04 基于上下文相关的GMM-HMM声学模型2之参数共享
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了04 基于上下文相关的GMM-HMM声学模型2之参数共享相关的知识,希望对你有一定的参考价值。
1.三音素建模存在的问题
问题一:很多三音素在训练数据中没有出现(尤其跨词三音素)
问题二:在训练数据中出现过的三音素有相当一部分出现的频次较少
因此,三音素模型训练时存在较严重的数据不足问题
2.参数共享
1)何为参数共享?
对于一个HMM模型来说,有如下参数:

两个模型之间参数共享,意为:
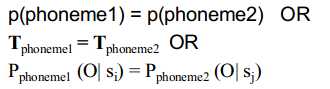
如:
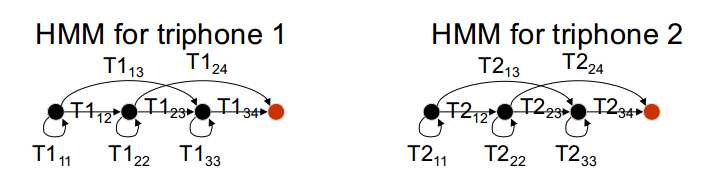
共享转移概率:
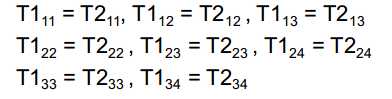
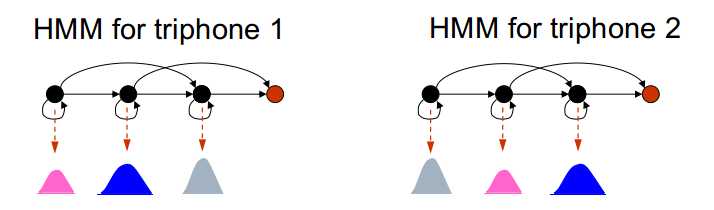
共享状态输出分布:
2)共享可以在不同的层次上进行
(1)共享高斯---tied mixtures
所有分布共享相同的高斯集合,但拥有不同的混合权重
(2)共享状态---state clustering
允许不同的模型共享相同的状态
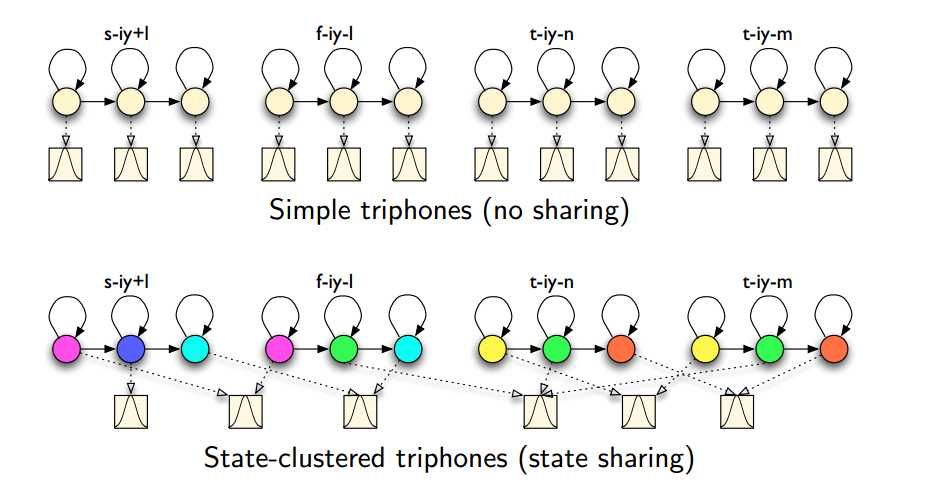
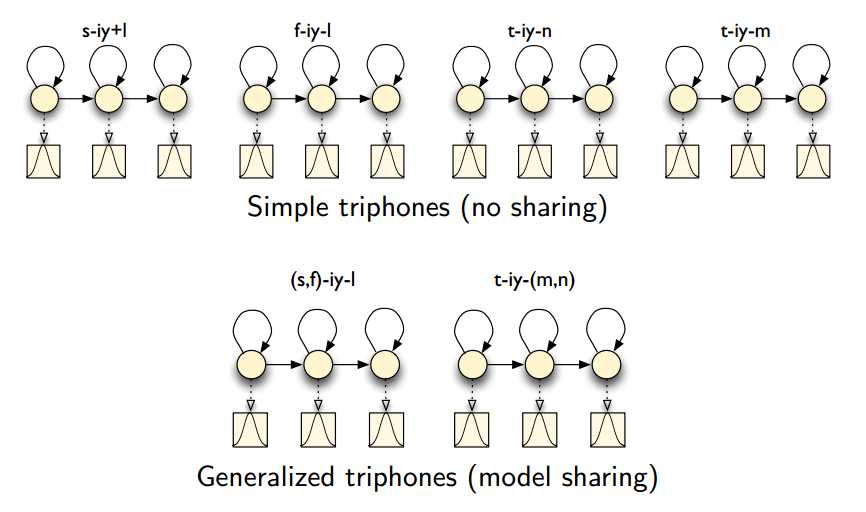
(3)共享模型---generalized triphones
根据相似性,允许不同的三音素共享相同的模型
3.共享状态/状态绑定---决策树
