cascading--wordcount
Posted 我想静静
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了cascading--wordcount相关的知识,希望对你有一定的参考价值。
在eclipse下运行wordcount,使用cascading封装
准备:centos系统,jdk,hadoop,eclipse,cascading的lib包,官网可下载,自带cascading封装的wordcount源码,以及爬虫数据data目录,这些均可以在官网下载
我是在cascading官网把材料下载好后,在eclipse中运行,可以得到测试数据
难点:cascading的版本与官网自带的wordcount实例可能不匹配,这需要自己自行修改,我的cascading版本不是在官网下载的
给出我的运行结果图:
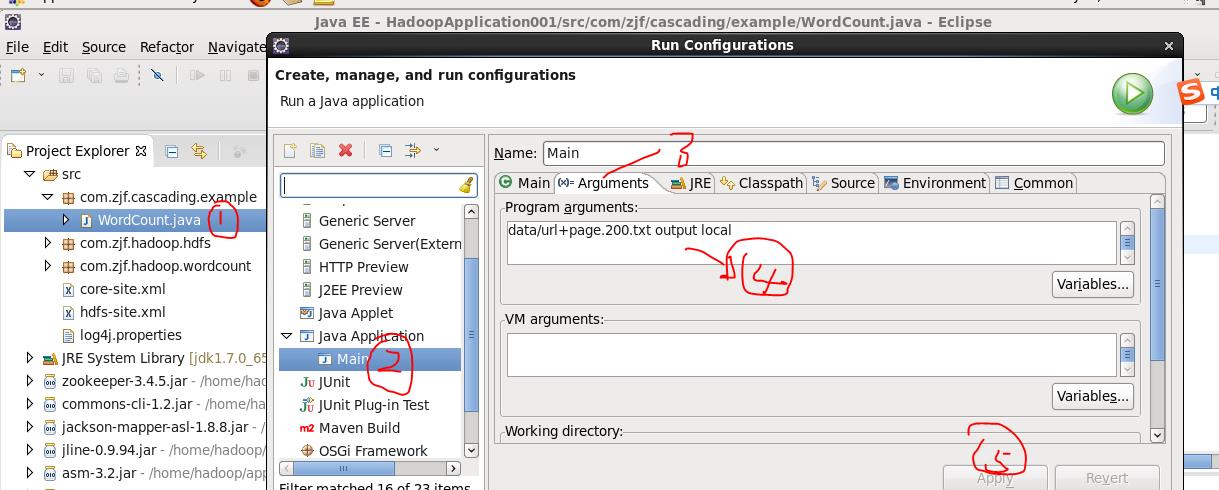
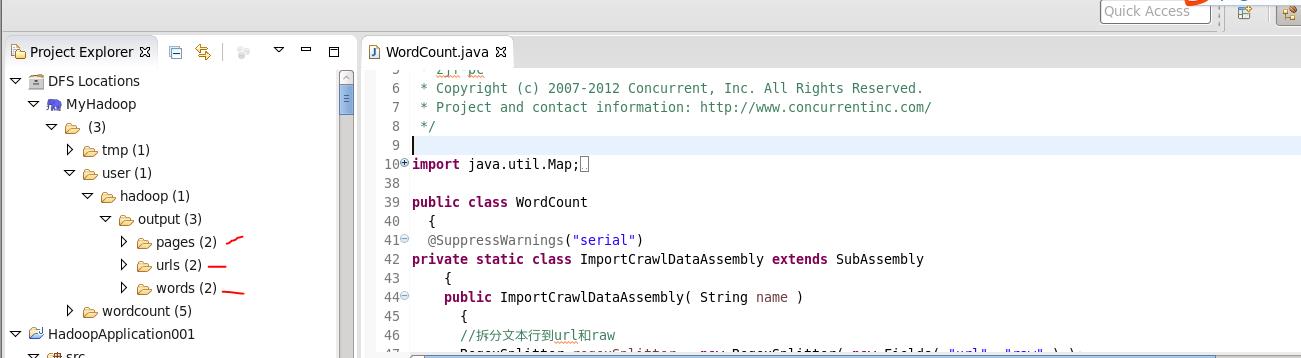
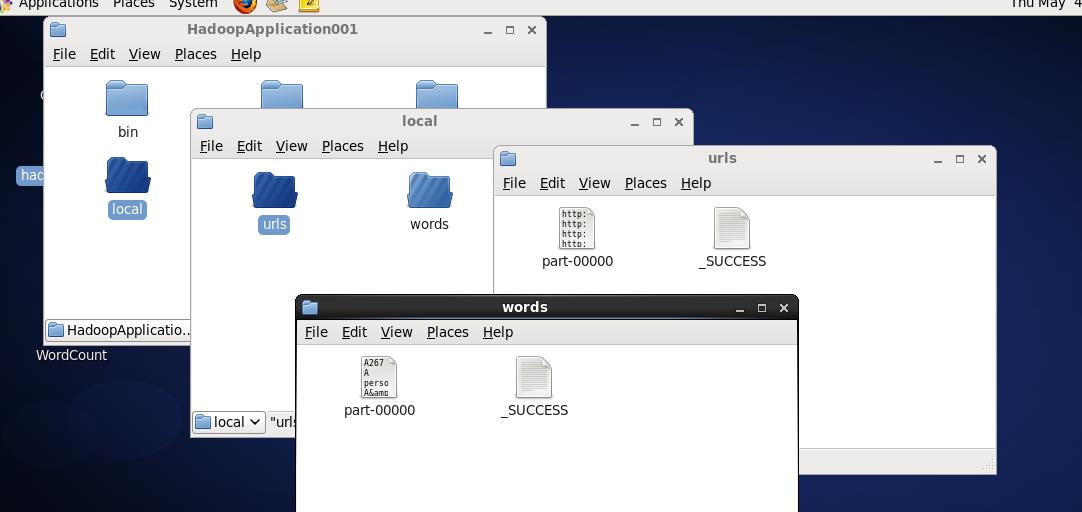
代码如下:完整版
package com.zjf.cascading.example; /* * WordCount example * zjf-pc * Copyright (c) 2007-2012 Concurrent, Inc. All Rights Reserved. * Project and contact information: http://www.concurrentinc.com/ */ import java.util.Map; import java.util.Properties; import cascading.cascade.Cascade; import cascading.cascade.CascadeConnector; import cascading.cascade.Cascades; import cascading.flow.Flow; import cascading.flow.FlowConnector; import cascading.operation.Identity; import cascading.operation.aggregator.Count; import cascading.operation.regex.RegexFilter; import cascading.operation.regex.RegexGenerator; import cascading.operation.regex.RegexReplace; import cascading.operation.regex.RegexSplitter; import cascading.operation.xml.TagSoupParser; import cascading.operation.xml.XPathGenerator; import cascading.operation.xml.XPathOperation; import cascading.pipe.Each; import cascading.pipe.Every; import cascading.pipe.GroupBy; import cascading.pipe.Pipe; import cascading.pipe.SubAssembly; import cascading.scheme.SequenceFile; import cascading.scheme.TextLine; import cascading.tap.Tap; import cascading.tap.Hfs; import cascading.tap.Lfs; import cascading.tuple.Fields; public class WordCount { @SuppressWarnings("serial") private static class ImportCrawlDataAssembly extends SubAssembly { public ImportCrawlDataAssembly( String name ) { //拆分文本行到url和raw RegexSplitter regexSplitter = new RegexSplitter( new Fields( "url", "raw" ) ); Pipe importPipe = new Each( name, new Fields( "line" ), regexSplitter ); //删除所有pdf文档 importPipe = new Each( importPipe, new Fields( "url" ), new RegexFilter( ".