前端学HTTP之报文首部
Posted 唐世光
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了前端学HTTP之报文首部相关的知识,希望对你有一定的参考价值。
前面的话
首部和方法配合工作,共同决定了客户端和服务器能做什么事情。在请求和响应报文中都可以用首部来提供信息,有些首部是某种报文专用的,有些首部则更通用一些。本文将详细介绍HTTP报文中的首部
结构
HTTP首部字段是构成HTTP报文的要素之一。在客户端与服务器之间以HTTP协议进行通信的过程中,无论是请求还是响应都会使用首部字段,它能起到传递额外重要信息的作用。使用首部字段是为了给浏览器和服务器提供报文主体大小、所使用的语言、认证信息等内容
HTTP首部字段是由首部字段名和字段值构成的,中间用冒号“:” 分隔
首部字段名: 字段值
例如,在HTTP首部中以Content-Type这个字段来表示报文主体的对象类型
Content-Type: text/html
就以上述示例来看,首部字段名为Content-Type,字符串text/html是字段值
另外,字段值对应单个 HTTP 首部字段可以有多个值,如下所示
Keep-Alive: timeout=15, max=100
分类
可以将首部分为五个主要的类型,包括通用首部、请求首部、响应首部、实体首部和扩展首部
【通用首部】
通用首部可以在客户端、服务器和其他应用程序之间提供一些非常有用的通用功能。比如,Date首部就是一个通用首部,每一端都可以用它来说明构建报文的时间和日期:
Date: Tue, 3 Oct 2016 02:16:00 GMT
【请求首部】
请求首部是请求报文特有的。它们为服务器提供了一些额外信息,比如客户端希望接收什么类型的数据。例如,下面的Accept首部就用来告知服务器客户端会接受与其请求相符的任意媒体类型:
Accept: */*
【响应首部】
响应报文有自己的首部集,以便为客户端提供信息(比如,客户端在与哪种类型的服务器进行交互)。例如,下列Server首部就用来告知客户端它在与一个版本1.0的Tiki-Hut服务器进行交互:
Server: Tiki-Hut/1.0
【实体首部】
实体首部指的是用于应对实体主体部分的首部。比如,可以用实体首部来说明实体主体部分的数据类型。例如,可以通过下列Content-Type首部告知应用程序,数据是以iso-latin-1字符集表示的HTML文档:
Content-Type:text/html; charset=iso-latin-1
【扩展首部】
扩展首部是非标准的首部,由应用程序开发者创建,但还未添加到已批准的HTTP规范中去。即使不知道这些扩展首部的含义,HTTP程序也要接受它们并对其进行转发
通用首部
有些首部提供了与报文相关的最基本的信息,它们被称为通用首部。它们像和事佬儿一样,不论报文是何类型,都为其提供一些有用信息
例如,不管是构建请求报文还是响应报文,创建报文的日期和时间都是同一个意思,因此提供这类信息的首部对这两种类型的报文来说也是通用的
下表列出了通用的信息性首部