1)背景
传统方法:共享模型形成泛化三音素,使用后验平滑技术
---不能独立对待左右音素
基于数据驱动聚簇的状态绑定:距离度量取决于以状态方差缩放的状态均值之间的欧氏距离
---对于词内三音素效果较好,对于跨词三音素效果不好
---能有效解决问题二,不能有效解决问题一
基于决策树的状态绑定
---能有效解决问题一和二
2)利用决策树进行状态绑定
三音素的总数取决于音素集,词典以及语法约束
关于转移概率矩阵,规定基于相同单音素的三音素模型共享单音素的转移概率矩阵,如:
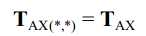
关于状态输出分布的共享:利用决策树进行确定
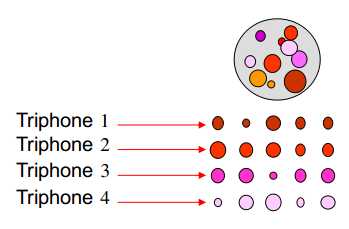
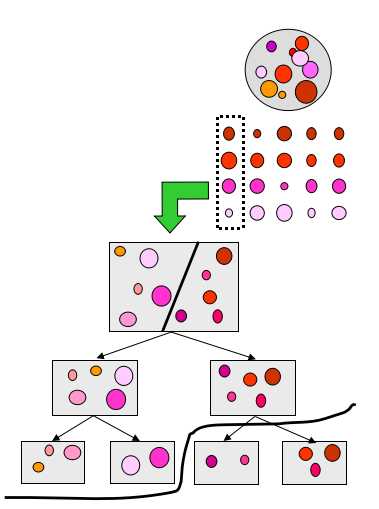
大球:一个单音素对应的所有状态/所有观测数据
每一行代表一个特定上下文环境下的单音素的所有状态/所有观测数据,即三音素模型
每一行的每个小球代表该行对应的三音素模型(5状态模型)的中每个状态/每个状态对应的观测数据
如果对每一行都训练一个单独的模型---无参数共享的上下文相关模型,存在数据不足问题
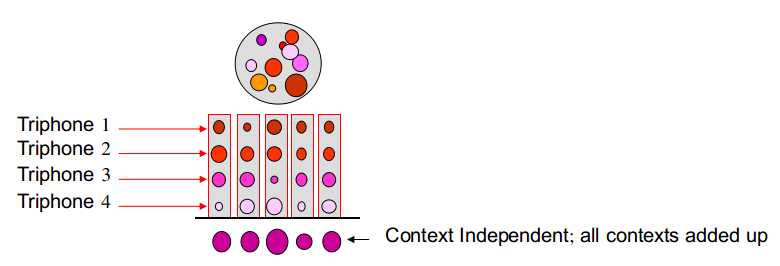
如果每一列对应的观测数据合并进行模型的训练---上下文无关的模型,数据足够,但未考虑上下文信息
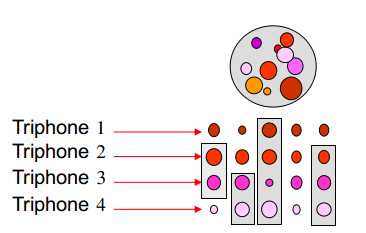
折中:每个列中的状态/观测数据进行分组,对每一组训练单独的分布---既考虑了上下文信息,又降低了数据不足的可能性
如何分组?
