网页内容解析简单实现
Posted RexFang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了网页内容解析简单实现相关的知识,希望对你有一定的参考价值。
- 概述
在日常开发工作中,有时候我们需要去一些网站上抓取数据,要想抓取数据,就必须先了解网页结构,根据具体的网页结构,编写对应的程序对数据进行采集。最近刚好有一个需求,需要更新收货地址。由于系统现有的收货地址是很早以前的数据了,用户在使用的过程中反映找不到用户所在地的地址信息,因此对现有地址数据的更新也就提上了日程。
通过查找,最终找到了中华人民共和国国家统计局官网上有需要的地址数据,官方渠道,数据的准确性、完整性都有保障。本文采用国家统计局截止到2016年7月31日公布的数据(目前最新的数据)为例子进行演示,有关页面结构的分析我这里就不多说了(开发基本技能),直接上代码吧,并附上完整的DEMO。
- 需要解析页面效果

- POM 配置文件
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>crawler</groupId> <artifactId>crawler</artifactId> <version>0.0.1-SNAPSHOT</version> <build> <sourceDirectory>src</sourceDirectory> <plugins> <plugin> <artifactId>maven-compiler-plugin</artifactId> <version>3.5.1</version> <configuration> <source>1.6</source> <target>1.6</target> </configuration> </plugin> </plugins> </build> <dependencies> <dependency> <groupId>org.jsoup</groupId> <artifactId>jsoup</artifactId> <version>1.7.2</version> </dependency> <dependency> <groupId>net.sf.json-lib</groupId> <artifactId>json-lib</artifactId> <version>2.4</version> <classifier>jdk13</classifier><!--指定jdk版本--> </dependency> </dependencies> </project>
- 地址节点 Location 文件
package crawler; import java.util.List; public class Location { String code; String name; List<Location> children; public Location(){ } public Location(String code, String name){ this.code = code; this.name = name; } public String getCode() { return code; } public void setCode(String code) { this.code = code; } public String getName() { return name; } public void setName(String name) { this.name = name; } public List<Location> getChildren() { return children; } public void setChildren(List<Location> children) { this.children = children; } }
- 测试类 TestMain
