LL文法分析表的构造和分析过程示例
Posted 青山应回首
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了LL文法分析表的构造和分析过程示例相关的知识,希望对你有一定的参考价值。
在考完编译原理之后才弄懂,悲哀啊。不过懂了就好,知识吗,不能局限于考试。
E→TE\'
E\'→+TE\'|ε
T→FT \'
T\'→*FT\'|ε
F→id| (E)
一、首先判断是不是 LL(1)文法
--------------------------------------------------------------------------------------------------------
文法G的任意两个具有相同左部的产生式 A --> α|β 满足下列条件:
1、如果α和β不能同时推导出ε,则 FIRST(α)∩FIRST(β) = 空
2、 α和β 至多有一个能推导出 ε
3、如果 β --*--> ε ,则 FIRST(α)∩ FOLLOW(A)= 空
--------------------------------------------------------------------------------------------------------
对于 E\'→+TE\'|ε ,显然ε --> ε, First(+TE\') = {+} ,Follow(E\') = {{),#} 显然二者交集为空满足。
对于 F→id|(E) ,First(id) = {id} First((E)) = {(} 显然二者交集为空满足。
所以该文法是LL(1)文法。
二、计算出First集和Follow集
参考:http://www.cnblogs.com/standby/p/6792774.html
三、构建LL(1)分析表
输入:文法G
输出:分析表M
步骤:
1、对G中任意一个产生式 A --> α 执行第2步和第3步
2、for 任意a ∈ First(α),将 A --> α 填入M[A,a]
3、if ε ∈ First(α) then 任意a ∈ Follow(A),将 A --> α 填入M[A,a]
if ε ∈ First(α) & # ∈Follow(A), then 将 A --> α 填入M[A,#] (觉得这步没用)
4、将所有没有定义的M[A,b] 标上出错标志 (留空也可以)
--------------------------------------------------------------------------------------------------------
过程就不赘述了,结果:

四、分析过程
步骤:
1、如果 X = a = # 则分析成功并停机
2、如果 X = a != # 则弹出栈顶符号X, 并将输入指针移到下一个符号上
3、如果 X != a,查询分析表M[X,a] , 如果 M[X,a] = {X --> UVW},
则用UVW (U在栈顶) 替换栈顶符号 X。如果 M[X,a] = error或空,
则分析器调用错误处理程序。
(只有在第2种条件下才将输入指针移动!!!)
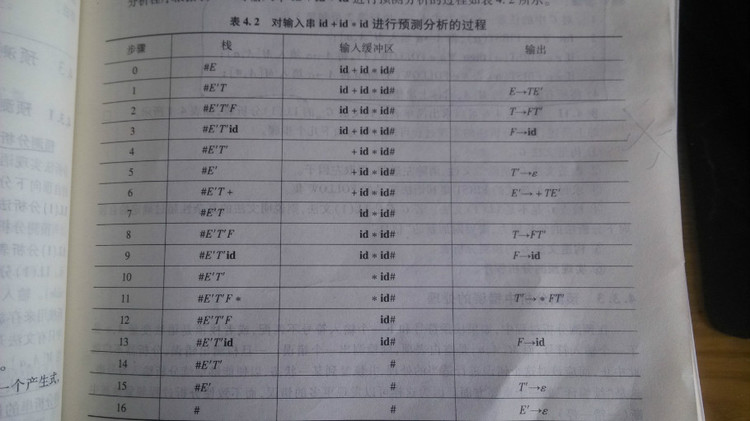
根据上表,对输入串 “id + id * id” 进行预测分析过程如下:
最开始在栈里压入 # 和 开始符号 E
以上是关于LL文法分析表的构造和分析过程示例的主要内容,如果未能解决你的问题,请参考以下文章