第7章 Scrapy突破反爬虫的限制
Posted 今孝
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第7章 Scrapy突破反爬虫的限制相关的知识,希望对你有一定的参考价值。
7-1 爬虫和反爬的对抗过程以及策略
Ⅰ、爬虫和反爬虫基本概念
- 爬虫:自动获取网站数据的程序,关键是批量的获取。
- 反爬虫:使用技术手段防止爬虫程序的方法。
- 误伤:反爬虫技术将普通用户识别为爬虫,如果误伤过高,效果再高也不能用。
- 成本:反爬虫需要的人力和机器成本。
- 拦截:成功拦截爬虫,一般拦截率越高,误伤率越高。
Ⅱ、反爬虫的目的
- 初级爬虫----简单粗暴,不管服务器压力,容易弄挂网站。
- 数据保护
- 失控的爬虫----由于某些情况下,忘记或者无法关闭的爬虫。
- 商业竞争对手
Ⅲ、爬虫和反爬虫对抗过程

7-2 scrapy架构源码分析
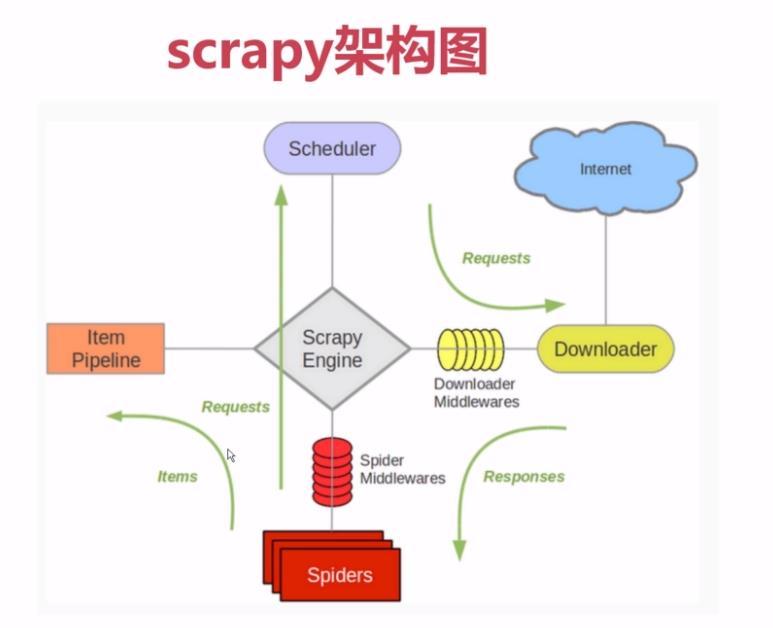
原理图:
我最早接触scrapy的时候就是看这张原理图,如下图
现在有新的原理图,更加直观,如下图
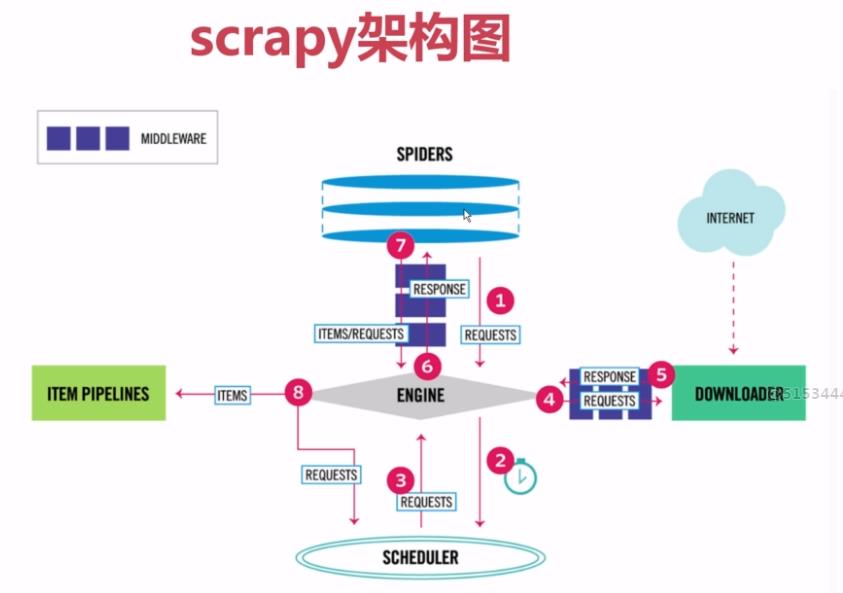
看了视频讲的源码解析,看一遍根本看不懂,后期还要多看叫上项目的练习才行。
7-3 Requests和Response介绍
可以看scrapy文档: http://scrapy-chs.readthedocs.io/zh_CN/latest/index.html 查看相关的说明即可。
模拟登陆后,Request会自动传递cookies,不用我们添加。
7-4~5 通过downloadmiddleware随机更换user-agent
这是个模版以后直接拿来用即可
1 #middlewares.py文件 2 from fake_useragent import UserAgent #这是一个随机UserAgent的包,里面有很多UserAgent 3 class RandomUserAgentMiddleware(object): 4 def __init__(self, crawler): 5 super(RandomUserAgentMiddleware, self).__init__() 6 7 self.ua = UserAgent() 8 self.ua_type = crawler.settings.get(\'RANDOM_UA_TYPE\', \'random\') #从setting文件中读取RANDOM_UA_TYPE值 9 10 @classmethod 11 def from_crawler(cls, crawler): 12 return cls(crawler) 13 14 def process_request(self, request, spider): 15 def get_ua(): 16 \'\'\'Gets random UA based on the type setting (random, firefox…)\'\'\' 17 return getattr(self.ua, self.ua_type) 18 19 user_agent_random=get_ua() 20 request.headers.setdefault(\'User-Agent\', user_agent_random) #这样就是实现了User-Agent的随即变换