分组的目的是使得组内尽可能相似,同列的组外尽可能不相似
方式一:将球视为观测数据
数据集一致性得分的定义:基于数据分布的对数似然性的期望
常假设数据分布为高斯分布
如单个数据点的一致性得分为:
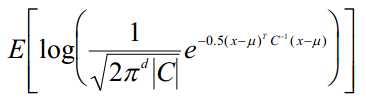
若数据集里有N个数据点,数据集一致性得分为:

d---数据点维数
C---状态输出分布协方差矩阵
分割数据集,整体一致性得分提高:

对任一列的数据进行分割会导致一致性得分的增加,找出使得增加值最大的分割方式
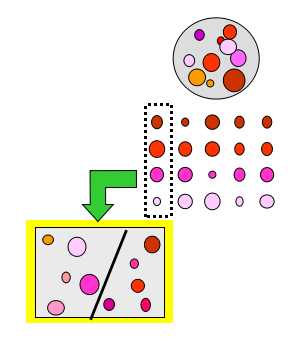
继续以相同的方式分别对子集合进行分割
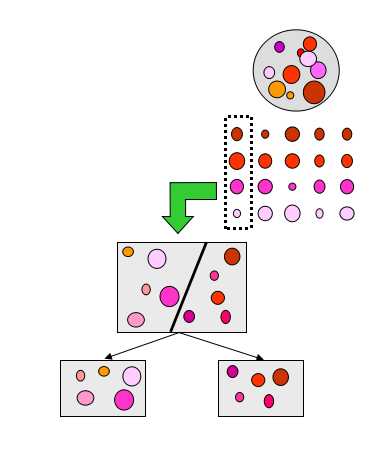
当增加值小于阈值或叶子节点中数据量小于阈值时停止分割
将球视为观测数据,每次对观测数据的划分视为对相应状态的划分,隐含着强制对齐的思想---每个观测数据属于一个状态
若有N个数据点,共有2的N-1种分割方式---穷举代价太大
常对取自事先定义好的分割规则集合即一些语言学问题集,如左音素是不是元音音素等的分割规则进行评分
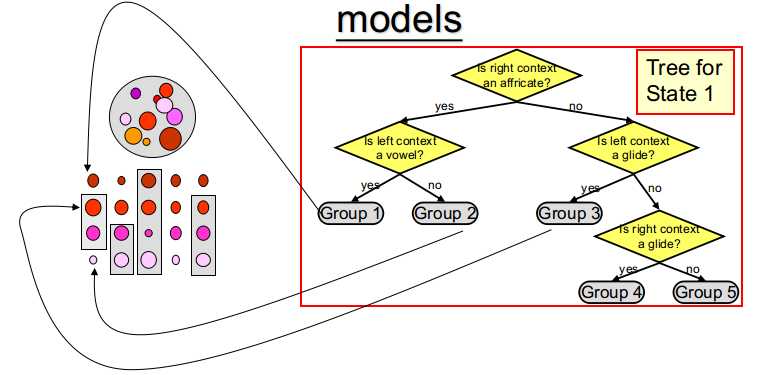
