sql,表与表之间列的包含查询
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了sql,表与表之间列的包含查询相关的知识,希望对你有一定的参考价值。
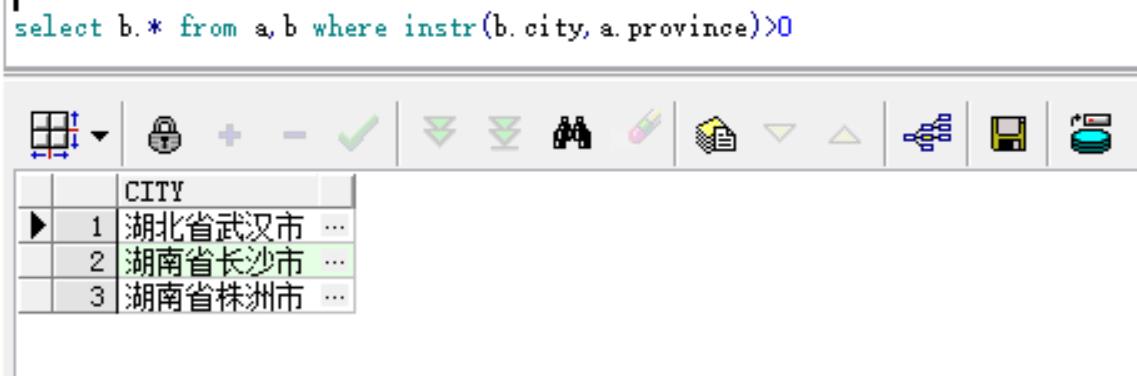
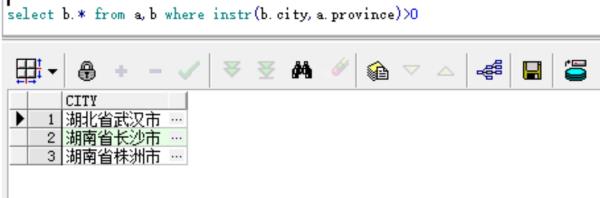
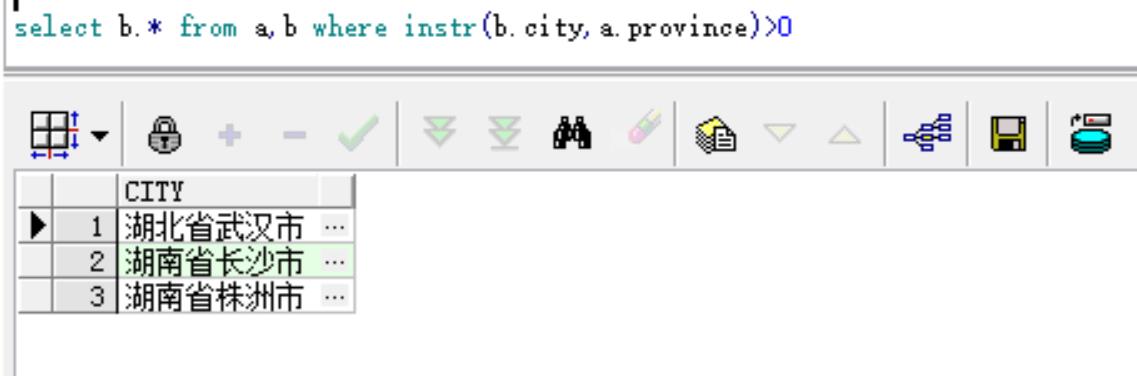
表一为特殊省份:a 比如(湖南省,湖北省,北京)
表二为详细地址:b比如(湖南省株洲市,湖北省xx市,湖南省长沙市)
查询出b表中所有包含a表中数据
结果为(湖南省株洲市,湖北省xx市)
用in只能筛选等于,而用like只能模糊查询单个
sql多表关联查询跟条件查询大同小异,主要是要知道表与表之前的关系很重要;
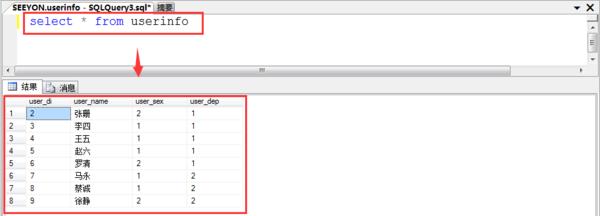
举例说明:(某数据库中有3张表分别为:userinfo,dep,sex)
userinfo(用户信息表)表中有三个字段分别为:user_di(用户编号),user_name(用户姓名),user_dep(用户部门) 。(关系说明:userinfo表中的user_dep字段和dep表中的dep_id字段为主外键关系,userinfo表中的user_sex字段和sex表中的sex_id字段为主外键关系)
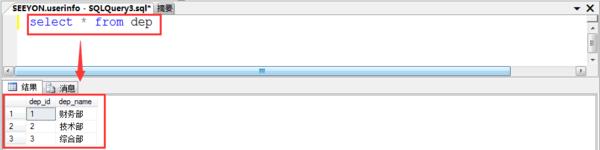
dep(部门表)表中有两个字段分别为:dep_id(部门编号),dep_name(部门名称)。(主键说明:dep_id为主键)
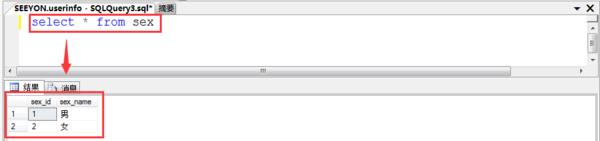
sex(性别表)表中有两个字段分别为:sex_id(性别编号),sex_name(性别名称)。(主键说明:sex_id为主键)
一,两张表关键查询
1、在userinfo(用户信息表)中显示每一个用户属于哪一个部门。sql语句为:
select userinfo.user_di,userinfo.user_name,dep_name from userinfo,dep where userinfo.user_dep=dep.dep_id
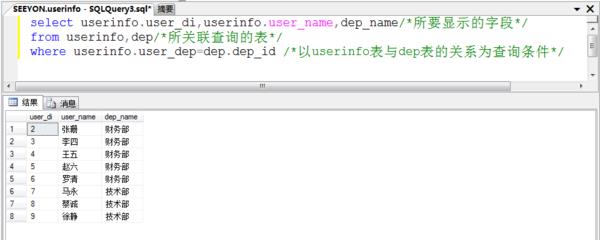
2、在userinfo(用户信息表)中显示每一个用户的性别。sql语句为:
select userinfo.user_di,userinfo.user_name,sex.sex_name from userinfo,sex where userinfo.user_sex=sex.sex_id
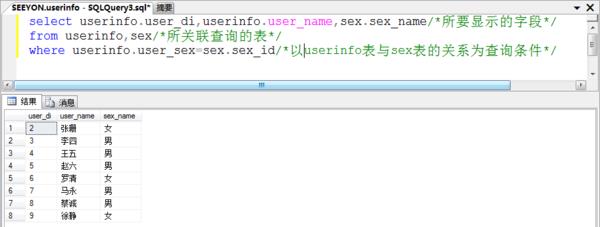
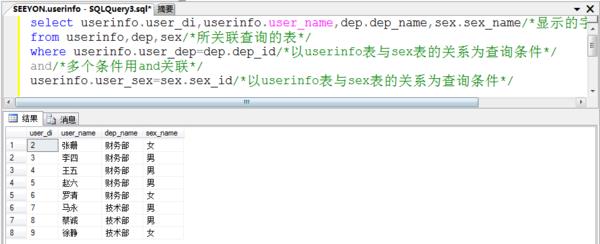
二、多张表关键查询
最初查询出来的userinfo(用户信息表)表中部门和性别都是以数字显示出来的,如果要想在一张表中将部门和性别都用汉字显示出来,需要将三张表同时关联查询才能实现。
sql语句为:
select userinfo.user_di,userinfo.user_name,dep.dep_name,sex.sex_name from userinfo,dep,sex where userinfo.user_dep=dep.dep_id and userinfo.user_sex=sex.sex_id
(多个条件用and关联)
oracle
追答创建测试表:
create table a(province varchar2(10));
create table b
(city varchar2(50));
insert into a values ('湖北省');
insert into a values ('湖南省');
insert into a values ('北京市');
insert into b values ('湖南省长沙市');
insert into b values ('湖南省株洲市');
insert into b values ('湖北省武汉市');
insert into b values ('河北省石家庄市');
commit;
执行:
结果:
这样?
