百万甚至千万级数据下载
Posted nasjjsadkef
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了百万甚至千万级数据下载相关的知识,希望对你有一定的参考价值。
(#)直奔主题,这次要说的是针对百万千万数据的下载,使用的是poi excel的下载,这个如果大家不熟悉的话,可以去看看这个基础博客,写的不错
http://www.jerehedu.com/fenxiang/160218_for_detail.htm
(#)然而问题来了,(1)excel如何装这么多的数据呢?(2)jvm肯定是一次放不下的 针对与问题(1),其实比较好解决,excel07提供了一个新的
XSSFWorkbook,它会将数据存储在磁盘上,内存中只加载一部分够自己使用就好,那么对于问题(2)怎么解决呢?其实想想也不是很难,只要使用
lazy的加载模式就没有问题了(lazy模式只会在使用的时候才将数据加载),那么在java中lazy的模式首先想到的就是Iterable来包装
(#)这里如果大家的tomcat没有打印gc.log日志,因为这个代码运行的时候,首先要关注的就是gc的问题,如果发现一直在fgc那么肯定就要跪了,这个时候怎么看gc
日志呢?嗯,如果不清楚的话,首先要做的就是去熟悉一下jvm带的命令,我们使用jstat -gcutil -uid 来看一下,如下:
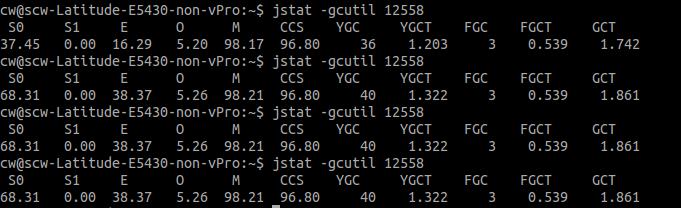
(#) 废话不多说,show the code
首先是读取数据库数据的代码,如下:
Iterable<List<AirlineRecord>> airRecords = new Iterable<List<AirlineRecord>>() {
@Override
public Iterator<List<AirlineRecord>> iterator() {
return new AbstractIterator<List<AirlineRecord>>() {
int totalCount = airlineRecordDao.selectCountByState(null);
int sizeCount = totalCount / SIZE;
int index = 0;
@Override
protected List<AirlineRecord> computeNext() {
if (index > sizeCount) {
return endOfData();
}
List<AirlineRecord> records = airlineRecordDao.selectByState(null, new RowBounds(index * SIZE, SIZE));
index++;
return records;
}
};
}
};
我的数据库中的数据量是100多万的,RowBounds应该使用一个拦截器改成物理分,要不还是会有问题的,然后剩下的就很简单了,利用Iterable本身的lazy属性,现
在不会将多有的数据都加载进来,每次只会迭代SIZE大小的数据,这样JVM就不会有任何压力,百万,千万的数据都是可以撑的住的
下面来看一下下载的代码
public static <T> SXSSFWorkbook export(Iterable<T> excelData, String sheetName, TableFormatterConfigurer configurer) {
// 声明一个(SXSSFWorkbook)工作薄
SXSSFWorkbook workbook = new SXSSFWorkbook(); // SXSSFWorkbook默认只在内存中存放100行
T firstItem = Iterables.getFirst(excelData, null);
if (firstItem != null) {
return export(sheetName, excelData, workbook, configurer, (Class<T>) firstItem.getClass());
}
return workbook;
}
/**
* 导出Excel
*
* @param sheetName excel表格名
* @param excelData 要导出的数据
* @param workbook 要导出的工作薄
* @return
*
* @author mars.mao created on 2014年10月17日下午7:36:26
*/
public static <T> HSSFWorkbook export(String sheetName, List<T> excelData, HSSFWorkbook workbook) {
return export(sheetName, excelData, workbook, TableFormatterConfigurer.NONE);
}
public static <T> HSSFWorkbook export(String sheetName, List<T> excelData, HSSFWorkbook workbook,
TableFormatterConfigurer configurer) {
if (excelData == null || excelData.isEmpty() || workbook == null || StringUtils.isBlank(sheetName)) {
return workbook;
}
try {
// 定义标题行字体
Font font = workbook.createFont();
font.setBoldweight(Font.BOLDWEIGHT_BOLD);
int totalDataSize = excelData.size();
int sheetCnt = totalDataSize / EXCEL_MAX_ROW_NO + 1;
if (sheetCnt > EXCEL_MAX_SHEET_CNT) {
throw new Exception("数据量超过了Excel的容量范围!");
}
for (int i = 0; i < sheetCnt; i++) {
int fromIndex = i * EXCEL_MAX_ROW_NO;
int toIndex = fromIndex + EXCEL_MAX_ROW_NO;