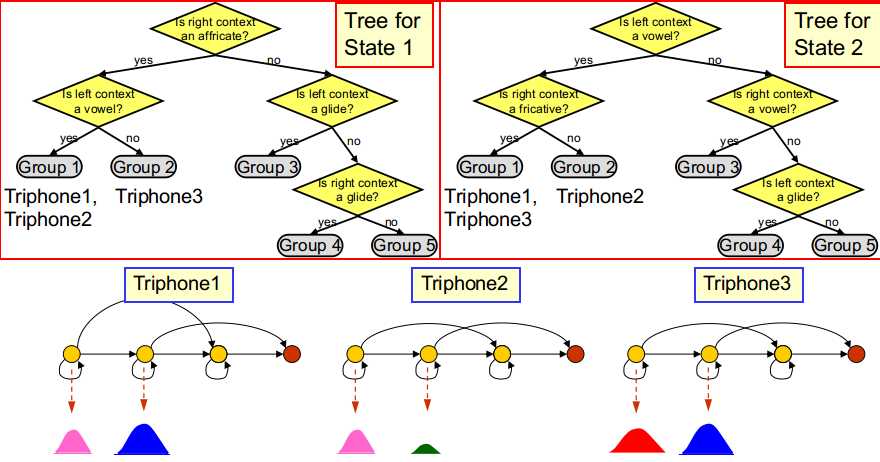
这些语言学问题集也可以自动生成
方式二:将球视为状态
计算与该状态集相关的数据的对数似然性作为状态集评分:


状态集的分割:


将球视为状态,每次对状态集进行划分,评分时用到了状态占有概率和高斯参数,隐含着软分配的思想---每个观测数据以一定的概率值属于每个状态
3)语言学问题的自动生成---混合bottom-up-top-down方式
(1)将每个单音素的状态作为一组---bottom ip
将所有单音素的状态分为一组---top down
注意:对每一个单音素,只使用其中的一个状态
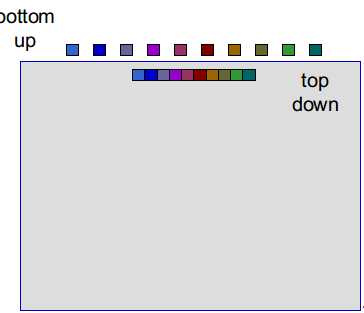
(2)将bottom up层最为相似的组聚为一簇
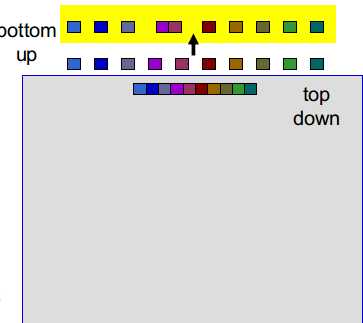
(3)重复这个过程,直到剩余K簇(4至16)---这时,我们可以穷举所有分割方式
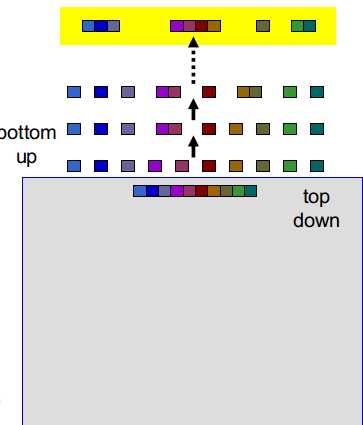
(4)评分所有分割方式

(5)其中,最好的分割方式作为将整体分为两组的问题
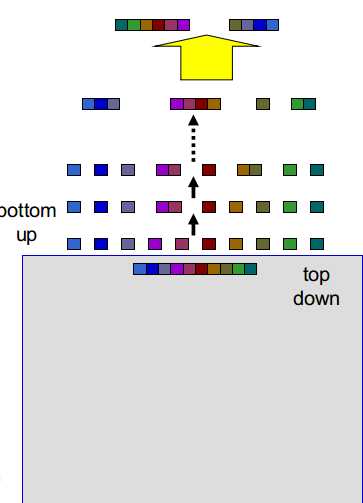