*\\\\.pdf$", true ) ); //把":n1"替换为"\\n",丢弃无用的字段 RegexReplace regexReplace = new RegexReplace( new Fields( "page" ), ":nl:", "\\n" ); importPipe = new Each( importPipe, new Fields( "raw" ), regexReplace, new Fields( "url", "page" ) ); //此句强制调用 setTails( importPipe ); } } @SuppressWarnings("serial") private static class WordCountSplitAssembly extends SubAssembly { public WordCountSplitAssembly( String sourceName, String sinkUrlName, String sinkWordName ) { //创建一个新的组件,计算所有页面中字数,和一个页面中的字数 Pipe pipe = new Pipe(sourceName); //利用TagSoup将html转成XHTML,只保留"url"和"xml"去掉其它多余的 pipe = new Each( pipe, new Fields( "page" ), new TagSoupParser( new Fields( "xml" ) ), new Fields( "url", "xml" ) ); //对"xml"字段运用XPath(XML Path Language)表达式,提取"body"元素 XPathGenerator bodyExtractor = new XPathGenerator( new Fields( "body" ), XPathOperation.NAMESPACE_XHTML, "//xhtml:body" ); pipe = new Each( pipe, new Fields( "xml" ), bodyExtractor, new Fields( "url", "body" ) ); //运用另一个XPath表达式删除所有元素,只保留文本节点,删除在"script"元素中的文本节点 String elementXPath = "//text()[ name(parent::node()) != \'script\']"; XPathGenerator elementRemover = new XPathGenerator( new Fields( "words" ), XPathOperation.NAMESPACE_XHTML, elementXPath ); pipe = new Each( pipe, new Fields( "body" ), elementRemover, new Fields( "url", "words" ) ); //用正则表达式将文档打乱成一个个独立的单词,和填充每个单词(新元组)到当前流使用"url"和"word"字段 RegexGenerator wordGenerator = new RegexGenerator( new Fields( "word" ), "(?<!\\\\pL)(?=\\\\pL)[^ ]*(?<=\\\\pL)(?!\\\\pL)" ); pipe = new Each( pipe, new Fields( "words" ), wordGenerator, new Fields( "url", "word" ) ); //按"url"分组 Pipe urlCountPipe = new GroupBy( sinkUrlName, pipe, new Fields( "url", "word" ) ); urlCountPipe = new Every( urlCountPipe, new Fields( "url", "word" ), new Count(), new Fields( "url", "word", "count" ) ); //按"word"分组 Pipe wordCountPipe = new GroupBy( sinkWordName, pipe, new Fields( "word" ) ); wordCountPipe = new Every( wordCountPipe, new Fields( "word" ), new Count(), new Fields( "word", "count" ) ); //此句强制调用 setTails( urlCountPipe, wordCountPipe ); } } public static void main( String[] args ) { //设置当前工作jar Properties properties = new Properties(); FlowConnector.setApplicationJarClass(properties, WordCount.class); FlowConnector flowConnector = new FlowConnector(properties); /** * 在运行设置的参数里设置如下代码: * 右击Main.java,选择run as>run confugrations>java application>Main>Agruments->Program arguments框内写入如下代码 * data/url+page.200.txt output local * 分析: * args[0]代表data/url+page.200.txt,它位于当前应用所在的目录下面,且路径必须是本地文件系统里的路径 * 我的所在目录是/home/hadoop/app/workspace/HadoopApplication001/data/url+page.200.txt * 且该路径需要自己创建,url+page.200.txt文件也必须要有,可以在官网下下载 * * args[1]代表output文件夹,第二个参数,它位于分布式文件系统hdfs中 * 我的路径是:hdfs://s104:9000/user/hadoop/output,该路径需要自己创建 * 在程序运行成功后,output目录下会自动生成三个文件夹pages,urls,words * 里面分别包含所有的page,所有的url,所有的word * * args[2]代表local,第三个参数,它位于本地文件系统中 * 