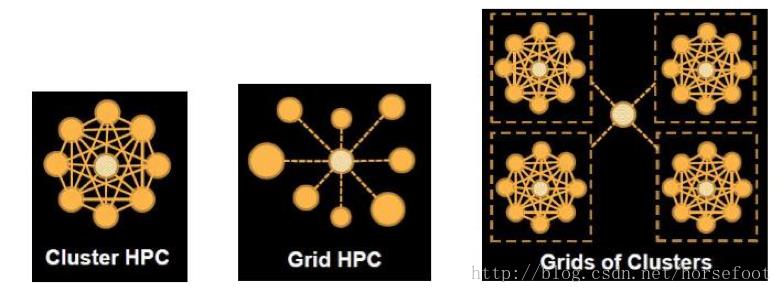
完整部署一套HPC系统是相当复杂的过程,要综合考虑到安全、能源、散热、网络等诸多方面问题。
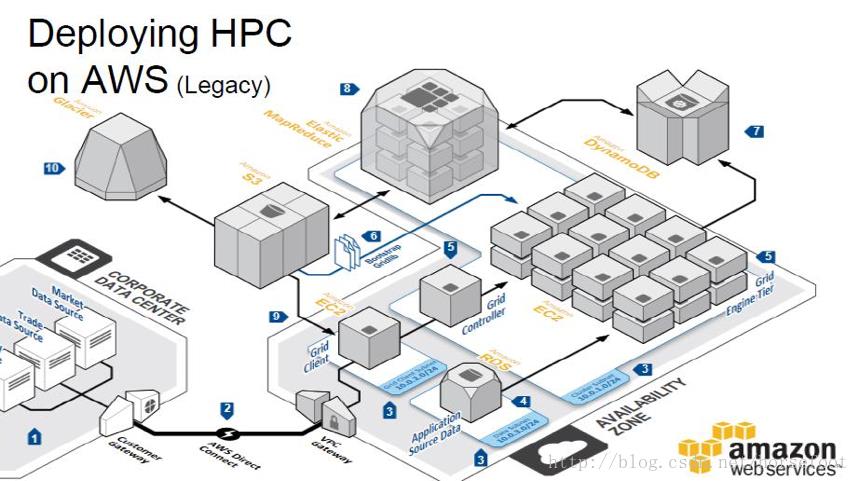
为什么需要分布式机器学习
大数据时代的机器学习有如下趋势:
Big Model 随着深度学习的进展,许多问题需要一个大的模型,这个模型必须有能力去尽量接近你所要解决问题的具体功能。例如,将图片内容用文字描述出来这个功能是非常复杂的,要表达这个功能需要非常多的参数,这个问题的模型必须要足够大才能实现这样复杂的功能。
Big Data 在训练的数据集较小时,深度学习的效果并不理想,这也是前些年深度学习没有引起大家重视的一个原因。在小数据集上训练的深度学习模型效果还不如一些相对简单的机器学习方法,不过当数据集增大之后,深度学习的效果开始超过其它机器学习方法。在语音识别上的研究表明,如果训练数据集的规模增加10倍,语音识别的误差率会相对降低约40%。HPC有能力使用更大的数据集来训练模型,因而也成为人工智能发展的一个重要部分。
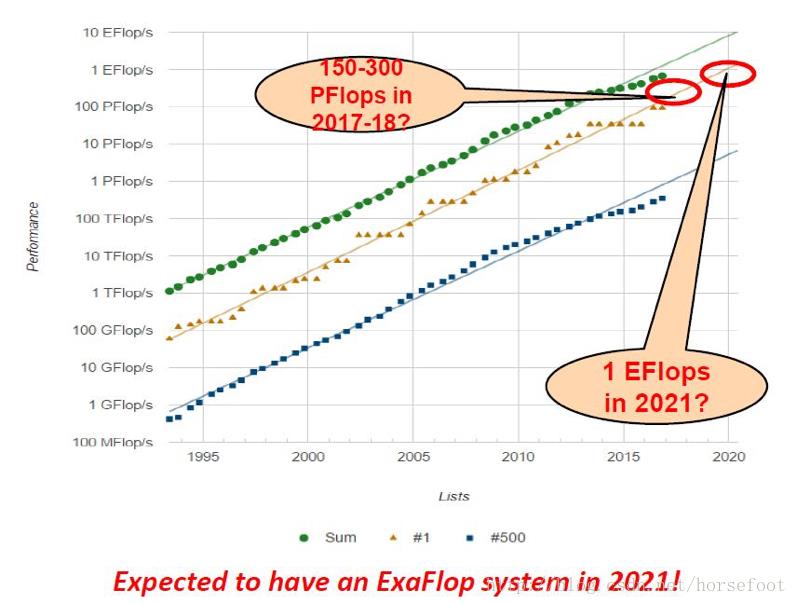
从下图可以看出当前机器学习系统的规模已经很大。

Big Compute 当前超级计算机已经由规模更大的集群及并行度更高架构组成,如云计算技术,GPU集群和FPGA Farm。这些超级计算机的处理能力相当强大,目前超级计算机Top500中排名第一的是神威-太湖之光系统,属于国家超级计算无锡中心,天云软件已经与其成功合作,将使用OpenLava进行任务调度管理。
分布式机器学习是随着大数据概念兴起的。在有大数据之前,有很多研究工作为了让机器学习算法更快,而利用多个处理器。这类工作通常称为并行计算或者并行机器学习,其核心目标是把计算任务拆解成多个小任务,分配到多个处理器上做计算。