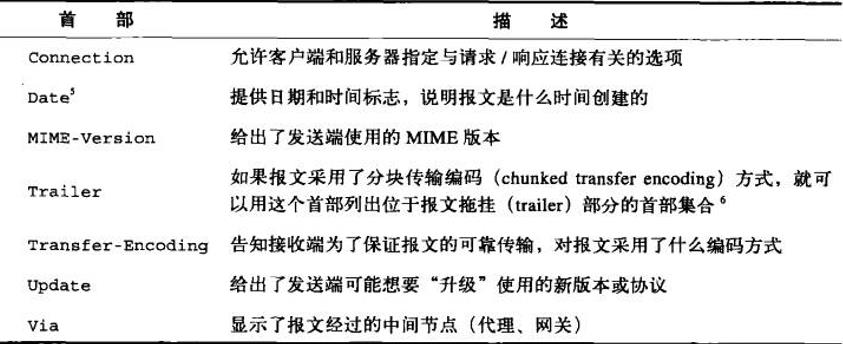
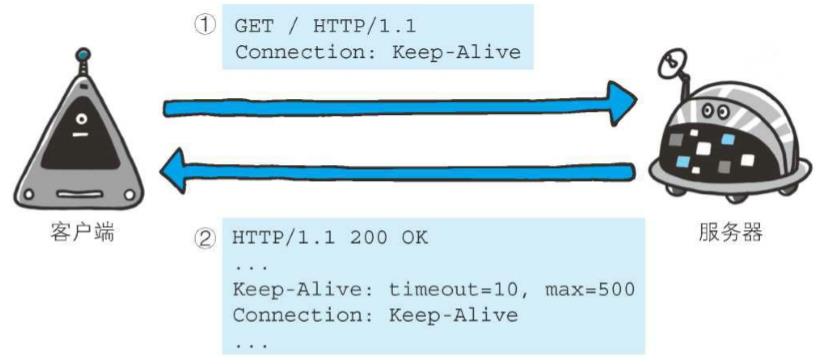
1、Connection
Connection首部主要用于连接管理,用于扩展keep-alive连接的HTTP/1.0客户端,keep-alive连接用于控制信息。在HTTP/1.1中,能识别出大部分较老的语义,但这个首部被赋予了新的功能
Connection首部可以承载3种不同类型的标签:a、HTTP首部字段名,列出了只与此连接有关的首部;b、任意标签值,用于描述此连接的非标准选项;c、值close,说明操作完成之后需关闭这条持久连接
a、首部字段名
应用程序收到带有Connection首部的HTTP/1.1报文后,应该对列表进行解析,并删除报文中所有在Connection首部列表中出现过的首部。它主要用于有代理网络环境,这样服务器或其他代理就可以指定不应传递的逐跳首部
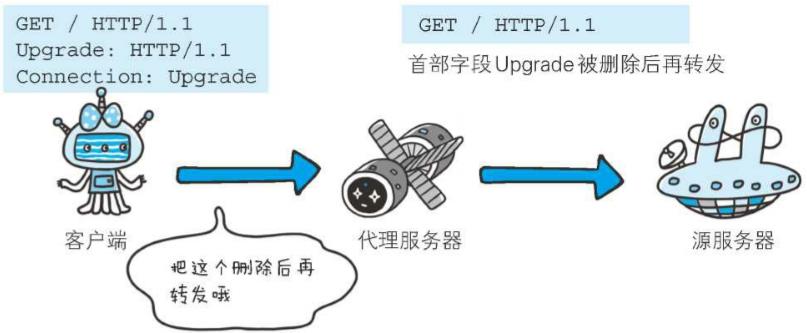
b、任意标签值
任意标签值用于描述该连接。比如,如果是一个信用卡订单的连接
Connection: bill-my-credit-card
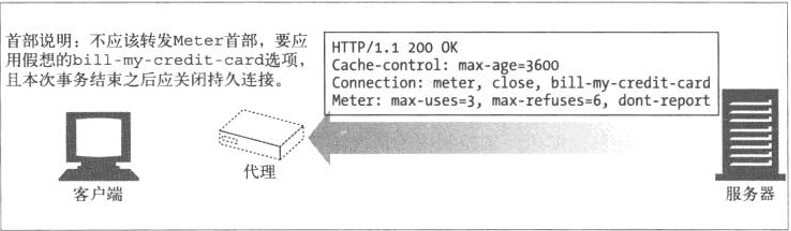
c、close
HTTP1.1版本的默认连接是持久连接。当服务器端想明确断开连接时,则指定Connection首部字段的值是Close
Connection: close
d、Keep-alive
HTTP1.0版本的默认连接都是非持久连接。因此,如果想在旧版本的HTTP协议上维持持久连接,需要将connection指定为keep-alive
2、Date
Date首部给出了报文创建的日期和时间。服务器响应中要包含这个首部,因为缓存在评估响应的新鲜度时,要用到这个服务器认定的报文创建时间和日期。对客户端来说,这个首部是可选的,但包含这个首部会更好
HTTP/1.1 协议使用在 RFC1123 中规定的日期时间的格式,如下所示
Date: Tue, 03 Jul 2016 04:40:59 GMT
之前的 HTTP 协议版本中使用在 RFC850 中定义的格式,如下所示
Date: Tue, 03-Jul-16 04:40:59 GMT
除此之外,还有一种格式。它与C标准库内的asctime()函数的输出格式一致
Date: Tue Jul 03 04:40:59 2016
3、MIME-Version
MIME是HTTP的近亲。尽管两者存在根本区別,但有些HTTP服务器确实构造了一些在MIME规范下同样有效的报文。在这种情况下,服务器可以提供MIME版本的首部
尽管HTTP/1.0规范中提到过这个首部,但它从未写入官方规范。很多比较老的服务器会发送带有这个首部的报文,但这些报文通常都不是有效的MIME报文,这样会让人觉得这个首部令人迷惑且不可信
MIME-Version: 1.0
4、Trailer
Trailer首部用于传输编码中,用于说明拖挂(在报文主体后记录)中提供了哪些首部
Trailer: Expires

