记一次队列积压问题的分析解决
Posted sealake
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了记一次队列积压问题的分析解决相关的知识,希望对你有一定的参考价值。
现象:
同事负责的项目转到我部门,整理服务过程中发现了队列的积压问题。
为了搞清楚积压的严重程度, 对队列任务数每分钟进行一次采样,生成一个走势图, 队列积压情况一目了然,非常严重。
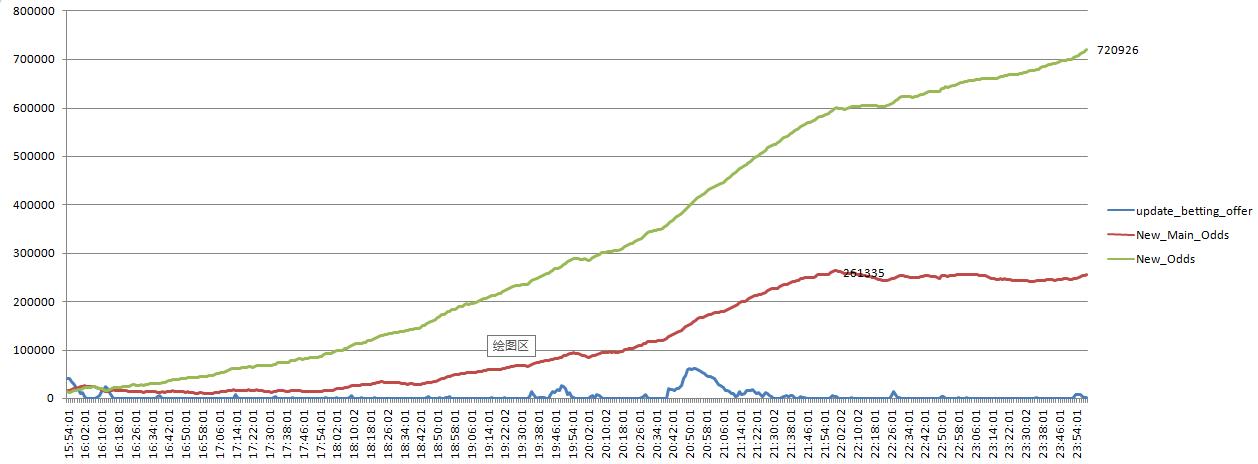
分析:
听了同事对系统的介绍,猜测是mongo性能影响了处理效率,于是针对mongo进行分析
1. 使用mongotop /usr/local/mongodb/bin/mongotop --host 127.0.0.1:10000
odds_easy.basic_odds表的操作一直排第一,写操作占大部分时间

2. 看mongo shard日志
大量超过1s的操作,集中在odds_easy.basic_odds写操作, 看日志lock数量很多

查询某一个文档的更新,在同一秒中居然有15个更新操作,这样的操作产生什么样的结果: 大量的写锁,并且影响读;而且还是最影响性能的数组的$push, $set操作

看看文档的结构,数组的数量之大,而且里面还是对象嵌套; 对这样一个文档不停的更新, 性能可想而知

看看 db.serverStats()的lock情况

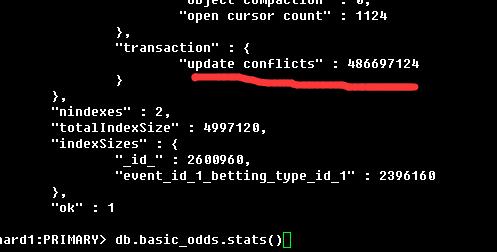
看看odds_easy的db.basic_odds.stats()情况,大量的更新冲突
3. 看看sharding情况
使用脚本,查看sharding情况,重定向到文件中查看。
sql=\'db.printShardingStatus({verbose:true})\'
echo $sql|/usr/local/mongodb/bin/mongo --host 192.168.1.48:30000 admin --shell
basic_odds的sharding信息:
shard key: { "event_id" : 1, "betting_type_id" : 1 } event_id为mysql自增字段,betting_type_id为玩法id(意味着几个固定的值,区别度不大)
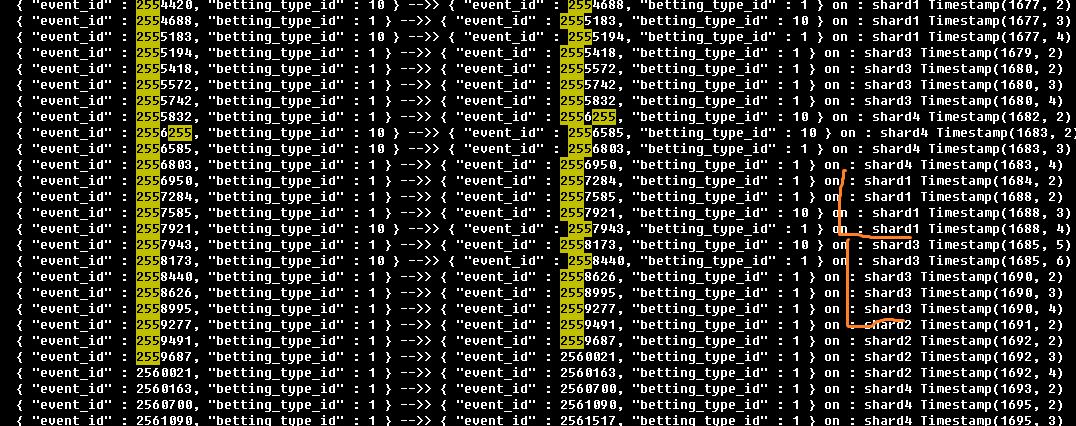
shard 分布情况, 从图里面可以看到mongo主要根据event_id这个自增字段的范围进行数据拆分, 意味着相邻比赛的数据大概率会被分配到同一个shard分区上(这就是为什么01机器上的日志大小远大于其他机器的原因吧,目前的数据都集中在shard1上)
下图为数据库读写情况, 更新操作是查询操作的4倍。 对一个写多读少的数据库, 本该将写操作分布到不同的分区上,结果由于sharding key的错误选择造成了写热点,将写集中到了同一个分区,进一步加剧了写的阻塞