1 #settings.py文件 2 DOWNLOADER_MIDDLEWARES = { 3 \'Lagou.middlewares.RandomUserAgentMiddleware\': 543, 4 \'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware\':None, #这里要设置原来的scrapy的useragent为None,否者会被覆盖掉 5 } 6 RANDOM_UA_TYPE=\'random\'
7-6~8 scrapy实现ip代理池
这是个模版以后直接拿来用即可
1 #middlewares.py文件 2 class RandomProxyMiddleware(object): 3 \'\'\'动态设置ip代理\'\'\' 4 def process_request(self,request,spider): 5 get_ip = GetIP() #这里的函数是传值ip的 6 request.meta["proxy"] = get_ip 7 #例如 8 #get_ip = GetIP() #这里的函数是传值ip的 9 #request.meta["proxy"] = \'http://110.73.54.0:8123\' 10 11 12 #settings.py文件 13 DOWNLOADER_MIDDLEWARES = { 14 \'Lagou.middlewares.RandomProxyMiddleware\':542, 15 \'Lagou.middlewares.RandomUserAgentMiddleware\': 543, 16 \'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware\':None, #这里要设置原来的scrapy的useragent为None,否者会被覆盖掉 17 }
1.sql语言取出随机记录:在此是随机取出一条记录是ip和端口组成代理IP
1 select ip,port from proxy_ip 2 order by rand() 3 limit 1
2.使用xpath选择器:
可以使用scrapy中的selector,代码如下:
1 from scrapy.selector import Selector 2 html=requests.get(url) 3 Selector=Selector(text=html.text) 4 Selector.xpath()
3.if __name__ == "__main__"问题
如果没有这个,调用时会默认运行以下命令
1 if __name__ == "__main__": 2 get_ip=GetIp() 3 get_ip.get_random_ip()
7-9 云打码实现验证码识别
验证码识别方法
- 编码实现(tesseract-ocr)
- 在线打码----打码平台(云打码、若快)
- 人工打码
7-10 cookie禁用、自动限速、自定义spider的settings
如果用不到cookies的,就不要让对方知道你的cookies--设置---COOKIES_ENABLED = False
自定义setting中的参数可以这样写:
1 #在spider.py文件中 2 custom_settings={ 3 "COOKIES_ENABLED":True, 4 "":"", 5 "":"", 6 }
作者:今孝
出处:http://www.cnblogs.com/jinxiao-pu/p/6762636.html
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接。
以上是关于第7章 Scrapy突破反爬虫的限制的主要内容,如果未能解决你的问题,请参考以下文章