toIndex = toIndex > totalDataSize ? totalDataSize : toIndex;
List<T> sheetData = excelData.subList(fromIndex, toIndex);
// 生成一个表格
Sheet sheet = workbook.createSheet(sheetName + "_" + i);
// 生成标题行
createHeader(sheetData, sheet, font, configurer);
// 遍历集合数据,产生数据行
createBody(sheetData, sheet, configurer);
}
logger.info("导出的数据行数(不含表头): writeCount={}", excelData.size());
return workbook;
} catch (Exception e) {
logger.error("导出Excel异常!", e);
}
return workbook;
}
/**
* 导出Excel, 使用SXSSFWorkbook支持大数据量的导出
*
* @param sheetName excel表格名
* @param excelData 要导出的数据
* @param workbook 要导出的工作薄
* @param configurer 配置数据格式化行为的对象
* @param clazz 待导出数据的类型信息
* @return
*/
public static <T> SXSSFWorkbook export(String sheetName, Iterable<T> excelData, SXSSFWorkbook workbook,
TableFormatterConfigurer configurer, Class<T> clazz) {
final Iterator<T> externalIterator;
if (excelData == null || !(externalIterator = excelData.iterator()).hasNext() || workbook == null
|| StringUtils.isBlank(sheetName)) {
return workbook;
}
try {
// 定义标题行字体
Font font = workbook.createFont();
font.setBoldweight(Font.BOLDWEIGHT_BOLD);
int writeCount = 0; // 记录导出的行数
int i = 0;
while (externalIterator.hasNext()) {
// 生成一个表格
Sheet sheet = workbook.createSheet(sheetName + "_" + i);
// 生成标题行
createHeader(sheet, font, configurer, clazz);
// 遍历集合数据,产生数据行
writeCount += createBody(new Iterable<T>() {
public Iterator<T> iterator() {
return new Iterator<T>() {
int lineCount = 0;
public boolean hasNext() {
return lineCount < EXCEL_MAX_ROW_NO && externalIterator.hasNext();
}
public T next() {
if (!hasNext()) {
throw new NoSuchElementException("没有更多的元素");
}
lineCount++;
return externalIterator.next();
}
public void remove() {
throw new UnsupportedOperationException("不支持删除操作");
}
};
}
}, sheet, configurer, clazz);
if ((++i) == EXCEL_MAX_SHEET_CNT) {
throw new Exception("数据量超过了Excel的容量范围!");
}
}
logger.info("导出的数据行数(不含表头): writeCount={}", writeCount);
return workbook;
} catch (Exception e) {
logger.error("导出Excel异常!", e);
}
return workbook;
}
/**
* 创建表格数据
*
* @param excelData 要导出的数据
* @param sheet excel表格
* @param configurer 配置数据格式化行为的对象
* @return 返回创建的数据行数
*
* @author mars.mao created on 2014年10月17日下午3:43:43
*/
@SuppressWarnings("unchecked")
private static <T> int createBody(List<T> excelData, Sheet sheet, TableFormatterConfigurer configurer)
throws Exception {
if (CollectionUtils.isEmpty(excelData)) {
return 0;
}
Class<?> dataClass = excelData.get(0).getClass();
return createBody(excelData, sheet, configurer, dataClass);
}
/**
* 创建表格数据
*
* @param excelData 要导出的数据
* @param sheet excel表格
* @param configurer 配置数据格式化行为的对象
* @param clazz 要导出的对象的类型信息, 用以获取相关注解以及字段值
* @return 返回创建的数据行数
*/
private static <T> int createBody(Iterable<T> excelData, Sheet sheet, TableFormatterConfigurer configurer,
