re 正则模块
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了re 正则模块相关的知识,希望对你有一定的参考价值。
re模块(* * * * *)
就其本质而言,正则表达式(或 RE)是一种小型的、高度专业化的编程语言,(在Python中)它内嵌在Python中,并通过 re 模块实现。正则表达式模式被编译成一系列的字节码,然后由用 C 编写的匹配引擎执行。
字符匹配(普通字符,元字符):
1 普通字符:大多数字符和字母都会和自身匹配
>>> re.findall(\'alvin\',\'yuanaleSxalexwupeiqi\')
[\'alvin\']
2 元字符:. ^ $ * + ? { } [ ] | ( ) \\
元字符之. ^ $ * + ? { }
import re ret=re.findall(\'a..in\',\'helloalvin\') print(ret)#[\'alvin\'] ret=re.findall(\'^a...n\',\'alvinhelloawwwn\') print(ret)#[\'alvin\'] ret=re.findall(\'a...n$\',\'alvinhelloawwwn\') print(ret)#[\'awwwn\'] ret=re.findall(\'a...n$\',\'alvinhelloawwwn\') print(ret)#[\'awwwn\'] ret=re.findall(\'abc*\',\'abcccc\')#贪婪匹配[0,+oo] print(ret)#[\'abcccc\'] ret=re.findall(\'abc+\',\'abccc\')#[1,+oo] print(ret)#[\'abccc\'] ret=re.findall(\'abc?\',\'abccc\')#[0,1] print(ret)#[\'abc\'] ret=re.findall(\'abc{1,4}\',\'abccc\') print(ret)#[\'abccc\'] 贪婪匹配
注意:前面的*,+,?等都是贪婪匹配,也就是尽可能匹配,后面加?号使其变成惰性匹配
ret=re.findall(\'abc*?\',\'abcccccc\') print(ret)#[\'ab\']
元字符之字符集[]:
#--------------------------------------------字符集[] ret=re.findall(\'a[bc]d\',\'acd\') print(ret)#[\'acd\'] ret=re.findall(\'[a-z]\',\'acd\') print(ret)#[\'a\', \'c\', \'d\'] ret=re.findall(\'[.*+]\',\'a.cd+\') print(ret)#[\'.\', \'+\'] #在字符集里有功能的符号: - ^ \\ ret=re.findall(\'[1-9]\',\'45dha3\') print(ret)#[\'4\', \'5\', \'3\'] ret=re.findall(\'[^ab]\',\'45bdha3\') print(ret)#[\'4\', \'5\', \'d\', \'h\', \'3\'] ret=re.findall(\'[\\d]\',\'45bdha3\') print(ret)#[\'4\', \'5\', \'3\']
元字符之转义符\\
反斜杠后边跟元字符去除特殊功能,比如\\.
反斜杠后边跟普通字符实现特殊功能,比如\\d
\\d 匹配任何十进制数;它相当于类 [0-9]。
\\D 匹配任何非数字字符;它相当于类 [^0-9]。
\\s 匹配任何空白字符;它相当于类 [ \\t\\n\\r\\f\\v]。
\\S 匹配任何非空白字符;它相当于类 [^ \\t\\n\\r\\f\\v]。
\\w 匹配任何字母数字字符;它相当于类 [a-zA-Z0-9_]。
\\W 匹配任何非字母数字字符;它相当于类 [^a-zA-Z0-9_]
\\b 匹配一个特殊字符边界,比如空格 ,&,#等
ret=re.findall(\'I\\b\',\'I am LIST\') print(ret)#[] ret=re.findall(r\'I\\b\',\'I am LIST\') print(ret)#[\'I\']
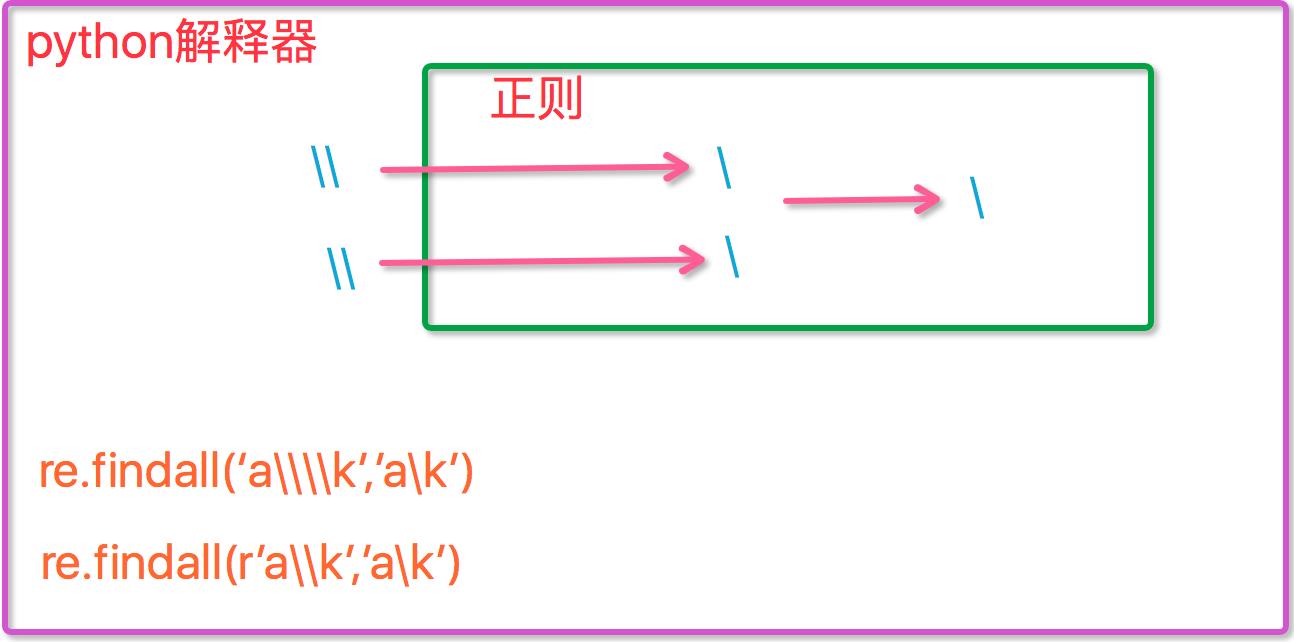
现在我们聊一聊\\,先看下面两个匹配:
#-----------------------------eg1: import re ret=re.findall(\'c\\l\',\'abc\\le\') print(ret)#[] ret=re.findall(\'c\\\\l\',\'abc\\le\') print(ret)#[] ret=re.findall(\'c\\\\\\\\l\',\'abc\\le\') print(ret)#[\'c\\\\l\'] ret=re.findall(r\'c\\\\l\',\'abc\\le\') print(ret)#[\'c\\\\l\'] #-----------------------------eg2: #之所以选择\\b是因为\\b在ASCII表中是有意义的 m = re.findall(\'\\bblow\', \'blow\') print(m) m = re.findall(r\'\\bblow\', \'blow\') print(m)
元字符之分组()
m = re.findall(r\'(ad)+\', \'add\') print(m) ret=re.search(\'(?P<id>\\d{2})/(?P<name>\\w{3})\',\'23/com\') print(ret.group())#23/com print(ret.group(\'id\'))#23
元字符之|
ret=re.search(\'(ab)|\\d\',\'rabhdg8sd\') print(ret.group())#ab
re模块下的常用方法
import re #1 re.findall(\'a\',\'alvin yuan\') #返回所有满足匹配条件的结果,放在列表里 #2 re.search(\'a\',\'alvin yuan\').group() #函数会在字符串内查找模式匹配,只到找到第一个匹配然后返回一个包含匹配信息的对象,该对象可以 # 通过调用group()方法得到匹配的字符串,如果字符串没有匹配,则返回None。 #3 re.match(\'a\',\'abc\').group() #同search,不过尽在字符串开始处进行匹配 #4 ret=re.split(\'[ab]\',\'abcd\') #先按\'a\'分割得到\'\'和\'bcd\',在对\'\'和\'bcd\'分别按\'b\'分割 print(ret)#[\'\', \'\', \'cd\'] #5 ret=re.sub(\'\\d\',\'abc\',\'alvin5yuan6\',1) print(ret)#alvinabcyuan6 ret=re.subn(\'\\d\',\'abc\',\'alvin5yuan6\') print(ret)#(\'alvinabcyuanabc\', 2) #6 obj=re.compile(\'\\d{3}\') ret=obj.search(\'abc123eeee\') print(ret.group())#123
import re ret=re.finditer(\'\\d\',\'ds3sy4784a\') print(ret) #<callable_iterator object at 0x10195f940> print(next(ret).group()) print(next(ret).group())
注意:
import re ret=re.findall(\'www.(baidu|oldboy).com\',\'www.oldboy.com\') print(ret)#[\'oldboy\'] 这是因为findall会优先把匹配结果组里内容返回,如果想要匹配结果,取消权限即可 ret=re.findall(\'www.(?:baidu|oldboy).com\',\'www.oldboy.com\') print(ret)#[\'www.oldboy.com\']
1 补充 2 import re 3 4 print(re.findall("<(?P<tag_name>\\w+)>\\w+</(?P=tag_name)>","<h1>hello</h1>")) 5 print(re.search("<(?P<tag_name>\\w+)>\\w+</(?P=tag_name)>","<h1>hello</h1>")) 6 print(re.search(r"<(\\w+)>\\w+</\\1>","<h1>hello</h1>"))
补充 #匹配出所有的整数 import re #ret=re.findall(r"\\d+{0}]","1-2*(60+(-40.35/5)-(-4*3))") ret=re.findall(r"-?\\d+\\.\\d*|(-?\\d+)","1-2*(60+(-40.35/5)-(-4*3))") ret.remove("") print(ret)
以上是关于re 正则模块的主要内容,如果未能解决你的问题,请参考以下文章