DataFrame中的write与read编程
Posted 曹军
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了DataFrame中的write与read编程相关的知识,希望对你有一定的参考价值。
一:SparkSQL支持的外部数据源
1.支持情况

2.External LIbraries
不是内嵌的,看起来不支持。
但是现在已经有很多开源插件,可以进行支持。
3.参考材料
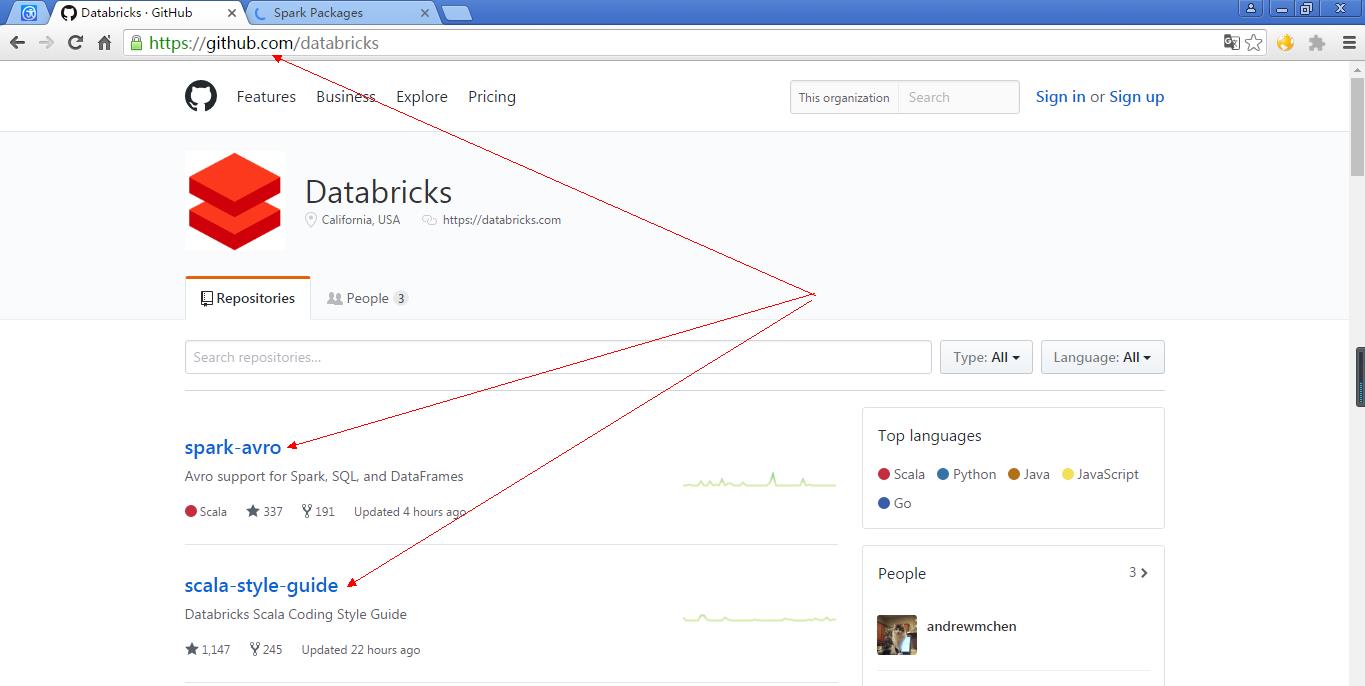
· 支持的格式:https://github.com/databricks
二:准备
1.启动服务
RunJar是metastore服务,在hive那边开启。
只需要启动三个服务就可以了,以后runjar都要启动,因为这里使用hive与spark集成了,不启动这个服务,就会总是报错。
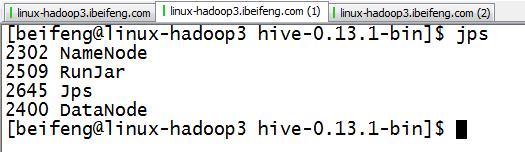
2.启动spark-shell

三:测试检验程序
1.DataFrame的构成
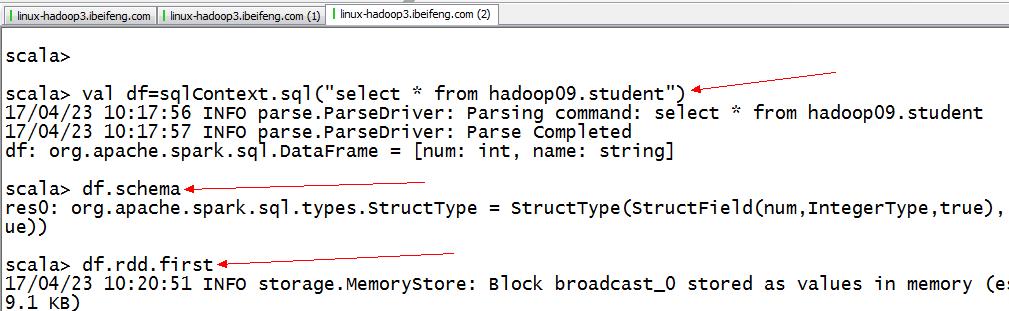
2.结果

3.测试
4.结果
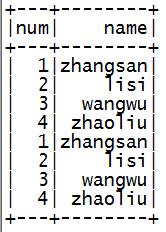
四:DataFrame的创建
1.创建SQLContext
val sqlContext=new SQLContext(sc)
2.创建DataFrame(两种方式)
val df=sqlContext.#
