Spark学习笔记——Spark上数据的获取处理和准备
Posted tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark学习笔记——Spark上数据的获取处理和准备相关的知识,希望对你有一定的参考价值。
数据获得的方式多种多样,常用的公开数据集包括:
1.UCL机器学习知识库:包括近300个不同大小和类型的数据集,可用于分类、回归、聚类和推荐系统任务。数据集列表位于:http://archive.ics.uci.edu/ml/
2.Amazon AWS公开数据集:包含的通常是大型数据集,可通过Amazon S3访问。这些数据集包括人类基因组项目、Common Crawl网页语料库、维基百科数据和Google Books Ngrams。相关信息可参见:http://aws.amazon.com/publicdatasets/
3.Kaggle:这里集合了Kaggle举行的各种机器学习竞赛所用的数据集。它们覆盖分类、回归、排名、推荐系统以及图像分析领域,可从Competitions区域下载: http://www.kaggle.com/competitions
4.KDnuggets:这里包含一个详细的公开数据集列表,其中一些上面提到过的。该列表位于:http://www.kdnuggets.com/datasets/index.html
下面采用的数据集是MovieLens 100k数据集,MovieLens 100k数据集包含表示多个用户对多部电影的10万次评级数据,也包含电影元数据和用户属性信息。
在目录下,可以查看文件中的前5行的数据
head -5 u.user 1|24|M|technician|85711 2|53|F|other|94043 3|23|M|writer|32067 4|24|M|technician|43537 5|33|F|other|15213
现在使用Spark交互式终端来对数据进行可视化的操作,以直观的了解数据的情况
1.安装ipython
IPython是针对Python的一个高级交互式壳程序,包含内置一系列实用功能的pylab,其中有NumPy和SciPy用于数值计算,以及matplotlib用于交互式绘图和可视化
sudo apt-get install ipython
2.安装anaconda,安装的文件是Anaconda2-4.3.1-Linux-x86_64.sh,可以在清华的开源软件镜像站下载
一个预编译的科学Python套件
bash Anaconda2-4.3.1-Linux-x86_64.sh #一路回车 #文件讲会安装在~目录下 #在询问是否把anaconda的bin添加到用户的环境变量中,选择yes source ~/.bashrc
在/etc/profile中添加
export PATH=/home/lintong/anaconda2/bin:$PATH
3.启动Hadoop,在Hadoop的安装目录的sbin目录下启动start-all.sh
4.启动pyspark,注意使用的spark的版本是2.1.0,所以参数和低版本的会有不同,下图是启动后的界面
PYSPARK_DRIVER_PYTHON=/usr/bin/ipython PYSPARK_DRIVER_PYTHON_OPTS="--pylab" pyspark
5.把训练数据集文件放在Hadoop文件系统中
hadoop fs -put /XXXtinput/ml-100k /user/XXX
6.代码
user_data = sc.textFile("/user/common/ml-100k/u.user")
user_data.first()

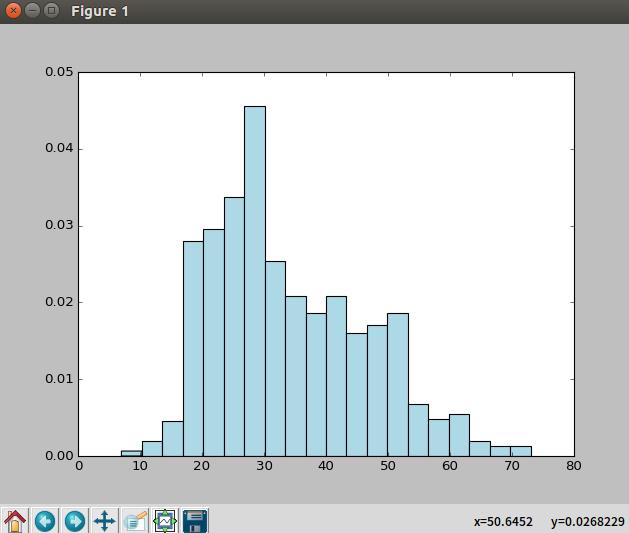
user_fields = user_data.map(lambda line: line.split("|"));\\
ages = user_fields.map(lambda x: int(x[1])).collect();\\
hist(ages, bins=20, color=\'lightblue\', normed=True);\\
fig = matplotlib.pyplot.gcf();\\
fig.set_size_inches(16, 10)
count_by_occupation = user_fields.map(lambda fields: (fields[3], 1)).reduceByKey(lambda x, y: x + y).collect() #或者 count_by_occupation = user_fields.map(lambda fields: fields[3]).countByValue() x_axis1 = np.array([c[0] for c in count_by_occupation]) y_axis1 = np.array([c[1] for c in count_by_occupation]) #升序排序 x_axis = x_axis1[np.argsort(y_axis1)] y_axis = y_axis1[np.argsort(y_axis1)] pos = np.arange(len(x_axis)) width = 1.0 ax = plt.axes() ax.set_xticks(pos + (width / 2)) ax.set_xticklabels(x_axis) plt.bar(pos, y_axis, width, color=\'lightblue\') plt.xticks(rotation=30) fig = matplotlib.pyplot.gcf() fig.set_size_inches(16, 10)

以上是关于Spark学习笔记——Spark上数据的获取处理和准备的主要内容,如果未能解决你的问题,请参考以下文章
如何在资源有限的笔记本电脑上安装 pyspark 和 spark 用于学习目的?