0914 表与表之间的关系补充一对一关系 记录操作 关键字 多对多 子查询
1 表与表之间联系之一对一关系补充
生活中的一对一
客户表, 学员表
通过分析
一个客户只对应一个学员
一个学员只对应一个客户
所以确定关系为一对一
在mysql中通过外键来建立一对一
create table customer(id int primary key auto_increment,name char(10),phone char(11),sex char(1)); create table student(id int primary key auto_increment,name char(10),class char(11),sex char(1),c_id int, foreign key(c_id) references customer(id) on update cascade on delete cascade);
拷贝表
注意:索引 不能拷贝 描述不能拷贝(自增)
create table copy_table select * from customer; #拷贝结构与数据 create table copy_table select *from customer where 0>1; #仅拷贝结构
记录操作
详细操作
一下语法中
[]表示可选的
{}表示必选的
增
insert [into] 表名[字段名] value|values(字段值.....);
into 可省略
[字段名] 可选
如果写了 你后面的值 必须与 写的字段匹配
不写 后面的值 必须和表的结构完全匹配
value 插入一条记录
values 插入多条记录
改
update 表名 set 字段名 = 新的值[,字段n = 新值n] [where 条件]
可以同时修改多个字段 用逗号隔开 注意最后一个字段不能加逗号
where 可选
有就 修改满足条件的记录
没有就全部修改
delete from 表名 [where 条件]
where 可选
有就删除满足条件的记录
没有就全部删除
如果你需要全部删除 请使用truncate table 表名
delete 是逐行对比 删除 效率低
delete删除的行号会保留
查询
完整的查询语句
select [destinct] {*|字段名|聚合函数|表达式} from 表名
[where 条件
group by 字段名
having 条件
order by 字段名
limit 显示的条数
]
注意: 关键字的顺序必须与上述语法一致
简单查询
1.* 表示所有列 都显示
2.也可以手动指定要显示的列 可以是多个
3.distinct 用于去除重复的记录
只取出完全相同的记录
当然 你也可以手动指定要显示的列 从而来去重
4.表达式 支持四则运算
执行顺序
def select()
from 打开文件
where 读出每一行并判断是否满足条件
group by对数据进行分组
having 再分组之后进行过滤 having不单独出现 仅用于分组之后进行过滤
distinct 去重
order by 用于对于筛选后的数据 进行排序
limit 限制显示的条数
where关键字
从硬盘上读取数据时的一个过滤条件
where的筛选过程
在没有索引的情况下 挨个比较 效率低
所以我们应该给表添加索引
group by
作用 用于给数据分组
为什么要分组? 思考生活为什么要分组
1.在生活中是为了方便管理
2.在数据库中是为了 方便统计
准备数据
create table emp (id int,name char(10),sex char,dept char(10),job char(10),salary double);
insert into emp values (1,"刘备","男","市场","总监",5800),
(2,"张飞","男","市场","员工",3000),
(3,"关羽","男","市场","员工",4000),
(4,"孙权","男","行政","总监",6000),
(5,"周瑜","男","行政","员工",5000),
(6,"小乔","女","行政","员工",4000),
(7,"曹操","男","财务","总监",10000),
(8,"司马懿","男","财务","员工",6000);
按照部门给数据分组
select *from emp group by dept;
有两种情况
1.sql_mode中 没有设置 ONLY_FULL_GROUP_BY 显示每个组的第一条记录 没有意义 所以新版中 自带ONLY_FULL_GROUP_BY
2.sql_mode中有设置 ONLY_FULL_GROUP_BY 直接报错
原因是: * 表示所有字段都要显示 但是 分组后 记录的细节被隐藏 只留下了
这意味着:只有出现在group by 后面的字段才能被显示
分组是为了统计分组数据 如何统计?
需要使用到聚合函数
聚合函数:
将一堆数据经过计算,得到一个数据
sum() 求和
avg() 求平均数
max()/min() 求最大值 / 最小值
count() 个数
2.查询每个部?门有?几个?人
select dept,count(*) from emp group by dept;
3.计算每个部?门的平均?工资
select avg(salary) from emp group by dept;
总结 什么时候需要使用分组 只要你的需求中 带有 每个这样的字眼 就需要分组
每个岗位 每个部门 每个性别
5.查询平均?工资?大于5000的部?
select avg(salary) from emp where avg(salary) > 5000 group by dept;
where 语句后面 不能使用聚合函数
select avg(salary) from emp;
总结where 条件不能用于筛选分组后的数据
group_concat 用于分组后 将组中的某些字段拼接成字符串
select dept,group_concat(name) from emp group by dept;
其实 没啥意义 为啥? 你为什么要分组?是为了统计数据 如果你不需要统计 就没有必要分组
having 关键字
用于对分组后的数据进行过滤
having不会单独出现 都是和group by 一起出现
与where的区别
相同点: 都用于过滤数据
不同点:
1.where是最先执行 用于读取硬盘数据
having 要等到数据读取完之后 才能进过滤 比where晚执行
2.where中不能使用聚合函数
having中可以
order by [desc,asc]
用于对记录进行 排序
desc为降序
asc为升序
按照工资的从低到高顺序 显示所有的员工
select *from emp order by salary;
默认为升序
修改为降序
select *from emp order by salary desc;
按照每个部门的平均工资 降序排序
select dept,avg(salary) from emp group by dept order by avg(salary) desc;
limit 关键字
用于限制显示的条数
limit [start,]count
# 看看表里前三条数据
select *from emp limit 3;
# 看看表里的3-5条
select * from emp limit 2,3;
# 查看工资最高的那个人的信息
select *from emp order by salary desc limit 1;
limit 常用于 数据的分页展示 比如腾讯新闻 的上拉加载新的而一页
子查询
什么是子查询:将上一次查询的结果 作为本次查询的原始数据(或是查询条件)
以上是关于sql,表与表之间列的包含查询的主要内容,如果未能解决你的问题,请参考以下文章