val df=sqlContext.read.#
3.DataFrame数据转换
val ndf=df.#.#
4.结果保存
ndf.#
ndf.write.#
五:DataFrame的保存
1.第一种方式
将DataFrame转换为RDD,RDD数据保存
2.第二种方式
直接通过DataFrame的write属性将数据写出。
但是有限制,必须有定义类实现,默认情况:SparkSQL只支持parquet,json,jdbc
六:两个常用的网站(数据源问题)
1.金砖公司提供的一些插件
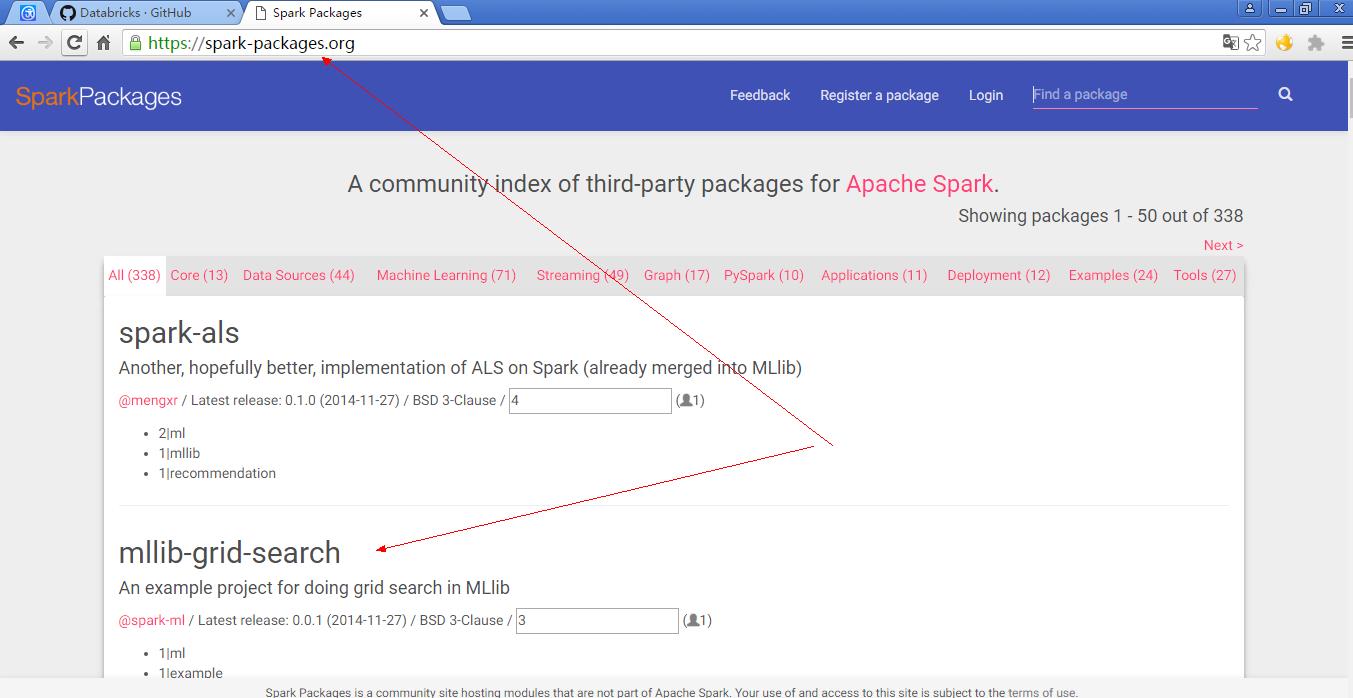
2.package网址
https://spark-packages.org/
七:DataFrameReader编程模式
功能: 通过SQLContext提供的reader读取器读取外部数据源的数据,并形成DataFrame
1.源码的主要方法
format:给定数据源数据格式类型,eg: json、parquet
schema:给定读入数据的数据schema,可以不给定,不给定的情况下,进行数据类型推断
option:添加参数,这些参数在数据解析的时候可能会用到
load:
有参数的指从参数给定的path路径中加载数据,比如:JSON、Parquet...
无参数的指直接加载数据(根据option相关的参数)
jdbc:读取关系型数据库的数据
json:读取json格式数据
parquet:读取parquet格式数据
orc: 读取orc格式数据
table:直接读取关联的Hive数据库中的对应表数据
八:Reader的程序测试