Class<?> clazz) throws Exception {
if (excelData == null) {
return 0;
}
List<Field> fields = getExportableFields(clazz, configurer);
Map<String, Method> methodMap = getFormattingMethods(clazz);
int dataRowIndex = 1;
for (T data : excelData) {
// 创建数据行
Row dataRow = sheet.createRow(dataRowIndex);
int columnIndex = 0;
for (Field field : fields) {
ExcelColumn columnHeader = field.getAnnotation(ExcelColumn.class);
// 创建列
String textValue;
Method formattingMethod = methodMap.get(field.getName());
if (formattingMethod != null) {
// 优先使用"格式化方法"对属性进行格式化
formattingMethod.setAccessible(true);
textValue = String.valueOf(formattingMethod.invoke(data));
} else {
// 在没有"格式化方法"时使用@ExcelColumn指定的格式化方式
textValue = getTextValue(data, field, columnHeader, configurer);
}
Cell cell = dataRow.createCell(columnIndex);
// HSSFRichTextString text = new HSSFRichTextString(textValue);
// cell.setCellValue(text);
cell.setCellValue(textValue);
columnIndex++;
}
dataRowIndex++;
}
return dataRowIndex - 1;
}
/**
* 生成Excel的标题行
*
* @param excelData 导出的数据列表
* @param sheet excel表
* @return
*
* @author mars.mao created on 2014年10月17日下午2:08:41
*/
@SuppressWarnings("unchecked")
private static <T> void createHeader(List<T> excelData, Sheet sheet, Font font, TableFormatterConfigurer configurer) {
if (CollectionUtils.isEmpty(excelData)) {
return;
}
Class<?> dataClass = excelData.get(0).getClass();
createHeader(sheet, font, configurer, dataClass);
}
private static void createHeader(Sheet sheet, Font font, TableFormatterConfigurer configurer, Class<?> clazz) {
List<Field> fields = getExportableFields(clazz, configurer);
Row headerRow = sheet.createRow(0);
int columnIndex = 0;
for (Field field : fields) {
ExcelColumn columnHeader = field.getAnnotation(ExcelColumn.class);
// 获取指定的列标题和列宽度
String columnTitle = columnHeader.headerName();
int columnWidth = columnHeader.columnWidth();
// 创建列
Cell cell = headerRow.createCell(columnIndex);
// 设置列标题
if (sheet instanceof HSSFSheet) {
RichTextString text = new HSSFRichTextString(columnTitle);
text.applyFont(font);
cell.setCellValue(text);
} else {
cell.setCellValue(columnTitle);
}
// 设置列宽度
sheet.setColumnWidth(columnIndex, columnWidth * 256);
columnIndex++;
}
}
/**
* 获取格式化的文本内容
*
* @param obj 输入对象
* @param field 对象域
* @param columnHeader ExcelColumn注解的配置实例
* @param configurer TableFormatterConfigurer的配置实例
* @return 格式化后的文本
*/
@SuppressWarnings("unchecked")
private static <T> String getTextValue(T obj, Field field, ExcelColumn columnHeader,
TableFormatterConfigurer configurer) {
String aimPattern = columnHeader.pattern();
Object fieldValue = getFieldValue(obj, field); // 反射获取字段的值
String textValue = null;
Class<? extends Formatter> formatterClass = columnHeader.formatterClass();
boolean allowAlternativeFormatter = columnHeader.allowAlternativeFormatter();
