机器学习笔记(Washington University)- Regression Specialization-week one
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习笔记(Washington University)- Regression Specialization-week one相关的知识,希望对你有一定的参考价值。
1. Convex and concave functions
Concave is the upside-down of the convex function
and convex is a bow-shaped function
2. Stepsize
common choice:
as the iteration goes, we will decrease the stepsize against a fixed stepsize
alpha = alpha/t or alpha = alpha / (t ^0.5
and when the deriative is smaller than a set threshlod, we can stop the algorithm
3. Approach 1
set gradient=0, so we can solve for w0 and w1,
using those two equations:
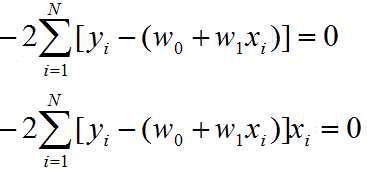
and we can get that:
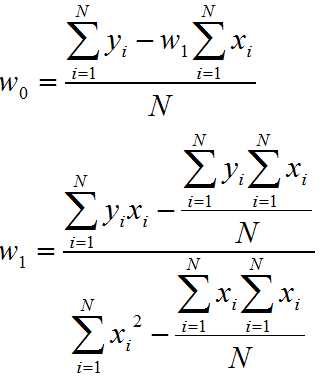
4. High leverage points
High leverage points mean that it ia at an extreme x value where there are no other observation. And
this point has the potential to change the least squares line since the center of x mass is heavily influenced
by this point.
an influential observation is one where the removal of the point siginificcantly changes the fit.‘
5. Asymmetric cost functions
This means the errors are not weighed equally between these two types of mistakes (too high and too low estimated price).
以上是关于机器学习笔记(Washington University)- Regression Specialization-week one的主要内容,如果未能解决你的问题,请参考以下文章