1.新建文件夹
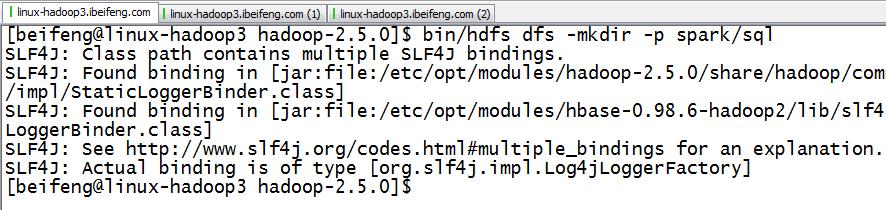
2.上传数据

3.加载json数据
val df=sqlContext.read.format("json").load("spark/sql/people.json")
结果:

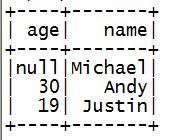
4.数据展示
df.show()
结果:

5.数据注册成临时表并操作展示

结果:
6.和上面的方法等效的方式
sqlContext.sql("select * from json.`spark/sql/people.json`").show()
结果:

7.读取显示parquet格式的数据
sqlContext.read.format("parquet").load("spark/sql/users.parquet").show()
结果:

8.加载mysql中的数据
这个是服务器上的mysql。
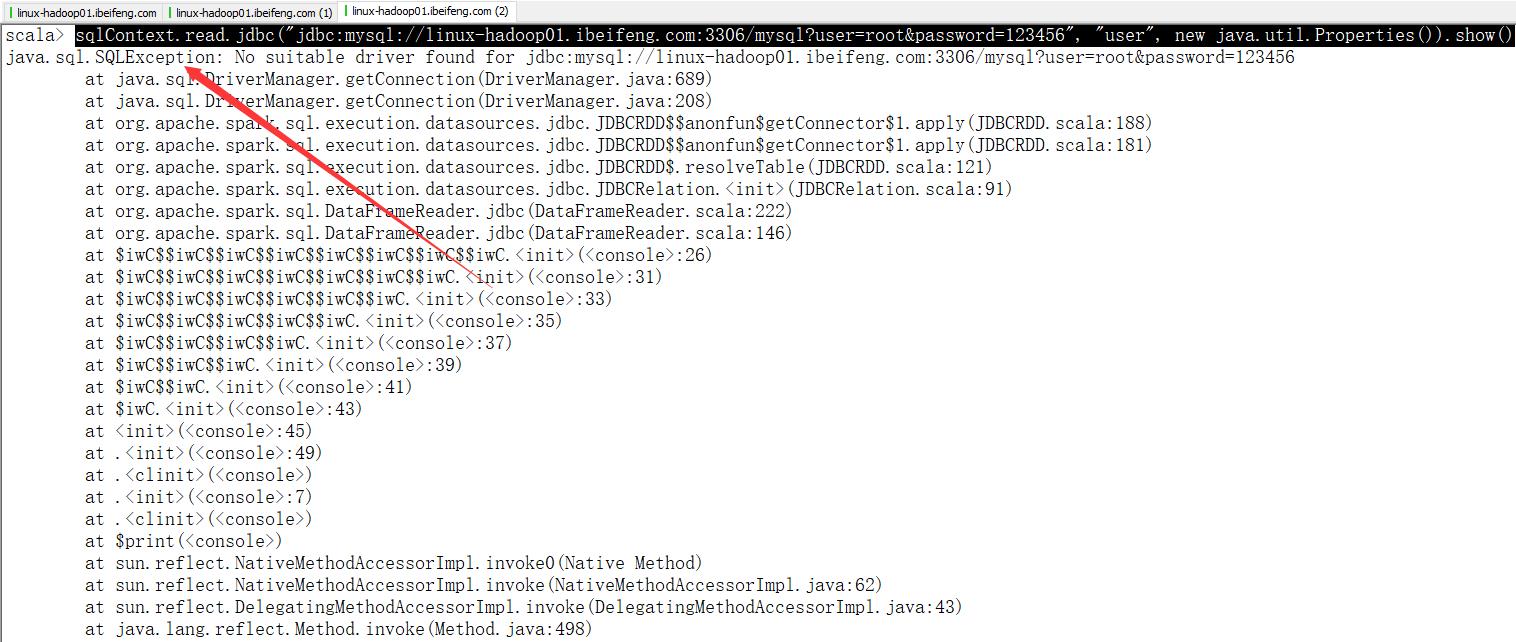
sqlContext.read.jdbc("jdbc:mysql://linux-hadoop01.ibeifeng.com:3306/mysql?user=root&password=123456", "user", new java.util.Properties()).show()
这个地方比较特殊。
第一次使用bin/spark-shell进入后,使用命令,效果如下:
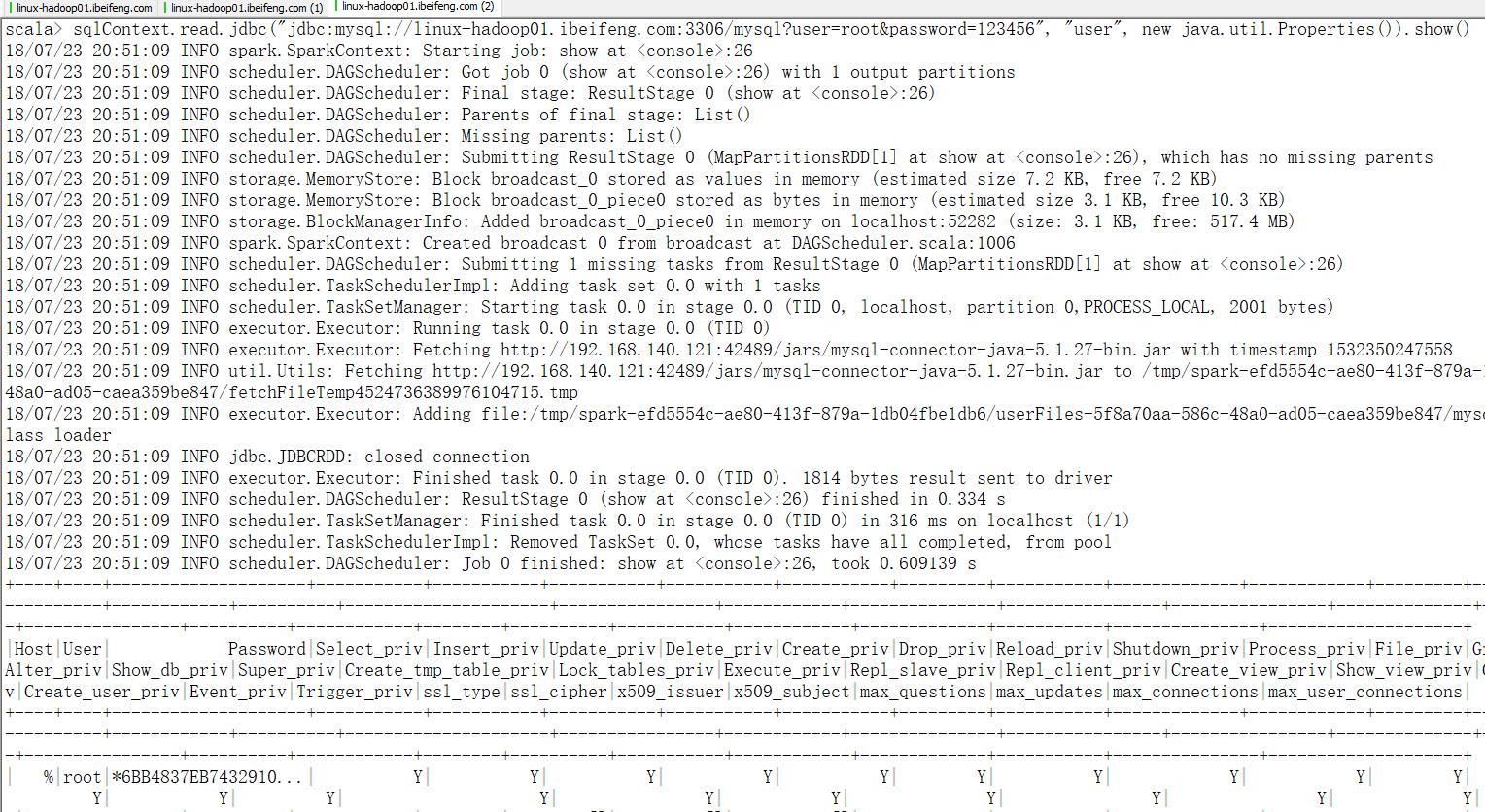
然后使用这种方式进行启动,加上jar
bin/spark-shell --jars /opt/softwares/mysql-connector-java-5.1.27-bin.jar --driver-class-path /opt/softwares/mysql-connector-java-5.1.27-bin.jar
九:DataFrameWriter编程模式
功能:将DataFrame的数据写出到外部数据源
1.源码主要方法
mode: 给定数据输出的模式
`overwrite`: overwrite the existing data.
`append`: append the data.
`ignore`: ignore the operation (i.e. no-op).
`error`: default option, throw an exception at runtime.
format:给定输出文件所属类型, eg: parquet、json
option: 给定参数
partitionBy:给定分区字段(要求输出的文件类型支持数据分区)
save: 触发数据保存操作 --> 当该API被调用后,数据已经写出到具体的数据保存位置了
jdbc:将数据输出到关系型数据库
当mode为append的时候,数据追加方式是:
先将表中的所有索引删除
再追加数据
没法实现,数据不存在就添加,存在就更新的需求
十:writer的程序测试
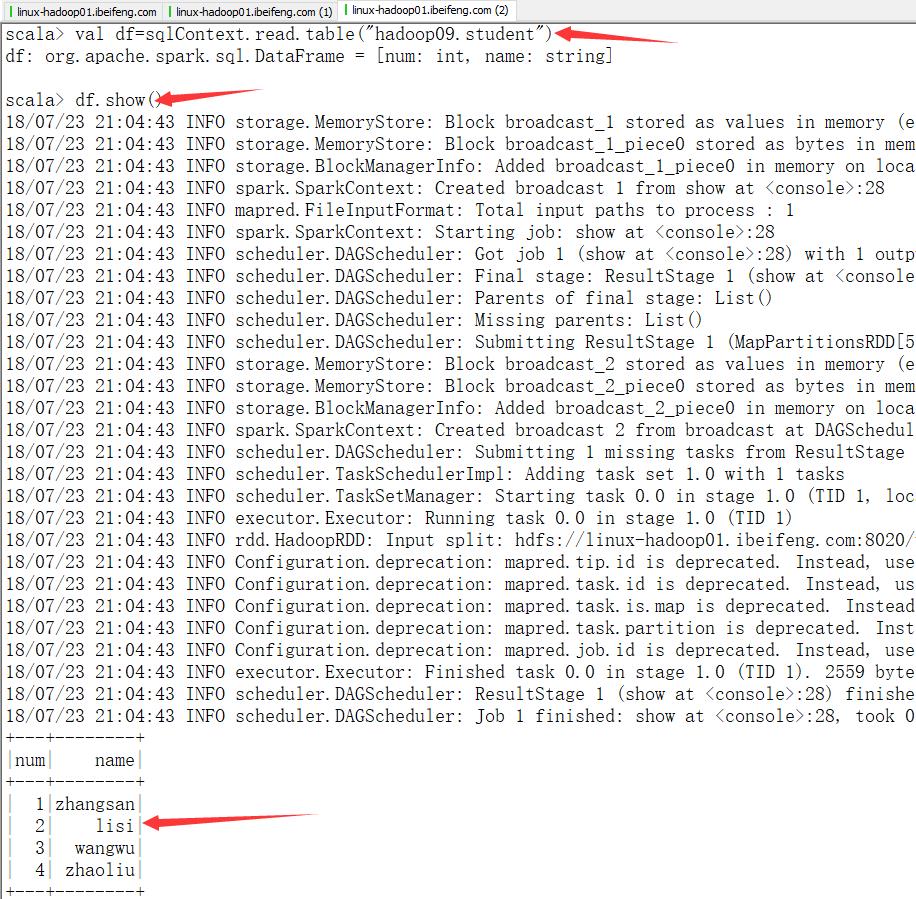
