统计史记的字数
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了统计史记的字数相关的知识,希望对你有一定的参考价值。
好久没有读书了,突然想读一读历史来提高一下自己的逼格。然后就到网上下载了《史记》原文全文。
因为不知道是不是全集的,所以突发奇想,想统计一下总的文字数量,看看是不是基本齐全。OK ,说干就干,能使用的语言很多,C# ,php ,JAVA ,C++ ,PYTHON, VB , 都可以。用哪一种呢?python 刚接触,挺新鲜,就你了。没想到,一下子就掉坑里了(如果上天再给我一次选择的机会,我一定选择Java,没想到python 2.7 处理中文真费劲)。
决定用python 了,先选个版本吧,电脑上装了3.5 和 2.7 ,用哪一个呢? 实话说,3.5 就用了一次,爬虫需要。平时用的多的还是2.7 ,经常拿来做一些小的科学计算。那就用 2.7 吧(就这么一步步掉坑里了)。
OK ,开始写代码,第一步就跪了。。。:
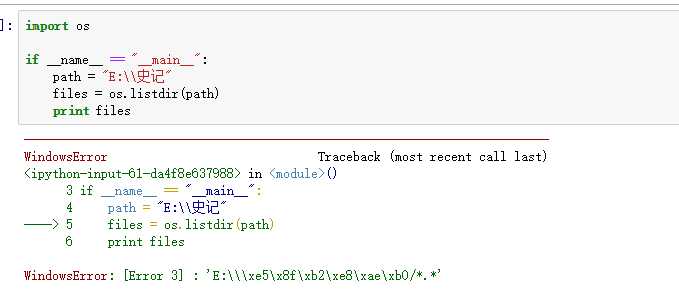
沃日,这是什么情况,想看看文件列表都不行。赶紧问度娘,明白了,原来是路径不能出现中文,出现中文的话需要unicode 一下。 我忍了,毕竟写web 的时候,处理下载中文名文件时候也遇到过。于是改吧:
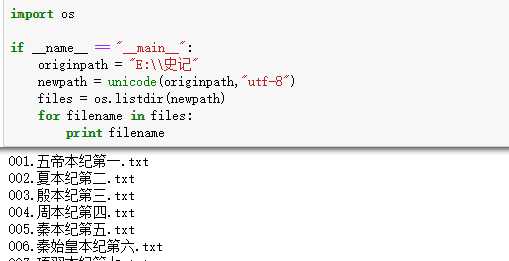
OK ,没问题了,没有报错,我们就是加了一句 unicode(originpath,"utf-8"). 能罗列出来文件,接下来我们就是挨个的遍历每一个文件了:
看上去没问题,能够全部读出来了。然后我们需要判断是符号还是汉字啊,问度娘,知道了unicode 的话,判断是否为汉字可以通过下面方式:
#判断是否为汉字def is_chinese(uchar):if uchar >= u‘\\u4E00‘and uchar <= u‘\\u9FA5‘:returnTrueelse:returnFalse
如上,判断是否为汉字的函数。我们加到程序里面,同时为了统计字数,还需要一个全局变量,python 里面的全局变量有些奇怪,不能初始化。所以,代码进一步完善如下:
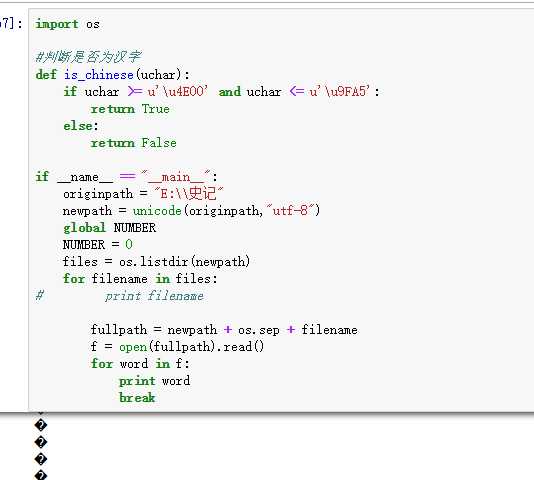
如上,测试了一下,发现竟然乱码了,想想错在哪里呢?f 是直接从文件读取出来的字符串,还是中文的,肯定需要Unicode才能处理啊,赶紧改代码:

我的个神,这次没有报错,但是竟然没有把汉字打印出来,我打印了一个字符才break的啊,怎么回事儿?我改成打印五个字符试试:

能打印出来,好奇怪,这说明第一个字符不是中文?赶紧看看文件:
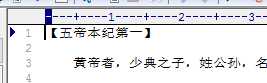
是汉字啊?那是什么原因?难道是可恶的BOM 头 ?
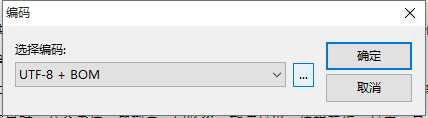
原来如此啊,果然是BOM 头搞的鬼。
赶紧加代码去除BOM 头:
#去除BOM 头信息def cut_bom(f):if f[:3]== codecs.BOM_UTF8:f = f[3:]return f
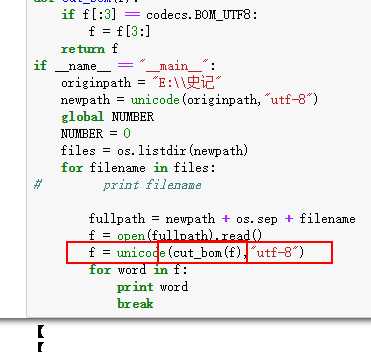
如上所示,有东西了,我们已经去掉BOM 头信息了。搞定这些了,只差最后一步的统计了:
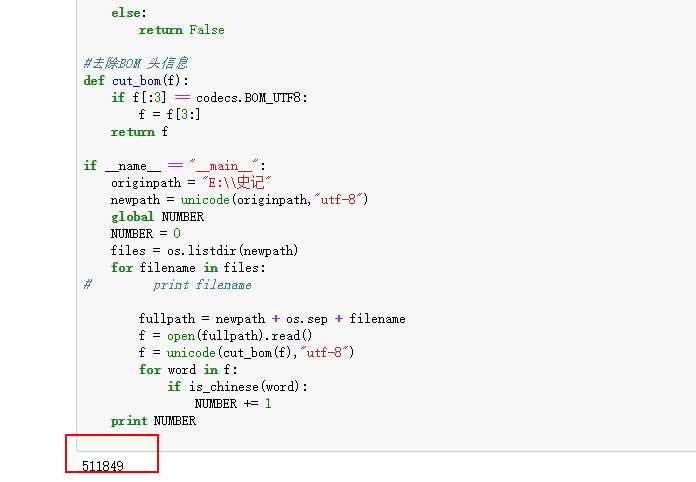
完美,最后统计出来汉字个数一共有 51 万多。 百度了一下史记字数描述如下:

查了一万多字呢。基本上差不多。毕竟史记是经过删改,后人也往里面加了好多东西的。这五十万字就够我看了的。
统计汉字数量并不难,如果用Java 估计十分钟就写出来了,用 python 主要把时间浪费在了乱码处理上,现在基本上就明白了这里面的原理。还是认真读读在Python中正确使用Unicode, 才有了更加深刻的认识。
以上是关于统计史记的字数的主要内容,如果未能解决你的问题,请参考以下文章