5、Transfer-Encoding
首部字段Transfer-Encoding规定了传输报文主体时采用的编码方式
HTTP/1.1的传输编码方式仅对分块传输编码有效
Transfer-Encoding: chunked
6、Upgrade
首部字段Upgrade用于检测HTTP协议及其他协议是否可使用更高的版本进行通信,其参数值可以用来指定一个完全不同的通信协议
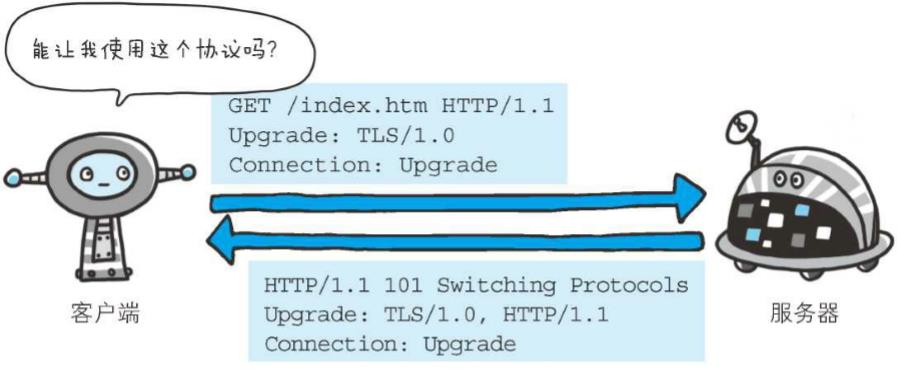
上图用例中,首部字段Upgrade指定的值为TLS/1.0。Connection的值被指定为Upgrade。Upgrade首部字段产生作用的Upgrade对象仅限于客户端和邻接服务器之间。因此,使用首部字段Upgrade时,还需要额外指定Connection:Upgrade
对于附有首部字段Upgrade的请求,服务器可用101 Switching Protocols 状态码作为响应返回
7、Via
使用首部字段Via是为了追踪客户端与服务器之间的请求和响应报文的传输路径
报文经过代理或网关时,会先在首部字段Via中附加该服务器的信息,然后再进行转发。这个做法和traceroute及电子邮件的Received首部的工作机制很类似
首部字段Via不仅用于追踪报文转发,还可避免请求回环发生。所以必须在经过代理时附加该首部字段内容
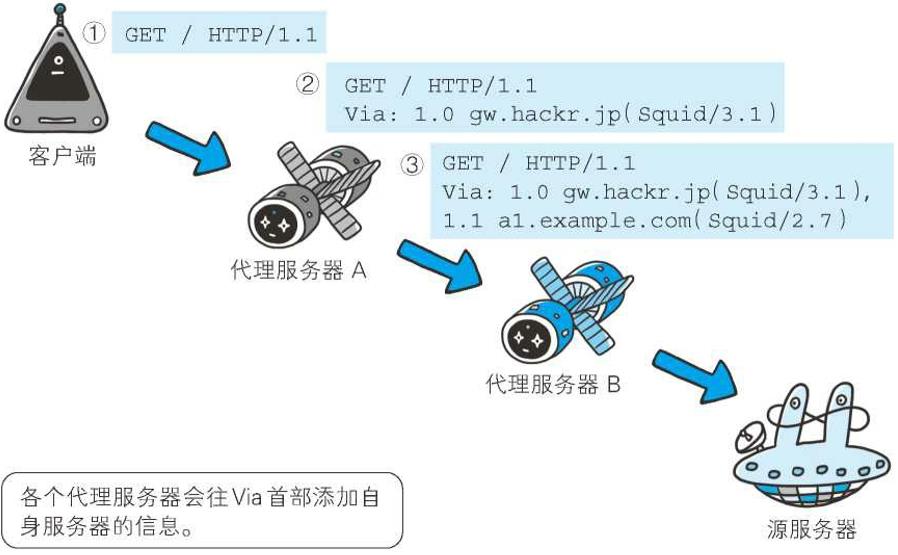
上图用例中,在经过代理服务器A时,Via首部附加了“1.0 gw.hackr.jp(Squid/3.1)”这样的字符串值。行头的1.0是指接收请求的服务器上应用的 HTTP协议版本。接下来经过代理服务器B时也是如此,在Via首部附加服务器信息,也可增加1个新的Via首部写入服务器信息
Via首部是为了追踪传输路径,所以经常会和TRACE方法一起使用。比如,代理服务器接收到由TRACE方法发送过来的请求(其中Max-Forwards:0)时,代理服务器就不能再转发该请求了。这种情况下,代理服务器会将自身的信息附加到Via首部后,返回该请求的响应
【通用缓存首部】
HTTP/1.0引入了第一个允许HTTP应用程序缓存对象本地副本的首部,这样就不需要总是直接从源端服务器获取了。最新的HTTP版本有非常丰富的缓存参数集
下表列出了基本的缓存首部

1、Cache-Control
通过指定首部字段Cache-Control的指令,就能操作缓存的工作机制
指令的参数是可选的,多个指令之间通过“,”分隔。首部字段Cache-Control的指令可用于请求及响应时
Cache-Control: private, max-age=0, no-cache
Cache-Control可用的指令按请求和响应分类如下所示
下表为缓存请求指令

指令 参数 说明 no-cache 无 强制向源服务器再次验证 no-store 无 不缓存请求或响应的任何内容 max-age=[秒] 必需 响应的最大Age值 max-stale(= [秒]) 可省略 接收已过期的响应 min-fresh=[秒] 必需 期望在指定时间内的响应仍有效 no-transform 无 代理不可更改媒体类型 only-if-cached 无 从缓存获取资源 cache-extension - 新指令标记(token)