分布式计算或者分布式机器学习除了要把计算任务分布到多个处理器上,更重要的是把计算数据(包括训练数据以及中间结果)分布开来。因为在大数据时代,一台机器的硬盘往往装不下全部数据,或者即使装下了,也会受限于机器的I/O通道带宽,以至于访问速度很慢。为了更大的存储容量、吞吐量以及容错能力,我们都希望把数据分布在多台计算机上。
深度学习作为机器学习算法研究中的一个新的技术,其动机在于建立、模拟人脑进行分析学习的神经网络。深度学习可以简单理解为传统神经网络的拓展。
深度学习概念源于人工神经网络的研究。含多隐层的多层感知器就是一种深度学习结构。深度学习通过组合低层特征形成更加抽象的高层表示属性类别或特征,以发现数据的分布式特征表示。典型的神经网络有深度神经网络(DNN),卷积神经网络(CNN),和循环神经网络(RNN)等。
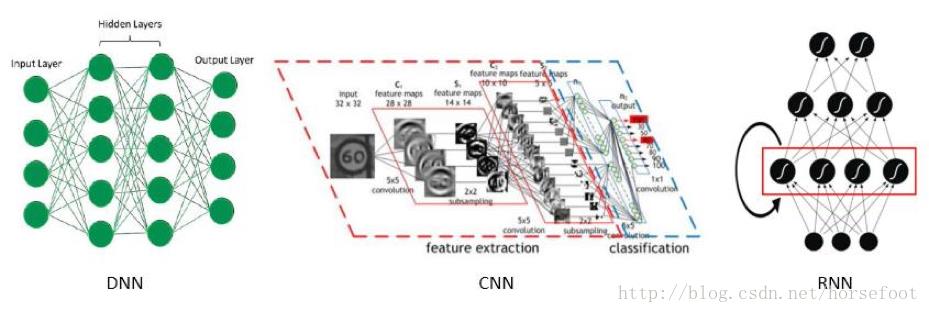
分布式机器学习相关研究进展
近年来,与分布式机器学习相关的研究大量涌现,特别是深度学习方向取得显著进展。
Dropout:一种防止神经网络过拟合的简单方法,其关键思想是在神经网络的训练过程中随机丢弃单元(连同它们的连接点)。这能防止单元适应过度,显著减少过拟合,并相对于其它正则化方法有重大改进。
批标准化:通过减少内部协移加速深度神经网络训练,训练深度神经网络的过程很复杂,原因在于每层的输入分布随着训练过程中引起的前面层的参数变化而变化。这种现象称为内部协变量转移,可利用归一化层输入来解决此问题。通过将此方法应用到最先进的图像分类模型,批标准化在训练次数减少了 14 倍的条件下达到了与原始模型相同的精度,这表明批标准化具有明显的优势。
其它研究进展包括图像识别的深度残差学习、大规模视频分类、生成对抗网络、自然语言处理等等,覆盖了深度学习的方方面面。
分布式机器学习的实现
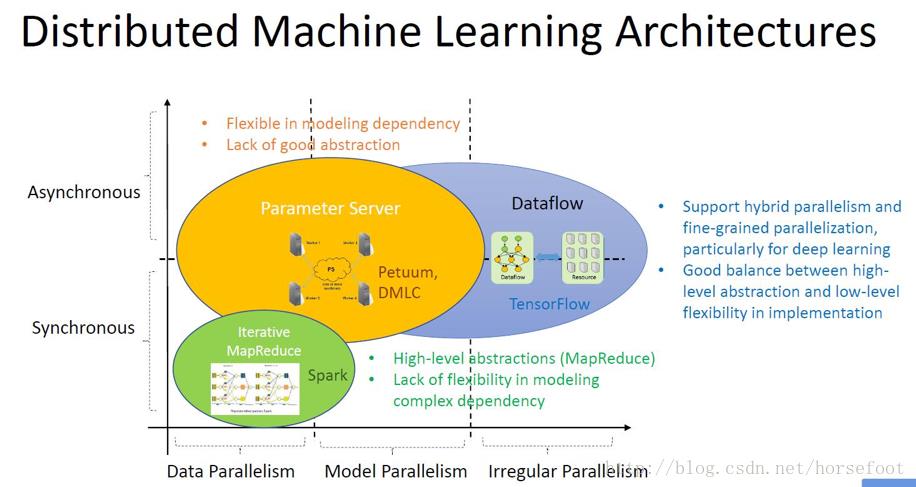