1.读取hive数据,形成DateFrame
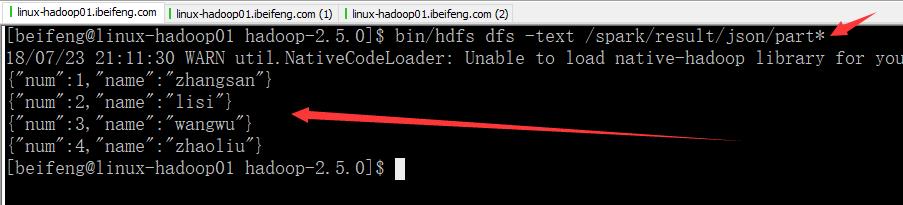
2.结果保存为json格式
自动创建存储目录。

效果:
3.不再详细粘贴结果了
1 读取Hive表数据形成DataFrame 2 val df = sqlContext.read.table("common.emp") 3 4 结果保存json格式 5 df.select("empno","ename").write.mode("ignore").format("json").save("/beifeng/result/json") 6 df.select("empno","ename").write.mode("error").format("json").save("/beifeng/result/json") 7 df.select("empno","ename", "sal").write.mode("overwrite").format("json").save("/beifeng/result/json") 8 df.select("empno","ename").write.mode("append").format("json").save("/beifeng/result/json")\\ 9 上面虽然在追加的时候加上了sal,但是解析没有问题 10 sqlContext.read.format("json").load("/beifeng/result/json").show() 11 12 结果保存parquet格式 13 df.select("empno", "ename", "deptno").write.format("parquet").save("/beifeng/result/parquet01") 14 df.select("empno", "ename","sal", "deptno").write.mode("append").format("parquet").save("/beifeng/result/parquet01") ## 加上sal导致解析失败,读取数据的时候 15 16 sqlContext.read.format("parquet").load("/beifeng/result/parquet01").show(100) 17 sqlContext.read.format("parquet").load("/beifeng/result/parquet01/part*").show(100) 18 19 partitionBy按照给定的字段进行分区 20 df.select("empno", "ename", "deptno").write.format("parquet").partitionBy("deptno").save("/beifeng/result/parquet02") 21 sqlContext.read.format("parquet").load("/beifeng/result/parquet02").show(100)
以上是关于DataFrame中的write与read编程的主要内容,如果未能解决你的问题,请参考以下文章