结论
- 文档结构不合理,数组过大、更新过于频繁,特别是对同一文档。 对数组频繁的更新操作是mongo最不推荐的,不仅影响本机的性能,还影响oplog的数据同步
- sharding key不合理造成了写热点, 在第一点不合理的基础上,更加剧了性能的急剧下降, 还会造成频繁的mongo数据迁移
(由于odds_easy.basic_odds的更新量大,目前问题在这个表上,但是其他表也有同样的问题)
【可以看到前期合理的架构设计是多么的重要】
解决思路
- 减少同一时刻对同一文档的更新操作,将一定时间内的多次更新改为一次更新。
- 将更新最频繁的process字段从文档中移出,写到新的表中。 在新表中,同一event_id,betting_type_id, 赔率公司的变化在同一条记录中
- 文档结构中加入时间字段,方便数据迁移,定期将历史数据进行迁移,进行冷热数据分离
- 修改sharding key为hash或者其他字段,将写操作分布到不同的分区上
解决方案
分两个阶段:
第一阶段 结构优化
- odds_easy库中basic_odds, main_odds不再存储最近10条的变化,去掉process字段。
- 数据直接 mongo push到odds_change中对应的记录rows字段中
- 单独提供接口,数据变化从odds_change中读取, 使用 mongo的$slice读出最近n条信息,然后程序排序截取即可
- odds_easy库和odds_change库中的表都使用 event_id 作 hash sharding key
- odds_easy, odds_change, odds_bet007, odds_betbrain_bb, odds_betbrain_v5, odds_txodds这些库中的记录都加入match_time字段。 新增的记录直接加入;历史的记录补全
- 加入分布式锁,解决并发问题,提高系统横向扩张能力
第二阶段 冷热分离
目的
- 解决积压问题
- 提高访问速度
- 防止用户对大量历史的访问从而影响热数据的访问。(可以在配置中加入开关, 出现问题时关闭历史数据的访问)
系统中加入redis做热数据缓存, zookeeper/etcd作为配置服务中心以及热数据导入的流程控制中心
架构图

2. 相关流程
update_betting_offer队列的GermanWorker启动新增流程
- 从服务配置中心读取热点比赛列表
- 需要在服务配置中心注册节点,节点内容:“本机ip进程号_update_setting” (去掉ip中的点号)
-
在german注册一个任务名称,名字为第一步中的节点内容
"本机IP进程号_update_setting"任务处理流程:
- 在服务配置中心注册新节点
- watch 服务配置中心的 “导入数据OK节点”
- 收到watch变化后,更新程序的热点event_id列表
- 删除在服务配置中心注册的节点
定时任务流程:
- 找出最近2天内未结束比赛的event_id列表
- watch服务配置中心 “导入数据OK节点”,内容为0
- 从服务配置中心获取所有update_betting_offer的GermanWorker节点,并根据节点内容的发送任务(任务名称=节点内容,任务内容=event_id列表)
- 等待watch的节点数==german worker数后, 从服务配置中心读取现在的event_id列表,与新的列表进行对比。将新增的event_id数据从mongo导入redis,过期时间3天
- 导入完毕后, 改变 “导入数据OK节点”,内容为1
3. redis结构
初赔结构, key值: “event_id:betting_id:start” , value值为hash类型,hash_key:provider_id;hash_value:跟mongo中的结构一致,json格式;如{"i":{"t0":{"h":4.27,"d":3.24,"a":1.88},"t1":0.9305,"t2":{"h":0.2179,"d":0.2872,"a":0.4949},"t3":{"h":0.93,"d":0.93,"a":0.93}},"s":1,"t":"2017-04-03 13:39:28","b":0,\'p\':744 }
终赔结构,key值:"event_id:betting_id:end" value值同初赔
平均结构,key值:"event_id:betting_id:avg" value值同初赔
变化过程,key值:"event_id:betting_id:provider_id:boundary", value值为sorted set, member为赔率信息,跟mongo中的结构一致,json格式;如{"i":{"t0":{"h":4.27,"d":3.24,"a":1.88},"t1":0.9305,"t2":{"h":0.2179,"d":0.2872,"a":0.4949},"t3":{"h":0.93,"d":0.93,"a":0.93}},"s":1,"t":"2017-04-03 13:39:28","b":0,\'p\':744 }。 score为时间,如20170403133928
如果按照上面的结构进行存储, 进行了大概的预估。
对2789场比赛进行了欧赔统计,平均一场比赛2006个初赔,2006个终赔;583个boudary值,每个boundary结构中存23个赔率变化;这样计算一场比赛需要大概 5.5m, 盘口数据大概为欧赔的一半。总8M
如果放入所有未开赛的比赛,大概1个半月的比赛,1w场比赛,所需内存80G,这个量太大了。
所以只放入热数据,2天内未开赛的比赛,保存3天,3天比赛450场左右。 需要 3.6G
----------------后续:第一阶段优化完后高峰期最高120左右
以上是关于记一次队列积压问题的分析解决的主要内容,如果未能解决你的问题,请参考以下文章