android coredump 怎么生成 kill
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了android coredump 怎么生成 kill相关的知识,希望对你有一定的参考价值。
查看 error log:
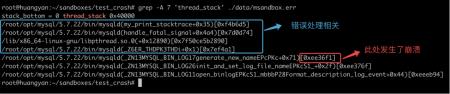
我们拿到了崩溃位置0xee36f1,如何找到与之相对的代码位置呢?
找台测试机,获取对应版本的安装包:
解压:

然后用 GDB 打开 mysqld:
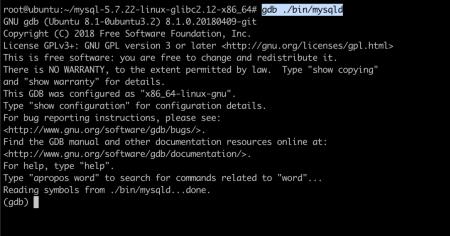
在 0xee36f1 位置打一个断点:

我们可以看到,gdb 将崩溃位置的文件名和行号都打印出来,
剩下的事情,就可以交给开发工程师,按照这个崩溃堆栈来进行问题排查。
赠送章节
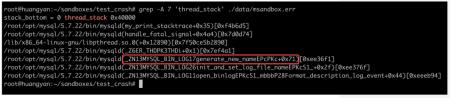
红框内的这串信息是什么?我们来解开看一下,
这段信息分为两段,"+0x71" 是一个偏移量,前面是一串文字,我们将文字解析出来:

可以看到前面这串文字是一个函数签名的编码,用 c++filt 还原编码以后,可以看到完整的函数签名。
红框内的这串信息的意思就是崩溃位置是 一个函数起始位置 + 偏移量。
我们大概可以猜到,这个 MySQL 的缺陷是在为 binlog 产生新的文件名时发生的。
小贴士:
函数起始位置 + 偏移量 是一种内存位置的表示方法,但该位置不一定是这个函数内的代码。
以本例来说,0xee36f1 这个位置,程序找到了就近的函数 generate_new_name 的起始位置,计算出有 0x71 这么多偏移,就表示成了 generate_new_name+0x71 这种形式。
但 0xee36f1 这个位置的代码,大概率是,但,不一定是 generate_new_name 这个函数内部的一段代码。
参考技术A 手动coredump状态:连接gdb -gcore pid
终端发送signal终止process: kill -s signal pid 自然发送能产生coredump的signal ,前文有记录,但是有时一次还杀不掉process signal可以被忽视。本回答被提问者采纳 参考技术B 对啊
linux 怎么分析core文件
从接触unix开始就一直听到和遇到core dump,特别是刚学着使用C语言在AIX下编写程序的时候,core dump更是时不时就会不请自来。记得当时刚写应用的时候,提交程序时最怕的就是在运行过程时遇到core dump,对于银行核心系统,特别是使用静态应用进程,如果一个相对频繁一点的交易导致core dump,那么毫无疑问,除了赶紧定位错误改程序外,重启进程甚至无法争取到多少缓冲的时间来进行代码的更正和测试。而且往往导致core dump的,就是程序中一个小小的未注意到或者未测试到的一个疏忽。虽然常常遇到core dump,不过很长时间内,都是出于知道这个名字,知道它导致的后果,知道一部分导致它出现的原因,其他的就都不甚了了了。说起来,就是自己太懒了,懒得看书......少壮不努力啊。看过一则统计,说60岁以上的老人,超过70%都后悔少壮不努力,不知统计的数据能否反映整个社会的情况。不过总的来说,这句古话还是有些道理的。大家不要学我。哈哈
core dump,翻译过来讲,就是核心转储。大致上就是指,如果由于应用错误,如浮点异常、指令异常等,操作系统将会转入内核的异常处理,向对应的进程发送特定的信号(SIGNAL),如果进程中没有对这些信号进行处理,就会转入默认的处理,core dump就是其中的一种。如果进程core dump,系统将会终止该进程,同时系统会产生core文件,以供调试使用。这个core文件其实就是内存的映像,即进程执行的时候内存的内容,也就是所谓的core dump。平常大家说某某进程core dump了,其实主要的意思就是说:某某进程因为错误而被系统自动终止了。
AIX上提供了dbx工具可以对core dump进行调试,协助定位引起core dump的代码。最普通的语法是:
dbx 应用名 core文件, 然后使用where命令来显示调试信息
一般来讲,根据工作中遇到的情况,dbx还是能够比较轻松的根据提示的内容来定位代码的。不过也有一些特殊情况时,dbx显示的调试信息过于模糊或者不直观,这个时候就只能根据经验来逐步定位了。有时定位起来会耗用相当长的时间。遇到这种情况时,使用日志文件,通过在代码中穿插多个写log的语句,也可以协助发现。因为进程core dump时,日志当然也中断了,根据日志在哪个代码行之后或之前中止了,可以有效缩小寻找的范围。甚至,在有些情况下,使用日志定位是唯一简便的方法了。 参考技术A Core,又称之为Core Dump文件,是Unix/Linux操作系统的一种机制,对于线上服务而言,Core令人闻之色变,因为出Core的过程意味着服务暂时不能正常响应,需要恢复,并且随着吐Core进程的内存空间越大,此过程可能持续很长一段时间(例如当进程占用60G+以上内存时,完整Core文件需要15分钟才能完全写到磁盘上),这期间产生的流量损失,不可估量。
凡事皆有两面性,OS在出Core的同时,虽然会终止掉当前进程,但是也会保留下第一手的现场数据,OS仿佛是一架被按下快门的相机,而照片就是产出的Core文件。里面含有当进程被终止时内存、CPU寄存器等信息,可以供后续开发人员进行调试。
关于Core产生的原因很多,比如过去一些Unix的版本不支持现代Linux上这种GDB直接附着到进程上进行调试的机制,需要先向进程发送终止信号,然后用工具阅读core文件。在Linux上,我们就可以使用kill向一个指定的进程发送信号或者使用gcore命令来使其主动出Core并退出。如果从浅层次的原因上来讲,出Core意味着当前进程存在BUG,需要程序员修复。从深层次的原因上讲,是当前进程触犯了某些OS层级的保护机制,逼迫OS向当前进程发送诸如SIGSEGV(即signal 11)之类的信号, 例如访问空指针或数组越界出Core,实际上是触犯了OS的内存管理,访问了非当前进程的内存空间,OS需要通过出Core来进行警示,这就好像一个人身体内存在病毒,免疫系统就会通过发热来警示,并导致人体发烧是一个道理(有意思的是,并不是每次数组越界都会出Core,这和OS的内存管理中虚拟页面分配大小和边界有关,即使不出Core,也很有可能读到脏数据,引起后续程序行为紊乱,这是一种很难追查的BUG)。
说了这些,似乎感觉Core很强势,让人感觉缺乏控制力,其实不然。控制Core产生的行为和方式,有两个途径:
1.修改/proc/sys/kernel/core_pattern文件,此文件用于控制Core文件产生的文件名,默认情况下,此文件内容只有一行内容:“core”,此文件支持定制,一般使用%配合不同的字符,这里罗列几种:
%p 出Core进程的PID
%u 出Core进程的UID
%s 造成Core的signal号
%t 出Core的时间,从1970-01-0100:00:00开始的秒数
%e 出Core进程对应的可执行文件名
2.Ulimit –C命令,此命令可以显示当前OS对于Core文件大小的限制,如果为0,则表示不允许产生Core文件。如果想进行修改,可以使用:
Ulimit –cn
其中n为数字,表示允许Core文件体积的最大值,单位为Kb,如果想设为无限大,可以执行:
Ulimit -cunlimited
产生了Core文件之后,就是如何查看Core文件,并确定问题所在,进行修复。为此,我们不妨先来看看Core文件的格式,多了解一些Core文件。
首先可以明确一点,Core文件的格式ELF格式,这一点可以通过使用readelf -h命令来证实,如下图:
从读出来的ELF头信息可以看到,此文件类型为Core文件,那么readelf是如何得知的呢?可以从下面的数据结构中窥得一二:
其中当值为4的时候,表示当前文件为Core文件。如此,整个过程就很清楚了。
了解了这些之后,我们来看看如何阅读Core文件,并从中追查BUG。在Linux下,一般读取Core的命令为:
gdb exec_file core_file
使用GDB,先从可执行文件中读取符号表信息,然后读取Core文件。如果不与可执行文件搅合在一起可以吗?答案是不行,因为Core文件中没有符号表信息,无法进行调试,可以使用如下命令来验证:
Objdump –x core_file | tail
我们看到如下两行信息:
SYMBOL TABLE:
no symbols
表明当前的ELF格式文件中没有符号表信息。
为了解释如何看Core中信息,我们来举一个简单的例子:
#include “stdio.h”
int main()
int stack_of[100000000];
int b=1;
int* a;
*a=b;
这段程序使用gcc –g a.c –o a进行编译,运行后直接会Core掉,使用gdb a core_file查看栈信息,可见其Core在了这行代码:
int stack_of[100000000];
原因很明显,直接在栈上申请如此大的数组,导致栈空间溢出,触犯了OS对于栈空间大小的限制,所以出Core(这里是否出Core还和OS对栈空间的大小配置有关,一般为8M)。但是这里要明确一点,真正出Core的代码不是分配栈空间的int stack_of[100000000], 而是后面这句int b=1, 为何?出Core的一种原因是因为对内存的非法访问,在上面的代码中分配数组stack_of时并未访问它,但是在其后声明变量并赋值,就相当于进行了越界访问,继而出Core。为了解释得更详细些,让我们使用gdb来看一下出Core的地方,使用命令gdb a core_file可见:
可知程序出现了段错误“Segmentation fault”, 代码是int b=1这句。我们来查看一下当前的栈信息:
其中可见指令指针rip指向地址为0×400473, 我们来看下当前的指令是什么:
这条movl指令要把立即数1送到0xffffffffe8287bfc(%rbp)这个地址去,其中rbp存储的是帧指针,而0xffffffffe8287bfc很明显是一个负数,结果计算为-400000004。这就可以解释了:其中我们申请的int stack_of[100000000]占用400000000字节,b是int类型,占用4个字节,且栈空间是由高地址向低地址延伸,那么b的栈地址就是0xffffffffe8287bfc(%rbp),也就是$rbp-400000004。当我们尝试访问此地址时:
可以看到无法访问此内存地址,这是因为它已经超过了OS允许的范围。
下面我们把程序进行改进:
#include “stdio.h”
int main()
int* stack_of = malloc(sizeof(int)*100000000);
int b=1;
int* a;
*a=b;
使用gcc –O3 –g a.c –o a进行编译,运行后会再次Core掉,使用gdb查看栈信息,请见下图:
可见BUG出在第7行,也就是*a=b这句,这时我们尝试打印b的值,却发现符号表中找不到b的信息。为何?原因在于gcc使用了-O3参数,此参数可以对程序进行优化,一个负面效应是优化过程中会舍弃部分局部变量,导致调试时出现困难。在我们的代码中,b声明时即赋值,随后用于为*a赋值。优化后,此变量不再需要,直接为*a赋值为1即可,如果汇编级代码上讲,此优化可以减少一条MOV语句,节省一个寄存器。
此时我们的调试信息已经出现了一些扭曲,为此我们重新编译源程序,去掉-O3参数(这就解释了为何一些大型软件都会有debug版本存在,因为debug是未经优化的版本,包含了完整的符号表信息,易于调试),并重新运行,得到新的core并查看,如下图:
这次就比较明显了,b中的值没有问题,有问题的是a,其指向的地址是非法区域,也就是a没有分配内存导致的Core。当然,本例中的问题其实非常明显,几乎一眼就能看出来,但不妨碍它成为一个例子,用来解释在看Core过程中,需要注意的一些问题。本回答被提问者采纳
以上是关于android coredump 怎么生成 kill的主要内容,如果未能解决你的问题,请参考以下文章