boolean formatted = false;
try {
// 1) 尝试使用注册在的formatterMap中的formatter; 以属性名为key的formatterMap优先
if (allowAlternativeFormatter) {
Formatter registeredFormatter = configurer.getFormatter(field.getName());
if (registeredFormatter == null && fieldValue != null) {
registeredFormatter = configurer.getFormatter(fieldValue.getClass());
}
if (registeredFormatter != null) {
textValue = registeredFormatter.format(fieldValue);
formatted = true;
}
}
// 2) 没有获取到注册的formatter, 则尝试使用指定的formatterClass
if (!formatted && formatterClass != Formatter.None.class) {
Formatter formatter = formatterClass.newInstance();
textValue = formatter.format(fieldValue);
formatted = true;
}
} catch (Exception e) {
logger.error("导出Excel使用formatter格式化出错: {}", e.getMessage(), e);
formatted = false;
}
if (!formatted) {
/*
* 3) [未指定formatter, 且未开启formatter的注册] 或者 [以上格式化失败]; 使用默认的处理方式...
*/
textValue = defaultToString(fieldValue, aimPattern);
}
return textValue;
}
/*
* 默认的格式处理方式 (与历史版本兼容)
*/
private static String defaultToString(Object fieldValue, String aimPattern) {
String textValue = " ";
if (fieldValue != null) {
textValue = fieldValue.toString();
}
if (fieldValue instanceof Date) {
try {
String pattern = StringUtils.isBlank(aimPattern) ? DEFAULT_DATE_FORMAT : aimPattern;
Date date = (Date) fieldValue;
textValue = DateFormatUtils.format(date, pattern);
} catch (Exception e) {
logger.error("导出Excel日期格式化错误!", e);
}
} else if (fieldValue instanceof DateTime) { // 添加对DateTime类型的兼容(采用与Date类型一样的pattern设置) [by chenjiahua.chen
// 2016/09/05]
try {
String pattern = StringUtils.isBlank(aimPattern) ? DEFAULT_DATE_FORMAT : aimPattern;
DateTime dateTime = (DateTime) fieldValue;
textValue = dateTime.toString(pattern);
} catch (Exception e) {
logger.error("导出Excel日期格式化错误!", e);
}
} else if (fieldValue instanceof Money) { // 添加对Money类型的兼容, 以toMoneyString输出(两位小数) [by chenjiahua.chen
// 2016/09/05]
try {
Money money = (Money) fieldValue;
return money.toMoneyString();
} catch (Exception e) {
logger.error("导出Excel金额格式化错误!", e);
}
} else if (fieldValue instanceof Number) {
if (StringUtils.isNotBlank(aimPattern)) {
try {
double doubleValue = Double.parseDouble(fieldValue.toString());
DecimalFormat df1 = new DecimalFormat(aimPattern);
textValue = df1.format(doubleValue);
} catch (Exception e) {
logger.error("导出Excel数字格式化错误!", e);
}
}
}
return textValue;
}
/**
* 反射获取字段的值
*
* @param obj 对象
* @param field 字段
* @return
*
* @author mars.mao created on 2014年10月17日下午2:58:53
*/
private static <T> Object getFieldValue(T obj, Field field) {
Object fieldValue = " ";
try {
field.setAccessible(true);
fieldValue = field.get(obj);
if (fieldValue != null) {
return fieldValue;
}
} catch (Exception e) {
logger.error("导出Excel动态获取字段值异常", e);
}
return fieldValue;
}
/**
* 根据给定类的信息获取其所有字段 (包括继承而来的字段!)