下表为缓存响应指令
指令 参数 说明 public 无 可向任意方提供响应的缓存 private 可省略 仅向特定用户返回响应 no-cache 省略 缓存前必须先确认其有效性 no-store 无 不缓存请求或响应的任何内容 no-transform 无 代理不可更改媒体类型 must-revalidate 无 可缓存但必须再向源服务器进行确认 proxy-revalidate 无 要求中间缓存服务器对缓存的响应有效性再进行确认 max-age=[秒] 必需 响应的最大Age值 s-maxage=[秒] 必需 公共缓存服务器响应的最大Age值 cache-extension - 新指令标记(token)
(public)
Cache-Control: public
当指定使用public指令时,则明确表明其他用户也可利用缓存
(private)
Cache-Control: private
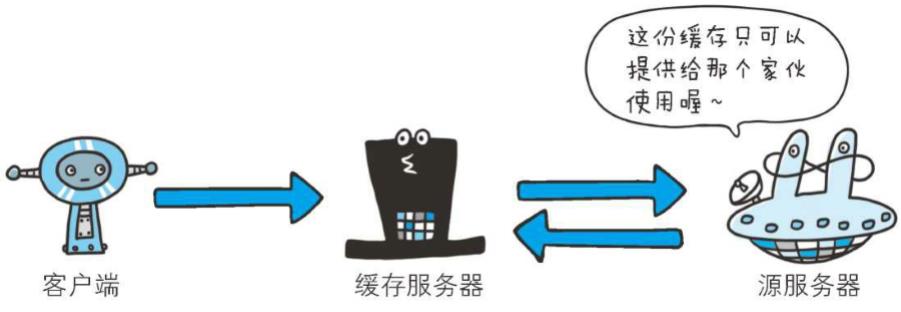
当指定private指令后,响应只以特定的用户作为对象,这与public指令的行为相反
缓存服务器会对该特定用户提供资源缓存的服务,对于其他用户发送过来的请求,代理服务器则不会返回缓存
(no-cache)
Cache-Control: no-cache
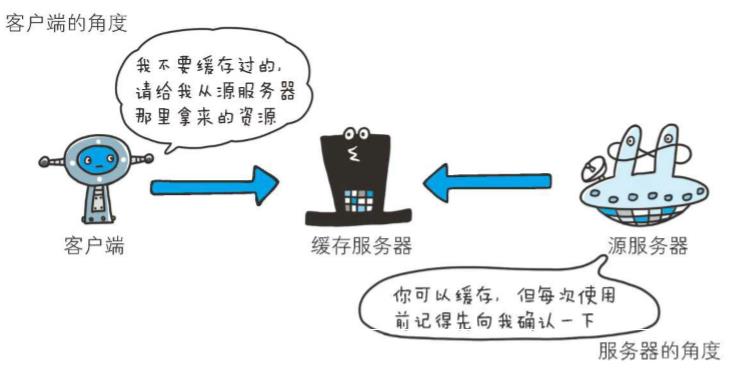
使用no-cache指令的目的是为了防止从缓存中返回过期的资源
客户端发送的请求中如果包含no-cache指令,则表示客户端将不会接收缓存过的响应。于是,“中间”的缓存服务器必须把客户端请求转发给源服务器
如果服务器返回的响应中包含no-cache指令,那么缓存服务器不能对资源进行缓存。源服务器以后也将不再对缓存服务器请求中提出的资源有效性进行确认,且禁止其对响应资源进行缓存操作
(no-cache=Location)
Cache-Control: no-cache=Location
由服务器返回的响应中,若报文首部字段Cache-Control中对no-cache字段名具体指定参数值,那么客户端在接收到这个被指定参数值的首部字段对应的响应报文后,就不能使用缓存。换言之,无参数值的首部字段可以使用缓存。只能在响应指令中指定该参数
(no-store)
Cache-Control: no-store
当使用no-store指令时,暗示请求(和对应的响应)或响应中包含机密信息
因此,该指令规定缓存不能在本地存储请求或响应的任一部分
(s-maxage)
Cache-Control: s-maxage=604800(单位:秒)
s-maxage指令的功能和max-age指令的相同,它们的不同点是s-maxage指令只适用于供多位用户使用的公共缓存服务器。也就是说,对于向同一用户重复返回响应的服务器来说,这个指令没有任何作用