分布式机器学习的实现方式有数据并行,即将数据分布多个部分,分别进行处理,增量更新是提高处理速度的关键;模型并行,即将机器学习所用到的模型参数分散到多个共享的参数服务器上。数据并行与模型并行两种实现方式并没有本质区别,此外还可以按照数据的处理过程进行划分为多个任务来处理。
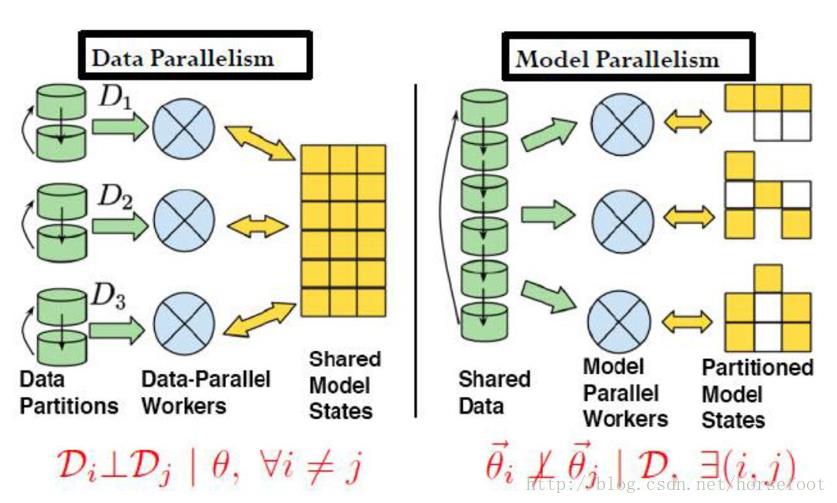
在进行分布式机器学习时,要考虑对参数进行更新是采用同步方式还是异步方式,或是无锁(lock-free,如Hogwild)方式,还要考虑不同进程间的通信方式。
分布式机器学习在HPC集群上的实现
如果应用需要长时间进行机器学习,可以根据企业自身的具体需求及技术积累,选用某种符合自身需要的分布式机器学习架构,从零开始构建分布式机器学习集群,这需要较大的资源投入。如果只是一次性地对模型进行训练,或每次训练的计算量并不大,训练次数也不多,之后只要用训练好的模型计算,或者是原本已经拥有了HPC集群,那么可以考虑在HPC集群上构建自己的分布式机器学习任务。
在HPC集群上实现分布式机器学习,设计深度学习程序通常要用到MPI。MPI是高性能计算应用中广泛使用的编程接口,用于并行化大规模问题的执行,在大多数情况下,需要通过集群作业调度管理软件来启动和监视在集群主机上执行的MPI任务。
MPI是一种基于信息传递的并行编程技术。消息传递接口是一种编程接口标准,而不是一种具体的编程语言。简而言之,MPI标准定义了一组具有可移植性的编程接口。一个使用了MPI的hello world程序如下:
#include <mpi.h>
#include <stdio.h>
int main(int argc, char** argv) {
// Initialize the MPI environment
MPI_Init(NULL, NULL);
// Get the number of processes
int world_size;
MPI_Comm_size(MPI_COMM_WORLD, &world_size);