*/
private static List<Field> getExportableFields(Class<?> clazz, final TableFormatterConfigurer configurer) {
List<Field> fields = Lists.newArrayList();
/* 循环向上查找, 以支持父类中的属性导出 [by chenjiahua.chen 2016/09/05] */
for (Class<?> dataClass : getClassesInHierarchy(clazz)) {
fields.addAll(Arrays.asList(dataClass.getDeclaredFields()));
}
// 过滤不需要导出的属性
fields = Lists.newArrayList(Iterables.filter(fields, new Predicate<Field>() {
@Override
public boolean apply(Field field) {
ExcelColumn columnHeader = field.getAnnotation(ExcelColumn.class);
if (columnHeader == null || configurer.getHeadersToBeFiltered().contains(columnHeader.headerName())) {
return false;
}
return true;
}
}));
return fields;
}
private static Map<String, Method> getFormattingMethods(Class<?> clazz) {
List<Method> methods = Lists.newArrayList();
/* 循环向上查找, 以支持父类中的格式化方法 [by chenjiahua.chen 2017/02/09] */
for (Class<?> dataClass : getClassesInHierarchy(clazz)) {
methods.addAll(Arrays.asList(dataClass.getDeclaredMethods()));
}
// 过滤和格式化无关的方法
methods = Lists.newArrayList(Iterables.filter(methods, new Predicate<Method>() {
@Override
public boolean apply(Method method) {
return method.getAnnotation(FieldFormat.class) != null;
}
}));
return Maps.uniqueIndex(methods, new Function<Method, String>() {
@Override
public String apply(Method method) {
return method.getAnnotation(FieldFormat.class).fieldName();
}
});
}
/**
* 获取继承体系中的类
*/
private static List<Class<?>> getClassesInHierarchy(Class<?> clazz) {
List<Class<?>> classes = Lists.newArrayList();
Stack<Class<?>> classStack = new Stack<Class<?>>();
Class<?> currentClass = clazz;
while (currentClass != null) {
classStack.push(currentClass);
currentClass = currentClass.getSuperclass();
}
while (!classStack.isEmpty()) {
classes.add(classStack.pop());
}
return classes;
}
public static Workbook dynamicExport(String sheetName, List<RowRecord> excelData) {
if (org.apache.commons.collections4.CollectionUtils.isEmpty(excelData) || StringUtils.isBlank(sheetName)) {
return null;
}
HSSFWorkbook workbook = new HSSFWorkbook();
// 标题行字体
Font font = workbook.createFont();
font.setBold(true);
// 定义单元格格式
CellStyle cellStyle = workbook.createCellStyle();
cellStyle.setAlignment(HorizontalAlignment.CENTER);
// 分割sheet
int totalCnt = excelData.size();
int sheetCnt = totalCnt / EXCEL_MAX_ROW_NO + 1;
if (sheetCnt > EXCEL_MAX_SHEET_CNT) {
throw new RuntimeException("数据量超过了Excel的容量范围!");
}
for (int i = 0; i < sheetCnt; i++) {
int fromIndex = i * EXCEL_MAX_ROW_NO;
int toIndex = fromIndex + EXCEL_MAX_ROW_NO;
toIndex = toIndex > totalCnt ? totalCnt : toIndex;
List<RowRecord> sheetData = excelData.subList(fromIndex, toIndex);
// 生成一个表格
Sheet sheet = workbook.createSheet(sheetName + "_" + i);
// 生成标题行
createHeader(sheetData, sheet, font, cellStyle);
// 遍历集合数据,产生数据行
createBody(sheetData, sheet);
}
return workbook;
}
private static void createHeader(List<RowRecord> excelData, Sheet sheet, Font font, CellStyle cellStyle) {
if (org.apache.commons.collections4.CollectionUtils.isEmpty(excelData)) {
return;
}
