AdaBoosting 3
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了AdaBoosting 3相关的知识,希望对你有一定的参考价值。
在学习AdaBoosting和online Boosting, 最好有bagging和boosting基础,这样看起来比较会比较顺。有空再补上。
AdaBoost 算法的主要思想之一就是在训练集上维护一套权重分布,初始化时 ,Adaboost 为训练集的每个训练例指定相同的权重 1/m。接着调用弱学习算法进行迭代学习。每次迭代后更新训练集上不同样本的权值,对训练失败的样本赋以较大的权重,也就是让学习算法在后续的学习过程中集中对比较难的训练例进行学习
首先给定一个弱学习算法和训练集 ( x1 , y1 ), ( x2 , y2 ),..., ( xN , y N ) ,xi ∈ X , 表示某个X实例空间; yi ∈ Y = {1, −1} ,Y 表示一个带类别标志的集合。在每一步的迭代中,弱学
弱假设 ht 的性能由习算法根据训练样本的分布及权重 Dt 产生一个弱假设 ht :X→{1,-1}。
它的误差 ε m来衡量:
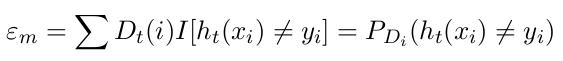
误差 ε m 的大小与训练弱学习算法所依赖的样本分布 Dt 相关,可以理解为对于权值较大
的样本错分会导致较大的误差增量。这样设计误差函数的目的正如前文所描述的,在
于使学习算法在后续的学习过程中集中对比较难的训练例进行学习。AdaBoost 算法根
据每次迭代后得到的预测结果,为每个弱分类器根据预测的结果赋予一个权值,最终
的预测结果由每个弱分类器通过带权重的投票方式产生。

online Adaboost
和online算法对应是offline算法(在线学习算法和离线学习算法),以前我学的大多数都是offline算法,例如,svm,神经网络等算法
offline算法最明显的特征是:首先训练模型,模型训练完就预测,预测得到一个结果,没有考虑到预测的样本对模型的影响。
而online算法:首先也要训练一个简单的模型,其主要在预测的过程中学习,由于预测的样本没有保存在内存中,只有一次的学习机会。
online adaboost, 这篇文章发表于CVPR2006引用率蛮高,在tracking方面特别牛逼。
下面来介绍一下这篇文章的主要思想,这篇文章最好最好要有online boosting基础。也和online boosting差不多。先看算法的流程。
首先介绍一下选择选择器(selectors)和分类器(classifier).
在算法的开始,每个选择器里面都有m个弱分类器,算法的目的就是每个选择器在m个分类器中找出最优的一个分类器。然后再把n个选择器组合起来。这种思想确实和adbooost一样。m个弱分类器可以自己建立,也可以在每一维上建立分类器。
λ的作用是样本在每个分类上的权重。当第一个选择器分类正确是,λ的值就回减少,否则就增加,这也和adboost有点像。
αn表示每个选择器的权重,是按选择器错误率来定权的,这也和adboost有点像。所以online adoosting就是offline adboosting算法的山寨版。


这几年的cvpr上的几篇做tracking的文章以这个idea为基础。tracking的方法是用最近比较流行的tracking-by-detection的方法。简答的说就是在tracking的时候,observation model这一块是用一个在线训练的分类器。tracking的过程如下图所示(图中还有一步是用跟踪的结果作为训练器的新的输入):

以上是关于AdaBoosting 3的主要内容,如果未能解决你的问题,请参考以下文章