// Get the rank of the process
int world_rank;
MPI_Comm_rank(MPI_COMM_WORLD, &world_rank);
// Get the name of the processor
char processor_name[MPI_MAX_PROCESSOR_NAME];
int name_len;
MPI_Get_processor_name(processor_name, &name_len);
// Print off a hello world message
printf(“Hello world from processor %s, rank %d”
” out of %d processors\\n”,
processor_name, world_rank, world_size);
// Finalize the MPI environment.
MPI_Finalize();
}
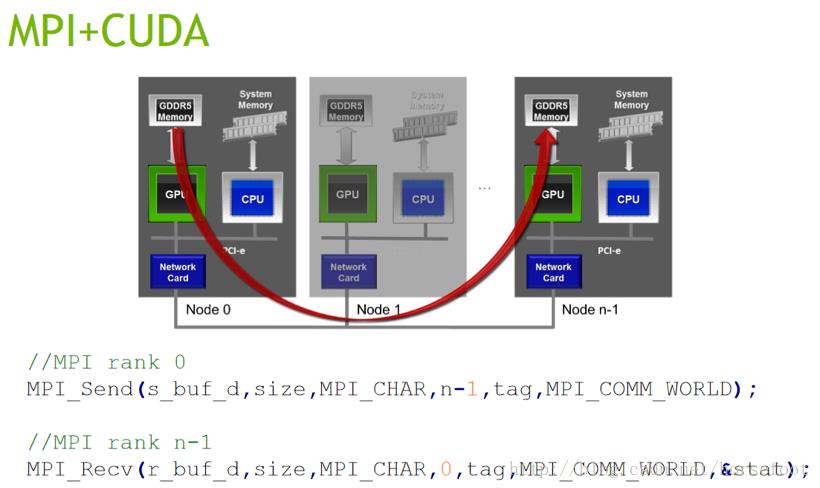
MPI中有两种消息传递模式,一种是点到点通信模式,直接在两个进程之间传递消息,主要是通过发送MPI_Send和接收MPI_Recv函数实现。
另一种消息传递模式是组通信模式,此时一个特定组内所有进程都参加全局的数据处理和通信操作 。主要的通信类型有:
1)数据移动:广播Mpi_Bcast,收集Mpi_Gather,散射Mpi_Scater,组收集Mpi_All gather等。
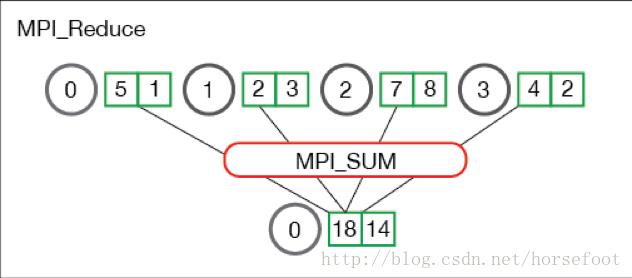
2)聚集:Mpi_Reduce将组内所有的进程输入缓冲区中的数据按指定操作(OP)进行运算,并将运算结果返回到root进程;Mpi_Reduce中支持的操作有返回最大元素(MPI_MAX),返回最小元素(MPI_MIN),对所有元素求和(MPI_SUM)等多种,详细情况可查询MPI文档。