另外,当使用s-maxage指令后,则直接忽略对Expires首部字段及max-age指令的处理
(max-age)
Cache-Control: max-age=604800(单位:秒)
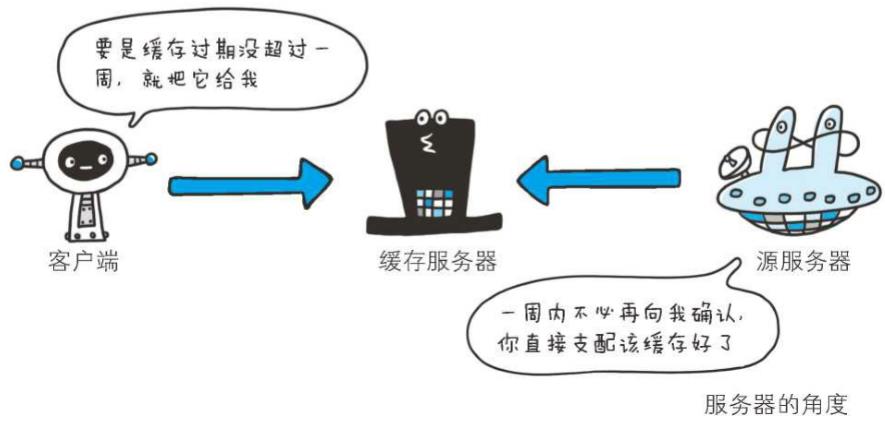
当客户端发送的请求中包含max-age指令时,如果判定缓存资源的缓存时间数值比指定时间的数值更小,那么客户端就接收缓存的资源。另外,当指定max-age值为0,那么缓存服务器通常需要将请求转发给源服务器
当服务器返回的响应中包含max-age指令时,缓存服务器将不对资源的有效性再作确认,而max-age数值代表资源保存为缓存的最长时间
应用HTTP/1.1版本的缓存服务器遇到同时存在Expires首部字段的情况时,会优先处理max-age指令,而忽略掉Expires首部字段。而HTTP/1.0版本的缓存服务器的情况却相反,max-age指令会被忽略掉
(min-fresh)
Cache-Control: min-fresh=60(单位:秒)
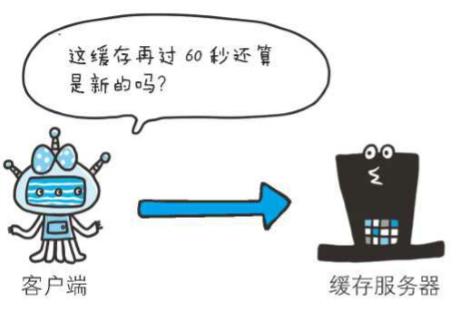
min-fresh指令要求缓存服务器返回至少还未过指定时间的缓存资源
比如,当指定min-fresh为60秒后,过了60秒的资源都无法作为响应返回了
(max-stale)
Cache-Control: max-stale=3600(单位:秒)
使用max-stale可指示缓存资源,即使过期也照常接收
如果指令未指定参数值,那么无论经过多久,客户端都会接收响应;如果指令中指定了具体数值,那么即使过期,只要仍处于max-stale指定的时间内,仍旧会被客户端接收
(only-if-cached)
Cache-Control: only-if-cached
使用only-if-cached指令表示客户端仅在缓存服务器本地缓存目标资源的情况下才会要求其返回。换言之,该指令要求缓存服务器不重新加载响应,也不会再次确认资源有效性。若发生请求缓存服务器的本地缓存无响应,则返回状态码504 Gateway Timeout
(must-revalidate)
Cache-Control: must-revalidate
使用must-revalidate指令,代理会向源服务器再次验证即将返回的响应缓存目前是否仍然有效
若代理无法连通源服务器再次获取有效资源的话,缓存必须给客户端一条504(Gateway Timeout)状态码。另外,使用must-revalidate指令会忽略请求的max-stale指令(即使已经在首部使用了max-stale,也不会再有效果)
(proxy-revalidate)
Cache-Control: proxy-revalidate
proxy-revalidate指令要求所有的缓存服务器在接收到客户端带有该指令的请求返回响应之前,必须再次验证缓存的有效性
(no-transform)
Cache-Control: no-transform
使用no-transform指令规定无论是在请求还是响应中,缓存都不能改变实体主体的媒体类型