RowRecord rowRecord = excelData.get(0);
createHeader(sheet, rowRecord, font, cellStyle);
}
private static void createHeader(Sheet sheet, RowRecord rowRecord, Font font, CellStyle cellStyle) {
if (org.apache.commons.collections4.CollectionUtils.isEmpty(rowRecord.getColumnRecordList())) {
return;
}
// 获取表头节点的层数
List<ColumnRecord> columnRecordList = rowRecord.getColumnRecordList();
int HeaderLayerCnt = 1;
for (ColumnRecord columnRecord : columnRecordList) {
if (HeaderLayerCnt < columnRecord.getColumnNameList().size()) {
HeaderLayerCnt = columnRecord.getColumnNameList().size();
}
}
int i = 0;
int columnIndex;
int preColumnIndex;
String preHeader;
while (i < HeaderLayerCnt) {
preHeader = null;
preColumnIndex = columnIndex = 0;
Row headerRow = sheet.createRow(i);
for (ColumnRecord columnRecord : rowRecord.getColumnRecordList()) {
if (columnRecord.getColumnNameList().size() < i + 1) {
columnIndex++;
preColumnIndex++;
continue;
}
if (preHeader == null || !columnRecord.getColumnNameList().get(i).equals(preHeader)) {
// 获取指定的列标题和列
if (columnIndex - preColumnIndex > 1) {
sheet.addMergedRegion(new CellRangeAddress(i, i, preColumnIndex, columnIndex - 1));
}
preColumnIndex = columnIndex;
String columnTitle = columnRecord.getColumnNameList().get(i);
// 创建列
Cell cell = headerRow.createCell(columnIndex);
// 设置列标题
RichTextString text = new HSSFRichTextString(columnTitle);
text.applyFont(font);
cell.setCellValue(text);
cell.setCellStyle(cellStyle);
preHeader = columnRecord.getColumnNameList().get(i);
}
// 最后一列判定
if ((columnIndex == rowRecord.getColumnRecordList().size() - 1) && (columnIndex - preColumnIndex >= 1)) {
sheet.addMergedRegion(new CellRangeAddress(i, i, preColumnIndex, columnIndex));
}
columnIndex++;
}
i++;
}
}
private static void createBody(List<RowRecord> rowRecords, Sheet sheet) {
int rowIndex = sheet.getLastRowNum() + 1;
for (RowRecord rowRecord : rowRecords) {
Row dataRow = sheet.createRow(rowIndex);
int columnIndex = 0;
for (ColumnRecord columnRecord : rowRecord.getColumnRecordList()) {
String textValue = getTextValue(columnRecord);
Cell cell = dataRow.createCell(columnIndex);
cell.setCellValue(textValue);
sheet.autoSizeColumn(columnIndex, true);
columnIndex++;
}
rowIndex++;
}
}
private static String getTextValue(ColumnRecord columnRecord) {
Class<? extends Formatter> formatterClass = columnRecord.getFormatter();
if (formatterClass.equals(Formatter.DefaultFormatter.class)) {
return columnRecord.getPropertyValue().toString();
}
try {
Formatter<Object> formatter = formatterClass.newInstance();
return formatter.format(columnRecord.getPropertyValue());
} catch (Exception e) {
logger.error("导出Excel使用formatter格式化出错: {}", e.getMessage(), e);
}
return null;
}
说点啥呢,嗯,就随便说说如果操作不当的时候会出现什么情况呢,首先看看gc,会一直在进行fgc,但是并没有什么卵用,E 100%,O 99.99%,每次fgc由于数据都是被
引用的状态,也就是说根本gc不掉的,那么就会一直进行fgc,fgc的时候是stop the world,所以你的tomcat会出在假死状态,并且肯定会造成服务不可用,一会服务器
就会真的跪了,所以写代码的时候一定要注意你的内存使用情况,注意数据的大小.
最后说下,我导出了100多万的数据,没啥问题,理论上导出千万的数据也没有问题,只是会分成多个sheet而已,如果使用上有什么问题,欢迎咨询可以一起讨论!
以上是关于百万甚至千万级数据下载的主要内容,如果未能解决你的问题,请参考以下文章