(6)将生成的两组作为top down层的第二层
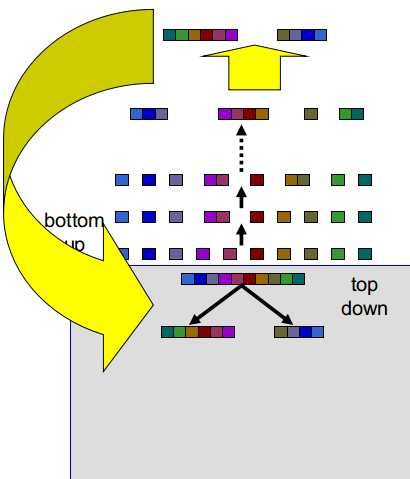
(7)每个组其实是一组状态的集合
(8)这两组可继续分别bottom up至剩余K簇,遍历选择最好的分割方式分别分为两组
(9)新组作为top down的第三层
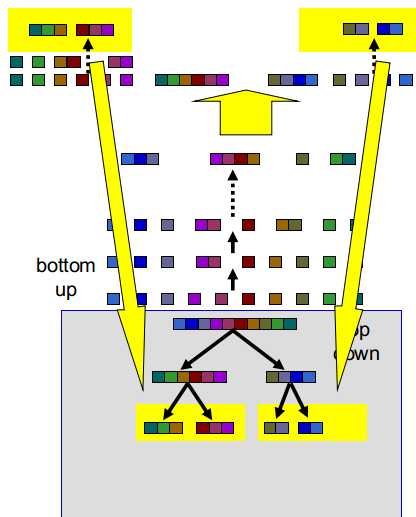
(10)重复至完成top down树
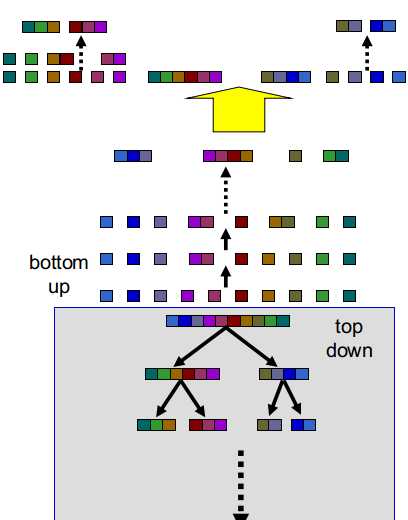
top down树的分组结果可作为语言学问题集
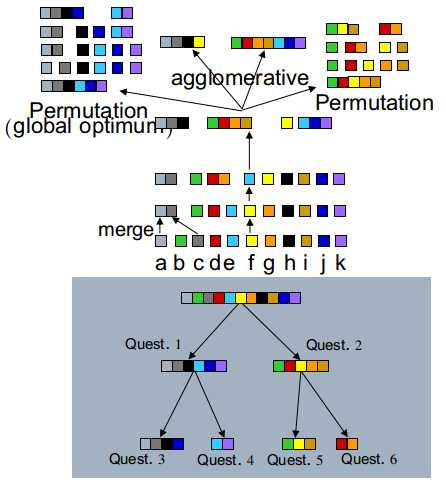
top down---最优化但代价高
bottom up---可处理但次优化
利用这种混合方式获取了平衡
4)剪枝
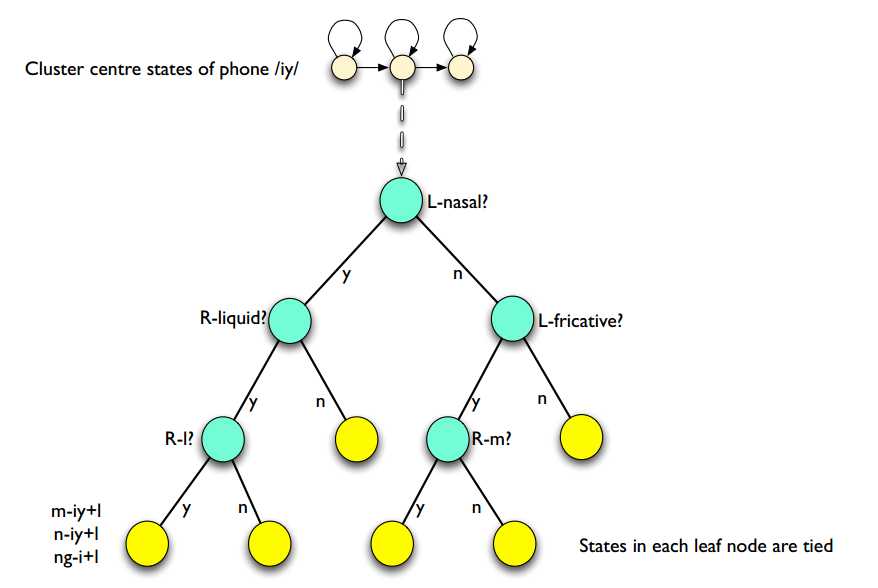
决策树会有很多叶子节点,每个叶子节点表示一个绑定的状态
如果绑定状态数过多,需要剪枝,使得决策树变浅
将评分增加最少的分枝减去,使其父节点成为叶子节点,重复至达到所需的叶子节点数
5)决策树的生成
(1)为所有在训练数据中出现的三音素训练无参数共享的HMM模型