这样做可防止缓存或代理压缩图片等类似操作
(community)
Cache-Control: private, community="UCI"
通过cache-extension标记(token),可以扩展Cache-Control首部字段内的指令
如上例,Cache-Control首部字段本身没有community这个指令。借助extension tokens实现了该指令的添加。如果缓存服务器不能理解community这个新指令,就会直接忽略。因此,extension tokens仅对能理解它的缓存服务器来说是有意义的
2、Pragma
Pragma是HTTP/1.1之前版本的历史遗留字段,仅作为与HTTP/1.0的向后兼容而定义。规范定义的形式唯一,如下所示
Pragma: no-cache
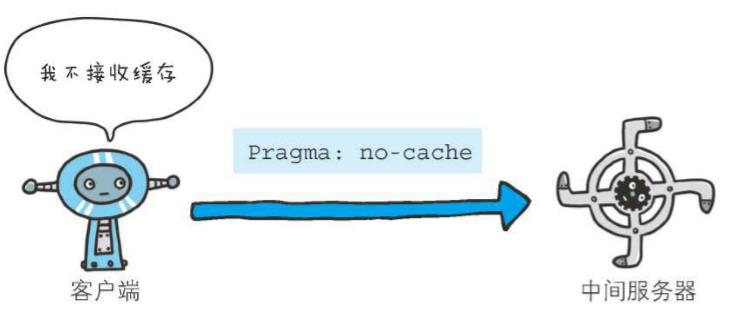
该首部字段属于通用首部字段,但只用在客户端发送的请求中。客户端会要求所有的中间服务器不返回缓存的资源
所有的中间服务器如果都能以HTTP/1.1为基准,那直接采用Cache-Control:nocache指定缓存的处理方式是最为理想的。但要整体掌握全部中间服务器使用的HTTP协议版本却是不现实的。因此,发送的请求会同时含有下面两个首部字段
Cache-Control: no-cache Pragma: no-cache
请求首部
请求首部是只在请求报文中有意义的首部。用于说明是谁或什么在发送请求、请求源自何处,或者客户端的喜好及能力。服务器可以根据请求首部给出的客户端信息,试着为客户端提供更好的响应
下表列出了请求的信息性首部

[注意]尽管有些客户端实现了UA-*首部,但我们认为UA-*首部是有副作用的。不应该将内容,尤其是HTML,局限于特定的客户端配置
1、From
From: info@hackr.jp
首部字段From用来告知服务器使用用户代理的用户的电子邮件地址。通常,其使用目的就是为了显示搜索引擎等用户代理的负责人的电子邮件联系方式。使用代理时,应尽可能包含From首部字段(但可能会因代理不同,将电子邮件地址记录在User-Agent首部字段内)
2、host
Host: www.hackr.jp

虚拟主机运行在同一个 IP上,因此使用首部字段 Host 加以区分
首部字段Host会告知服务器,请求的资源所处的互联网主机名和端口号。Host首部字段在HTTP/1.1规范内是唯一一个必须被包含在请求内的首部字段
首部字段Host和以单台服务器分配多个域名的虚拟主机的工作机制有很密切的关联,这是首部字段 Host 必须存在的意义
请求被发送至服务器时,请求中的主机名会用IP地址直接替换解决。但如果这时,相同的IP地址下部署运行着多个域名,那么服务器就会无法理解究竟是哪个域名对应的请求。因此,就需要使用首部字段Host来明确指出请求的主机名。若服务器未设定主机名,那直接发送一个空值即可
3、Referer
Referer: http://www.hackr.jp/index.htm
首部字段Referer会告知服务器请求的原始资源的URI