package crawler; import java.io.IOException; import java.util.ArrayList; import java.util.List; import java.util.regex.Matcher; import java.util.regex.Pattern; import org.jsoup.Jsoup; import org.jsoup.nodes.Document; import org.jsoup.nodes.Element; import org.jsoup.select.Elements; import net.sf.json.JSONObject; public class TestMain { public static void main(String[] args) throws IOException { Document doc = Jsoup.connect("http://www.stats.gov.cn/tjsj/tjbz/xzqhdm/201703/t20170310_1471429.html").get(); Element masthead = doc.select("div.xilan_con").first(). getElementsByClass("TRS_Editor").first(). getElementsByClass("TRS_PreAppend").first(); Elements allElements = masthead.getElementsByTag("p"); List<Location> provinceList = new ArrayList<Location>(); Location province = null; Location city = null; for(Element element : allElements){ String html = element.select("span[lang]").first().html(); String locationCode = TestMain.getLocationCode(html); String locationName = element.select("span[style]").last().html(); if(locationCode.endsWith("0000")){ //省或直辖市 province = new Location(locationCode, locationName); province.setChildren(new ArrayList<Location>()); provinceList.add(province); }else if(locationCode.endsWith("00")){ //市 city = new Location(locationCode, locationName); city.setChildren(new ArrayList<Location>()); province.getChildren().add(city); }else{ //县或区 Location county = new Location(locationCode, locationName); city.getChildren().add(county); } } Location root = new Location("0", "root"); root.setChildren(provinceList); JSONObject jsonObj = JSONObject.fromObject(root); System.out.println(jsonObj.toString()); } public static String getLocationCode(String html){ String regEx="[^0-9]"; Pattern p = Pattern.compile(regEx); Matcher m = p.matcher(html); return m.replaceAll("").trim(); } }
- 结果(数据下载)
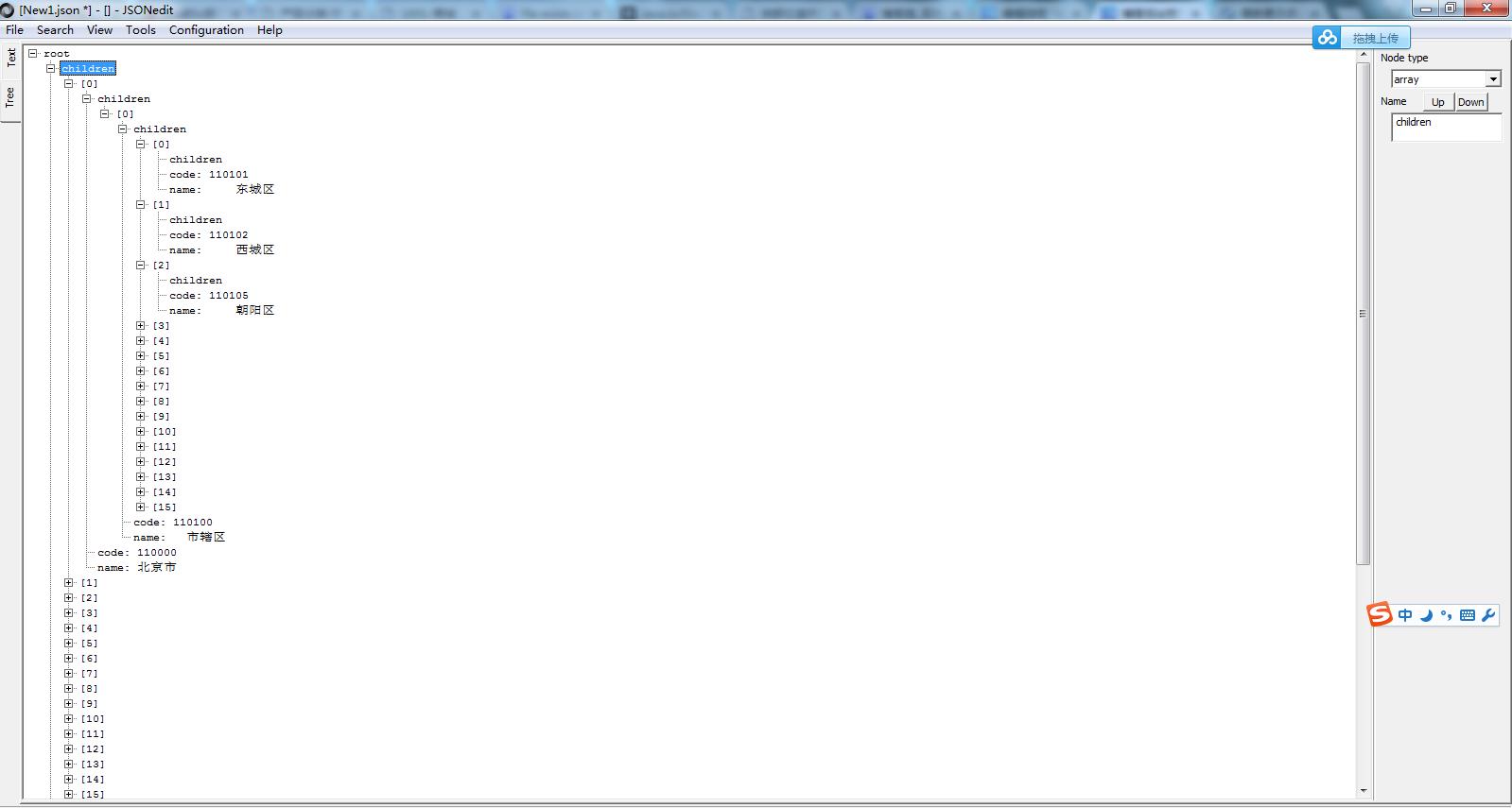
以上是关于网页内容解析简单实现的主要内容,如果未能解决你的问题,请参考以下文章