(2)使用这些模型的参数来构建决策树
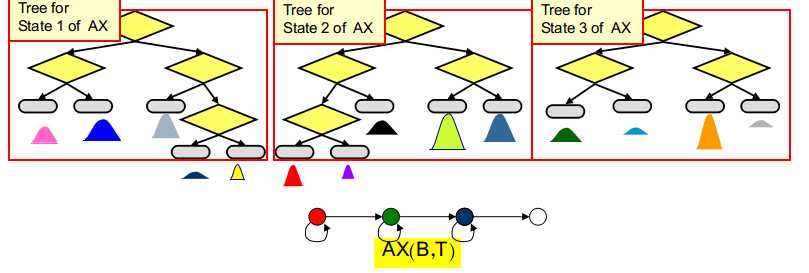
每个单音素的每个状态都会构建一棵单独的决策树,如为单音素"AX"的第一个状态构建的决策树代表所有"AX"对应的三音素模型的第一个状态的分组情况
(3)对所有单音素所有状态的决策树集合进行剪枝
在所有决策树中挑选出评分增加最少的叶子分枝,
将其剪去(在决策树集合中所需的叶子节点总数即绑定状态数需事先确定,常与训练数据量有关),
继续剪枝直到达到所需的叶子节点数
4.基于上下文相关的状态绑定三音素模型的训练
1)训练上下文无关的单音素GSM-HMM模型
2)训练上下文相关的三音素GSM-HMM模型
用单音素GSM-HMM模型的状态输出分布参数初始化所有相应的三音素GSM-HMM模型的状态输出分布参数,然后重新估计模型参数
单音素GSM-HMM模型的转移概率矩阵为所有相应的三音素GSM-HMM模型所共享
3)训练和剪枝决策树
如果有n个单音素,每个单音素有k个状态.共需要建立n*k棵决策树
4)训练上下文相关的状态绑定三音素GSM-HMM模型
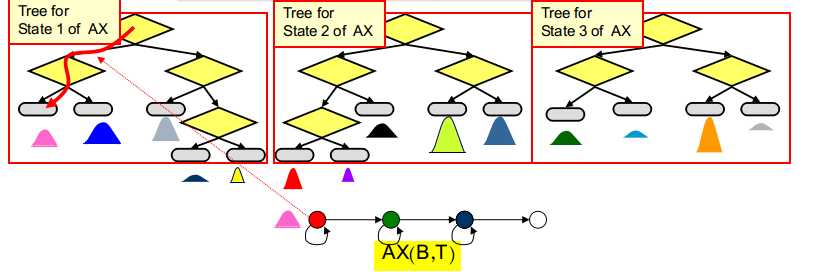
利用决策树进行状态绑定:
选出与相应单音素模型相关的所有决策树
将三音素模型的每个状态沿着对应决策树向下传递至叶子节点,叶子节点对应的状态输出分布即为该状态对应的输出分布
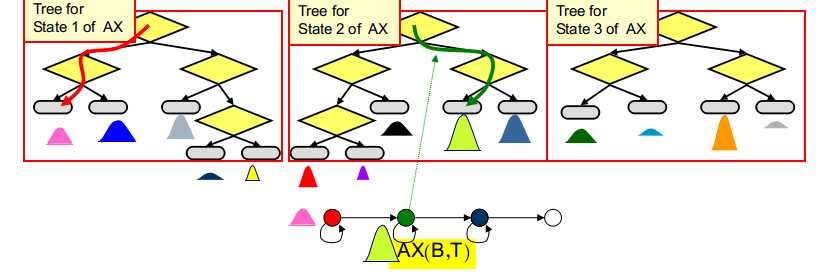
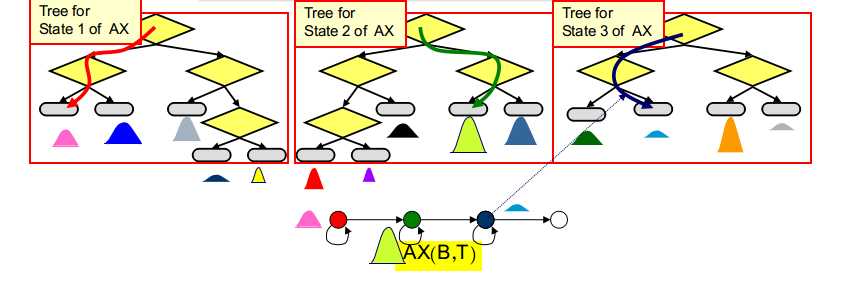
将对应单音素模型的转移概率矩阵作为所有三音素模型的转移概率矩阵
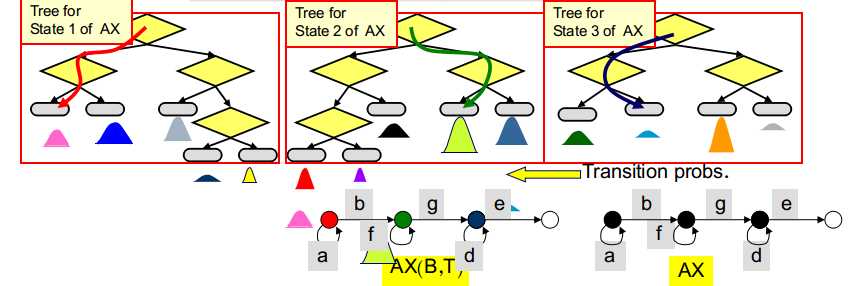
当然,没有必要每次都使用决策树来确定状态绑定信息,可通过建立索引表来存放该信息
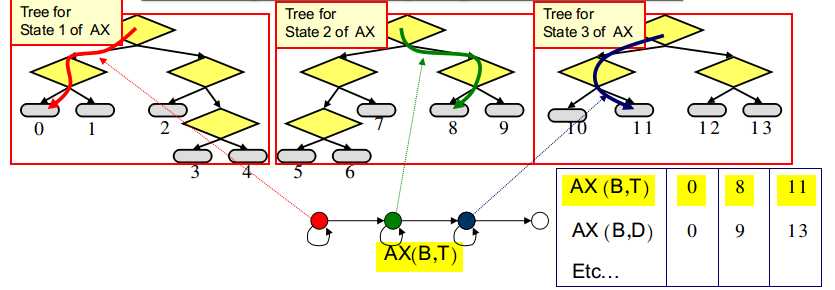
然后重新估计模型参数
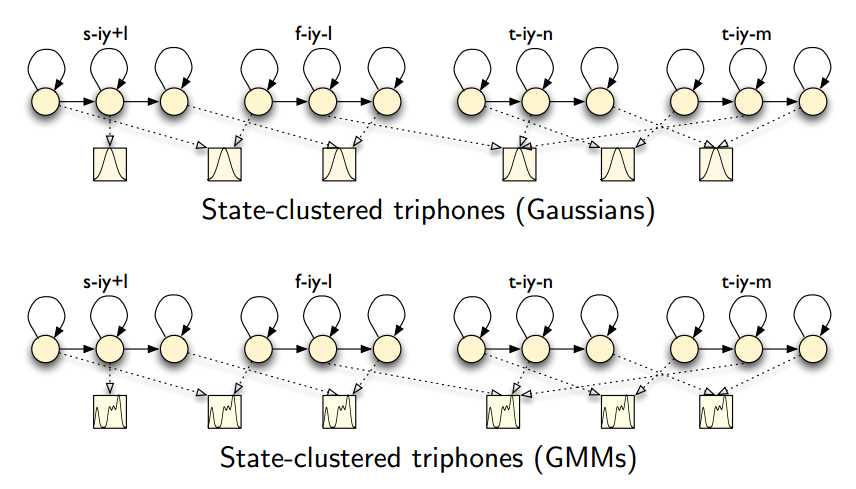
5)训练上下文相关的状态绑定三音素GMM-HMM模型
分裂高斯,然后重新估计模型参数
直至达到所需的高斯分量数
5.一些补充
不是所有的模型都共享状态
对于静音,噪声等,只需建立上下文无关的单音素模型
但,静音可作为上下文音素影响其他单音素的发音
以上是关于04 基于上下文相关的GMM-HMM声学模型2之参数共享的主要内容,如果未能解决你的问题,请参考以下文章