客户端一般都会发送Referer首部字段给服务器。但当直接在浏览器的地址栏输入URI,或出于安全性的考虑时,也可以不发送该首部字段
因为原始资源的URI中的查询字符串可能含有ID和密码等保密信息,要是写进Referer转发给其他服务器,则有可能导致保密信息的泄露
另外,Referer的正确的拼写应该是Referrer,但不知为何,大家一直沿用这个错误的拼写
4、User-Agent
User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64; rv:13.0) Gecko/20100101

首部字段User-Agent用于传达浏览器的种类,User-Agent会将创建请求的浏览器和用户代理名称等信息传达给服务器。由网络爬虫发起请求时,有可能会在字段内添加爬虫作者的电子邮件地址。此外,如果请求经过代理,那么中间也很可能被添加上代理服务器的名称
【Accept首部】
Accept首部为客户端提供了一种将其喜好和能力告知服务器的方式,包括它们想要什么,可以使用什么,以及最重要的,它们不想要什么。这样,服务器就可以根据这些额外信息,对要发送的内容做出更明智的决定。Accept首部会使连接的两端都受益。客户端会得到它们想要的内容,服务器则不会浪费其时间和带宽来发送客户端无法使用的东西
下表列出了各种Accept首部

1、Accept
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept首部字段可通知服务器,用户代理能够处理的媒体类型及媒体类型的相对优先级。可使用type/subtype这种形式,一次指定多种媒体类型
下面试举几个媒体类型的例子
文本文件
text/html, text/plain, text/css ... application/xhtml+xml, application/xml ...
图片文件
image/jpeg, image/gif, image/png ...
视频文件
video/mpeg, video/quicktime ...
应用程序使用的二进制文件
application/octet-stream, application/zip ...
比如,如果浏览器不支持PNG图片的显示,那Accept就不指定image/png,而指定可处理的image/gif和image/jpeg等图片类型
若想要给显示的媒体类型增加优先级,则使用q=来额外表示权重值,用分号(;)进行分隔。权重值q的范围是0-1(可精确到小数点后3 位),且1为最大值。不指定权重q值时,默认权重为q=1.0
当服务器提供多种内容时,将会首先返回权重值最高的媒体类型
2、Accept-Charset
Accept-Charset: iso-8859-5, unicode-1-1;q=0.8
Accept-Charset首部字段可用来通知服务器用户代理支持的字符集及字符集的相对优先顺序。另外,可一次性指定多种字符集。与首部字段Accept相同的是可用权重q值来表示相对优先级。该首部字段应用于内容协商机制的服务器驱动协商