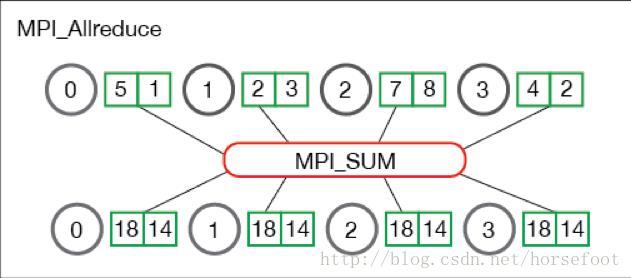
Mpi_AllReduce与Mpi_Reduce的不同在于,在操作结束时,操作结果将返回给参与到操作的所有进程,这种特性非常适合于分布式机器学习,可以方便地达到对参数服务器进行更新的目的。
3)同步:路障Mpi_Barrier实现通信域内所有进程互相同步,它们将处于等待状态,直到所有进程执行它们各自的Mpi_Barrier调用。
大多数主流的并行编程语言都支持对MPI接口的调用,包括C/C++,Java,Python,R,Go等。MPI的具体实现也有多种,有MPICH,OpenMPI,MVAPICH, IBM Platform MPI等。
随着GPU在高性能计算中的普及,MPI也开始支持使用GPU来加速并行计算,MPI与CUDA编程模型完全兼容。使用MPI+CUDA可以做到:
- 解决单个GPU的内存不能将问题的数据全部装下的问题;
- 解决只用单个节点计算,可能需要非常长的计算时间的问题;
- 应用GPU加速现有的MPI程序;
- 可以将现有的单节点-多GPU应用扩展到多个节点上执行。
常规MPI实现在GPU间传递消息时需要先使用cudaMemcopy将GPU中的内容复制到主机内存中。在使用CUDA-aware MPI时,可以直接使用MPI来发送和接收GPU中的内容(如点对点通信部分的配图所示)。
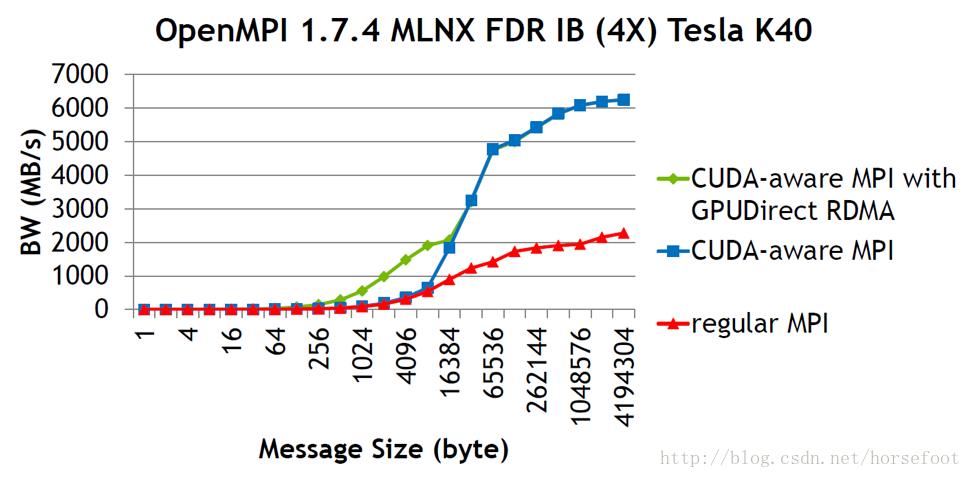
在应用MPI支持GPU应用时,为取得最佳效果,要注意以下两点:
- 使用非阻塞的MPI;
- 将计算时间与通信时间尽量重叠。
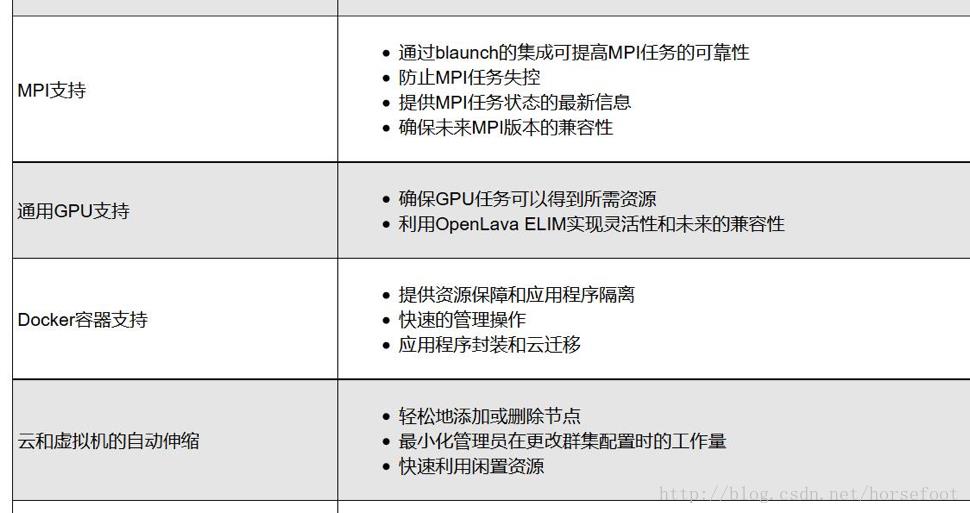