我的所在目录是/home/hadoop/app/workspace/HadoopApplication001/local * 该文件夹不需要自己创建,在程序运行成功后会自动生成在我的上述目录中, * 且在该local文件夹下会自动生成两个文件夹urls和words,里面分别是url个数和word个数 */ String inputPath = args[ 0 ]; String pagesPath = args[ 1 ] + "/pages/"; String urlsPath = args[ 1 ] + "/urls/"; String wordsPath = args[ 1 ] + "/words/"; String localUrlsPath = args[ 2 ] + "/urls/"; String localWordsPath = args[ 2 ] + "/words/"; // import a text file with crawled pages from the local filesystem into a Hadoop distributed filesystem // the imported file will be a native Hadoop sequence file with the fields "page" and "url" // note this examples stores crawl pages as a tabbed file, with the first field being the "url" // and the second being the "raw" document that had all new line chars ("\\n") converted to the text ":nl:". //初始化Pipe管道处理爬虫数据装配,返回字段url和page Pipe importPipe = new ImportCrawlDataAssembly( "import pipe" ); //创建tap实例 Tap localPagesSource = new Lfs( new TextLine(), inputPath ); Tap importedPages = new Hfs( new SequenceFile( new Fields( "url", "page" ) ), pagesPath ); //链接pipe装配到tap实例 Flow importPagesFlow = flowConnector.connect( "import pages", localPagesSource, importedPages, importPipe ); //拆分之前定义的wordcount管道到新的两个管道url和word // these pipes could be retrieved via the getTails() method and added to new pipe instances SubAssembly wordCountPipe = new WordCountSplitAssembly( "wordcount pipe", "url pipe", "word pipe" ); //创建hadoop SequenceFile文件存储计数后的结果 Tap sinkUrl = new Hfs( new SequenceFile( new Fields( "url", "word", "count" ) ), urlsPath ); Tap sinkWord = new Hfs( new SequenceFile( new Fields( "word", "count" ) ), wordsPath ); //绑定多个pipe和tap,此处指定的是pipe名称 Map<String, Tap> sinks = Cascades.tapsMap( new String[]{"url pipe", "word pipe"}, Tap.taps( sinkUrl, sinkWord ) ); //wordCountPipe指的是一个装配 Flow count = flowConnector.connect( importedPages, sinks, wordCountPipe ); //创建一个装配,导出hadoop sequenceFile 到本地文本文件 Pipe exportPipe = new Each( "export pipe", new Identity() ); Tap localSinkUrl = new Lfs( new TextLine(), localUrlsPath ); Tap localSinkWord = new Lfs( new TextLine(), localWordsPath ); // 使用上面的装配来连接两个sink Flow exportFromUrl = flowConnector.connect( "export url", sinkUrl, localSinkUrl, exportPipe ); Flow exportFromWord = flowConnector.connect( "export word", sinkWord, localSinkWord, exportPipe ); ////装载flow,顺序随意,并执行 Cascade cascade = new CascadeConnector().connect( importPagesFlow, count, exportFromUrl, exportFromWord ); cascade.complete(); } }
以上是关于cascading--wordcount的主要内容,如果未能解决你的问题,请参考以下文章