机器学习第三练:为慈善机构寻找捐助者
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习第三练:为慈善机构寻找捐助者相关的知识,希望对你有一定的参考价值。
这个任务同样是在Jupyter Notebook中完成,
项目目的是通过前面的所有特征列,当然去掉序号列,然后预测最后一列,收入‘income‘,究竟是大于50K,还是小于等于50K.
第一步,探索数据,像探索性统计里经常涉及到的频数,均值,众数或者众位数相关的计算,我们通过这些统计指标,使用python来看一下数据的大概情况
这块主要还是涉及pandas, numpy, visuals相关的内容来进行操作
比如查看一下数据都有哪些特征,标签,因为本身是监督学习

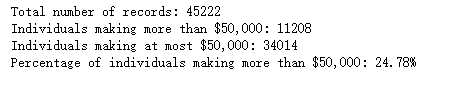
同时,机器学习本身,虽然对各种算法,它们的逻辑步骤,参数,涉及到的数学公式,优缺点等等这些内容涉及的更多一些,但是之前的这个数据预处理,其实涉及到的是特征工程的内容更多,也就是数据分析的相关内容更多一些,
第二步,数据相关处理,
这里涉及到两个变量,资本利得和资本损失,这其实是管理会计相关的概念,利得是指买了一支股票,5块的买的,1000股,涨到10块,卖掉,收益5000(假设没除去其他费用),利得就是5000,同样,假如卖的价格是3块,那么损失就是2000. 其实扯的这个概念在分析特征与标签的关联时才可能用到。
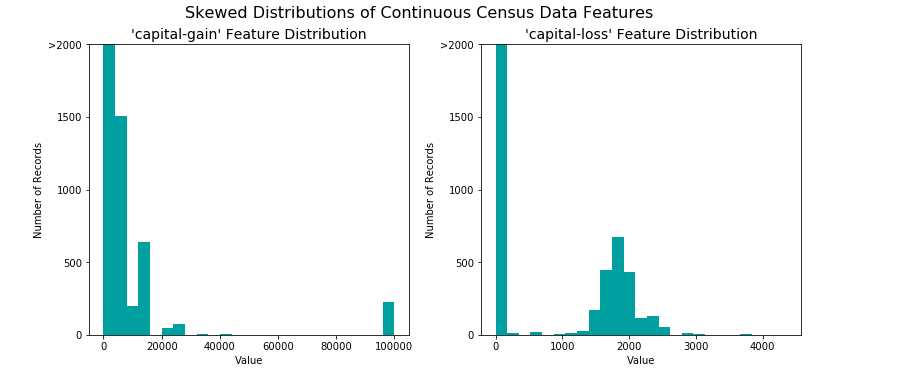
下图,是两个变量原始的分布情况:比如利得的数据看着分散,偏左,如果是期望值是正态分布的话,数据需要转化一下,
使用对数进行转化,可以把极值变小,下图是转换后效果,看着是不是利得和损失的均值都更接近一些了。
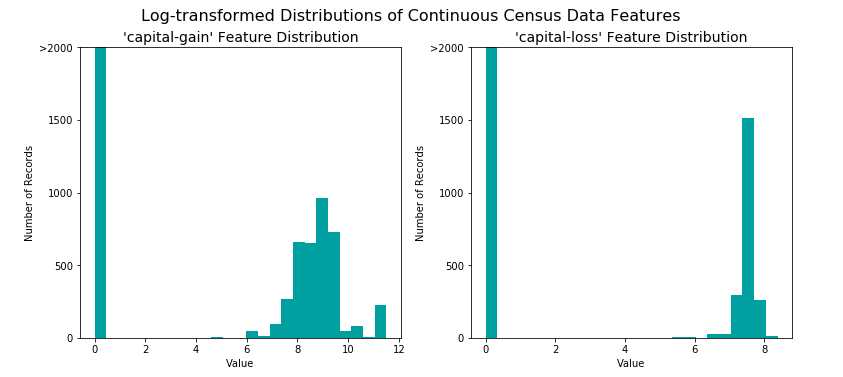
这时数据的分布好一些,但仍需要对数据进行规一化操作,从而在下面使用监督学习器的时候能够被平等的对待
规一化操作的结果使得特征的范围被圈在一个极值范围之内,比如0,1之间,这里的规一化操作就是特征缩放。
没有规一化之前是这个样子

规一化之后是这个样子,可以对比一下上下两幅图的数据,

对标签进行哑编码:(从定性变量转化成定量)
使用pandas.get_dummies()对‘features_raw‘数据来施加一个独热编码
转换之前:
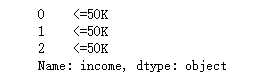
转换之后:

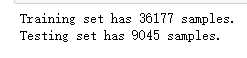
第三步,进行训练集和测试集的分割,
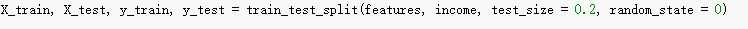
第三步,模型性能评估
混淆矩阵的相关模型评价指标,比如说准确度,Fbeta指标(混合指标,准确率和召回率的混合,beta=0.5时,会强调准确率)
要想了解这个,其实可以先找个使用朴素贝叶斯预测瘟疫的例子,来了解什么假阳性,真阴性什么的。统计学概念,这里不累述,严格按照相关公式定义进行计算就可以。

第四步,选择一个监督模型来做学习器,并阐述其优缺点, 需要举例,并写出引用出处,
个人答案,可能不是太严格,也参考了很多网上的资料,


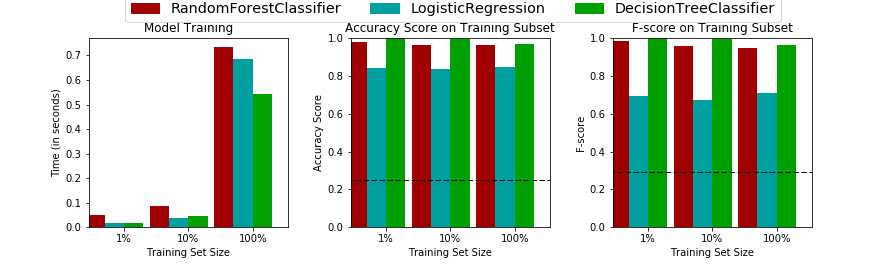
第五步,创建一个pipline来评估上面三个模型,选择最优
有条件限制:
1,比如选择数据的部分内容做预测,使用不同的size来做训练,包括样本的.01,.1和1
2,还是使用sklearn.metrics中的fbeta_score和accuracy_score来进行判定
下面是训练集的结果:
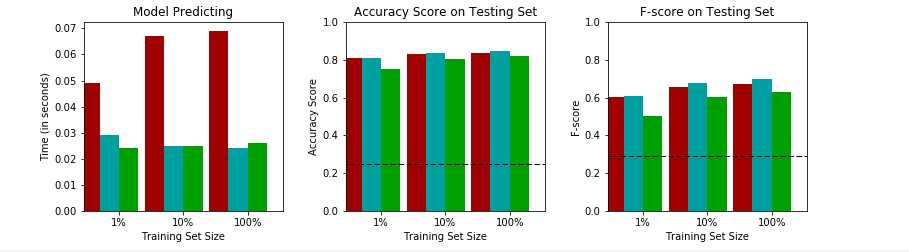
下面是测试集的结果:
第六步,选择最优模型和调参
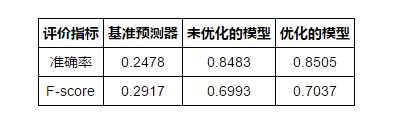
最优的话,从测试集的比例为1的结果来判断,逻辑回归胜出。
调优的话使用 sklearn的网格搜索,配置好对应的参数值,
在调用学习器的时候,grid_obj = GridSearchCV(estimator=clf,param_grid=parameters,scoring=scorer)
参数random_state可以让网格搜索每次划分训练集和验证集的时候都是完全一样的
逻辑回归的参数C,主要是控制模型在过拟合和欠拟合之间保持一个平衡。
结果如下,还是参数调优对模型本身是有帮助的。
第七步,提取特征重要性:
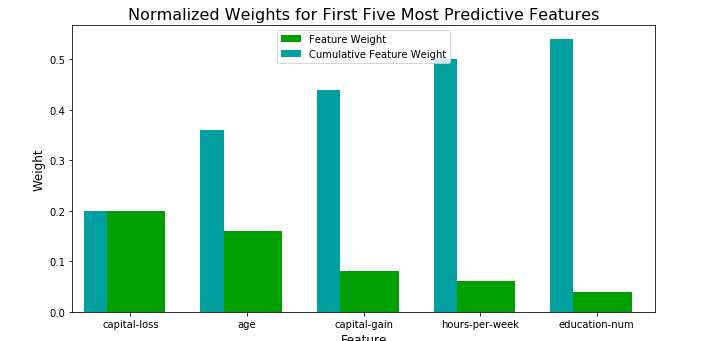
从下图可以看出,其实如果在提取特征这一步之前做主观推测的话,最重要的特征应该会跟下面五项有偏离,
但是下图显示,资本利得和资本损失的权重就比较高,原因应该是在于在此练习过程中,其他的特征都没有被数字化,
以上是关于机器学习第三练:为慈善机构寻找捐助者的主要内容,如果未能解决你的问题,请参考以下文章