郁金香搜索引擎的方案
Posted 编程一生
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了郁金香搜索引擎的方案相关的知识,希望对你有一定的参考价值。
先介绍学心理学的时候记住的两个把妹秘籍:
1>巴甫洛夫把妹法:巴甫洛夫的狗的反射试验上学的时候大家都应该学过,天天给狗喂食的时候摇铃,后来不喂食只摇铃狗还是分泌唾液。应用到把妹这个非常有实际意义的事情上面就是:每天给妹子送早晨,等人家形成了习惯,突然不送了,人家就开始觉得不自在了,开始各种想这个男孩纸~~
2>吊桥效应:在吊桥上,由于危险的情境,人们会不自觉地心跳加快,错把由这种情境引起的心跳加快理解为对方使自己心动,才产生的生理反应,故而对对方滋生出爱情的情愫。
心理学是门很实用的学问吧[偷笑][偷笑]。
昨天开会讨论我自己的搜索引擎的事情,我说我这个都计划了好几年了,老大说:“那我不让晓静做,她还不得杀了我~~” 要不是开会,我会很负责任的跟他说:“不会那么惨啦,但是每次见你都朝你吐舌头是免不了的~~”。于是今年我的核心任务就这么定下来了。

我开始的时候提出:将搜索引擎的索引全部设置内存索引,不持久化存储,这样速度会快。因为是一个集群,所以发版可以定时一台一台的重启服务。因为重启后会重建索引,需要大概10分钟。集群直接采用nginx做负载均衡,服务之间不做强数据一致,而是每个服务独立的从数据库中没100ms按照更新时间查找当前1m内的更新数据。更新数据首先存入java的Set,设置两个Set。Set内的数据按ID做为key,一个Set存储当前1s内已经更新到索引中的数据,一条存储没有更新到索引的数据。对于已经更新到索引的数据,当新的数据和已经更新的数据对比,不一致则更新,否则不处理。对于未更新到索引的数据,直接覆盖旧数据。之所以这么做是因为mysql数据库的更新时间都是秒级的,我用毫秒级的间隔,会多次重建索引。
服务之间的一致性按照存储的ID和更新时间定时对比,也可以手动对比来保证。
对于现有的通知服务,因为业务方更新了本来会发消息通知我们更新缓存,更新了缓存再返回更细成功的消息给业务方。我说非要保留这个的话,我拿到通知更新的,我就直接返回,因为我的更新是ms秒级的,肯定比收消息再发消息这个通信过程快。
我提出了现有服务的问题:维护成本高,部署复杂,结构复杂,还有一些499的超时,我的搜索引擎都可以解决。因为我的内存支持全量索引数据和查询结果的缓存,所以接口直接调用,自己基本什么都不需要做。
好了,上面的都可以不看,因为被我们的技术大牛们批的体无完肤。下面是他们给出的考虑和建议:
首先,我最怕的问题,做与不做的问题。
我说咱们的业务其实特别简单,都是查,只要求高可用,高并发,这种场景本身就特别合适搜索引擎。大家反馈说:你这个占内存太大,线上的一般机器内存也就30G。这个样子啊,我土豪惯了,一直认为线上别人也都是用24核128G高配物理机。然后,万一全部宕机,重启过程中有10分钟服务不可用。我本来是想有联通和电信,这种几率很小,所以服务宕机重启过程中直接查数据,缓存结果也能扛得住。好吧,也是我考虑不周,我说那就做可持久化的。内存不够和启动问题全能解决,lucene本来就支持,只是可以根据宕机几率,减少写的频率来提高效率。给业务线回消息,因为我的索引更新有两部分的时间:一部分是读从数据库有从数据库和主数据库的同步时间和索引更新时间两部分组成,不一定比消息要快。我说那就按消息被nginx转发的搜索引擎节点查一次,更新了就回OK的消息。大家反馈说:因为集群之间不是实时通信,所以强一致性也不能保证,所以回的消息不可靠。我说那我大不了采用现有的ES搜索引擎的或者SolrCloud的集群技术来做集群之间的强一致,肯定是能解决的。大家说:那你的优势在哪里啊,干嘛不直接用ES?(好刻薄,好尖锐[恐怖][恐怖],但是做技术的,大家都知道,也都习惯了,争论才有提高,特别是对于咱们程序员)。我说大家也应该都看到了,我擅长函数,擅长算法,在内部我有很多可以优化的地方,然后你们还没好好看我的博客,我都写了的[委屈][委屈]。
到时候会支持两种调用模式,一种是RMI调用,一种是RPC调用。目前的SOA基本都在用通用性更强的RPC调用,如:dubbo,thrift, 还有市面上的搜索引擎。实际上RMI更快,对于我们内部使用,RMI更合适。在Java中,只要一个类extends了java.rmi.Remote接口,即可成为存在于服务器端的远程对象,供客户端访问并提供一定的服务。不过无论RMI还是RPC,都是下面这种简单的架构:
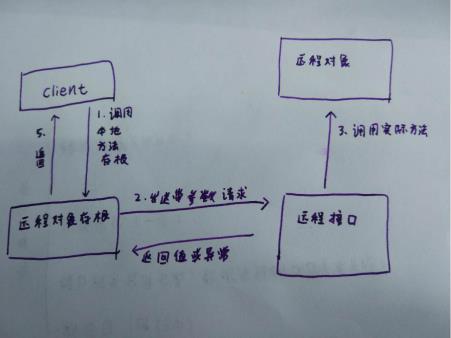
阳哥说回到最初的问题,因为业务简单,那完全可以用Lua来写啊。被批了十几分钟,我的大小姐脾气突然就来了"那你们谁会Lua,让他写一个"。还是阳哥机灵,话锋突然一转,让我立刻感觉到不是不让做的意思。然后阳哥就说人家也确实就是会Lua。我说确实是什么都可以实现,但是阳哥您擅长Lua那您就会采用Lua的方式来解决,我擅长搜索引擎,那我就会采用搜索引擎来解决。阳哥就说自己在阿里的时候人家直接用数据库就双十一就扛住了高并发。好了,空气的紧张氛围缓和下来了。
我说话也确实说不清楚,脾气还容易急。最后还是男神老大出马[撒花][撒花]。老大说:“首先这个定位问题,我们是要做一个通用的搜索引擎的中间件,不是特定为接口服务而写的,但是做好了接口服务可以用。其他的服务也可以接,目前的ES搜索引擎也可以被代替。”不对,不对,记得男神哥哥当时说的可好听了,但是只顾着仰望了,具体啥全忘了。然后我要争取其他人的支持:"阳哥您看您有您自己的平台,磊哥您有自己的日志收集系统,你们都说自己有什么优势,但是我们也没听很明白,但是你们自己知道。我要做自己的中间件也是一样。" 其实我都没有必要这么担心不让做的问题,因为我们部门是一个很开明,很能容纳新思想,很愿意接受改变的部门,谁有什么想法,都按自己的想法去做了。最坏的结果也就是失败了,没啥大不了的。但是我的语言功力确实欠练。我家男票是个很沉默是金的人,他妈都觉得他太闷了。因为他说话少,在爷爷奶奶那边,他也比别的孙子孙女更吃亏。但是跟我他是无话不谈的,我都睡着了,他还说个没完~~因为我有绝招啊,首先一个不是很熟的人,聊天的话先聊什么呢,小时候啊。他也可能没看过我看过的书,我看过的电影,没有我有的东西……但是他一定有小时候,一般人提到小时候话匣子一下子就打开了。然后听到关于他自己的越多,聊得也就越多了。但是,要说聊正事,差的真远。
接下来就是怎么做的问题。
阳哥说你这个集群最好用分片的索引数据,这样才能发挥集群的优势。我说这真是个好主意,也是很好实现的,采用集中式缓存的算法即可。现在ES就是采用的memcached协议的,原理和moxi一样。通过memecached协议来访问ES的接口,支持二进制和文本两种协议.通过一个名为transport-memcached插件提供。磊哥和德伟说我应该去研究一下ES和Solr,吸取其精华,好中肯。德伟还提到我用的直接按100ms去数据库拉取数据,可以用订阅更新来做(https://github.com/alibaba/canal)还给我推荐了这个实现。因为搜索引擎本来就是一个文档型的nosql数据库,那么将来可以不但支持多种外接数据库等数据录入方式,还可以提供默认自己就是数据库,去掉数据库环节的服务。大家还提议做成插件形式的。
大家提出这个能够带来的一个很大的好处就是目前我们做的分库分表,采用搜索引擎的话,接口服务就不会受到影响。老大还提出:这个比较合适列表,和查询条件复杂的搜索,但是对于单个ID的搜索是不是还是走数据库更合适。这个需要等服务做出来之后测试来定。我个人倾向于都走搜索,因为保持一致,维护容易。我看过solrcloud的集群策略,集群之间的复制确实要比每个服务直接和数据库打交道出错率要高,所以我可以试着结合数据库直接数据交互,分片,加上高效的容错来做数据的一致性保证。会上忘了说搜索引擎的目前的搜索模型不合适媒资这样大多根据ID来查询的问题,到时候需要好好考虑。
对于这个搜索中间件,大家都提了很多。我就说开发就一个人就好,你们就负责提意见。大家说:都规划好了,编码是很简单的,将来你也可以招一些人帮你编码。太nice了,怕我累着~~对了,最后是项目的名字问题。我自己的域名是brmayi。br是换行符,那么我的域名就解释为<换行蚂蚁>吧,发现和蚂蚁沾点边很容易火[偷笑][偷笑]。我喜欢花,所以自己做的东西都以花的名字来命名。周末植物园满园的郁金香特别好看,这个项目就叫<郁金香>了,英文是tulip,随手画的,等五一放假好好设计下logo[偷笑][偷笑]

如需转载,请注上我的原文链接:http://www.cnblogs.com/xiexj/p/6782350.html 谢谢哦~~
以上是关于郁金香搜索引擎的方案的主要内容,如果未能解决你的问题,请参考以下文章