在HPC系统上实现分布式机器学习系统,与专门设计的分布式机器学习框架的不同之处在于,HPC系统中的资源不是由单个机器学习应用所独占,而是由调度系统根据不同应用的请求,按照一定的调度策略完成调度。在实现过程中,用户不需要担心GPU资源的申请(前提是HPC系统中有GPU),天云软件SkyForm OpenLava支持对GPU的管理调度,下图给出了OpenLava的部分特性,详细了解可访问官网(http://openlava.net/)。
一种在HPC系统上实现分布式机器学习的方案是针对现有的开源项目进行改造,这些项目的开发语言大多都支持MPI,使其可以在HPC系统中执行。开发过程中需要注意针对特定HPC系统环境,可能对系统及编程语言的具体版本有要求。实现时可将学习过程分解成多个小的子任务,子任务间可以通过MPI通信。在资源允许时,应用就可以被调度器调度到多个节点上执行,通过MPI来实现模型参数的更新。
在设计时还要考虑到容错问题,避免由于少数任务失败导致之前所有任务无效的状况。在神经元网络(也包括含更多隐层的深度学习)场景下,上一层神经元计算完成以后才能进行下一层神经元网络的计算,这与MPI的计算思路不谋而合,比较方便进行改造。有两个开源的项目可供参考,分别是tensorflow-allreduce(https://github.com/baidu-research/tensorflow-allreduce)项目和Caffe-MPI(https://github.com/Caffe-MPI/Caffe-MPI.github.io)项目。
用户还可以利用Docker容器来开发分布式机器学习应用,这样开发与部署比较容易,对执行环境的依赖较少,只要HPC上能运行Docker就可以,但是运行时的性能会受到一定影响。具体采用哪种方法可根据应用的性能需求及自身技术储备综合考虑。
随着深度学习技术的发展,机器学习应用将要面临更多的数据、更大的模型和更强的计算需求。HPC将会与深度学习紧密结合,相互推动前进。

结束语
以上是关于分布式机器学习的集群方案介绍之HPC实现的主要内容,如果未能解决你的问题,请参考以下文章