3、Accept-Encoding
Accept-Encoding: gzip, deflate
Accept-Encoding首部字段用来告知服务器用户代理支持的内容编码及内容编码的优先级顺序。可一次性指定多种内容编码
下面试举出几个内容编码的例子
gzip:由文件压缩程序gzip(GNU zip)生成的编码格式(RFC1952),采用Lempel-Ziv算法(LZ77)及32位循环冗余校验(Cyclic Redundancy Check,通称CRC)
compress:由UNIX文件压缩程序compress生成的编码格式,采用Lempel-Ziv-Welch算法(LZW)
deflate:组合使用zlib格式(RFC1950)及由deflate压缩算法(RFC1951)生成的编码格式。
identity:不执行压缩或不会变化的默认编码格式
采用权重q值来表示相对优先级,这点与首部字段Accept相同。另外,也可使用星号(*)作为通配符,指定任意的编码格式
4、Accept-Language
Accept-Language: zh-cn,zh;q=0.7,en-us,en;q=0.3
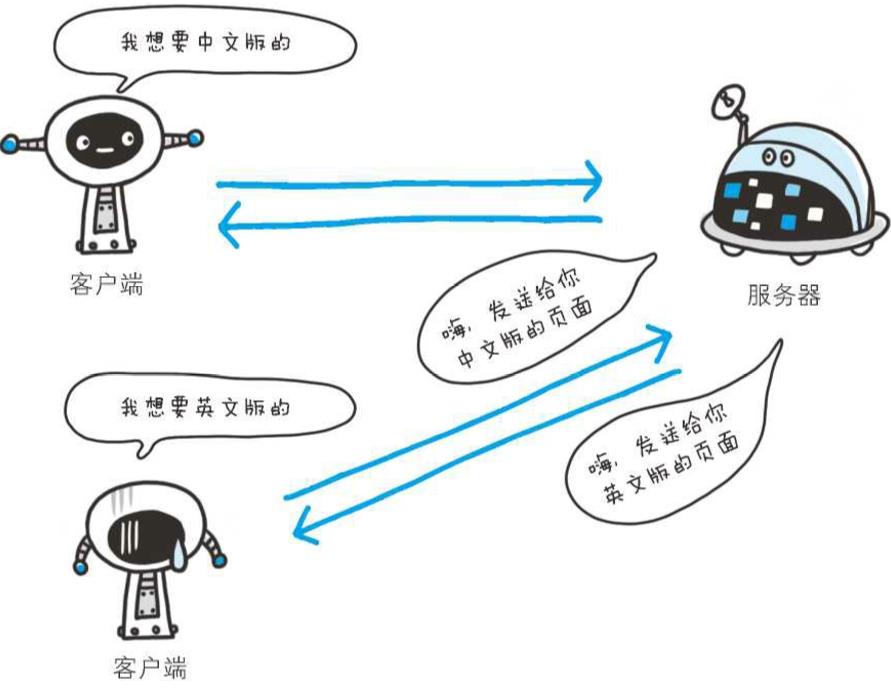
首部字段Accept-Language用来告知服务器用户代理能够处理的自然语言集(指中 文或英文等),以及自然语言集的相对优先级。可一次指定多种自然语言集
和Accept首部字段一样,按权重值q来表示相对优先级。在上述图例中,客户端在服务器有中文版资源的情况下,会请求其返回中文版对应的响应,没有中文版时,则请求返回英文版响应
5、TE
TE: gzip, deflate;q=0.5
首部字段TE会告知服务器客户端能够处理响应的传输编码方式及相对优先级。它和首部字段Accept-Encoding的功能很相像,但是用于传输编码
首部字段TE除指定传输编码之外,还可以指定伴随trailer字段的分块传输编码的方式。应用后者时,只需把trailers赋值给该字段值TE: trailers
【条件请求首部】
有时客户端希望为请求加上某些限制。比如,如果客户端已经有了一份文档副本,就希望只在服务器上的文档与客户端拥有的副本有所区别时,才请求服务器传输文档。通过条件请求首部,客户端就可以为请求加上这种限制,要求服务器在对请求进行响应之前,确保某个条件为真
下表列出了各种条件请求首部

1、Expect
Expect: 100-continue
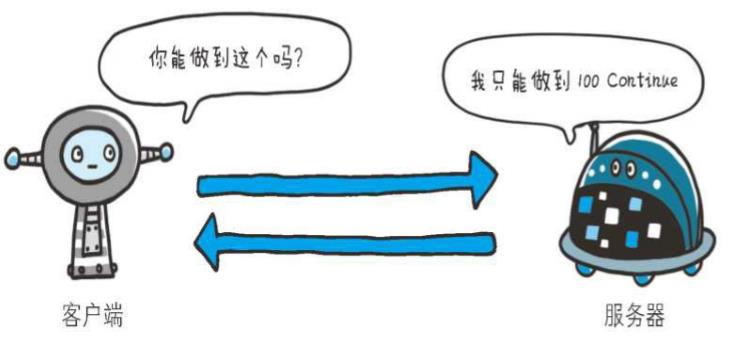
客户端使用首部字段Expect来告知服务器,期望出现的某种特定行为。因服务器无法理解客户端的期望作出回应而发生错误时,会返回状态码417 Expectation Failed
客户端可以利用该首部字段,写明所期望的扩展。虽然HTTP/1.1规范只定义了100continue(状态码 100 Continue 之意)
等待状态码100响应的客户端在发生请求时,需要指定Expect:100-continue
2、If-Match
If-Match: "123456"
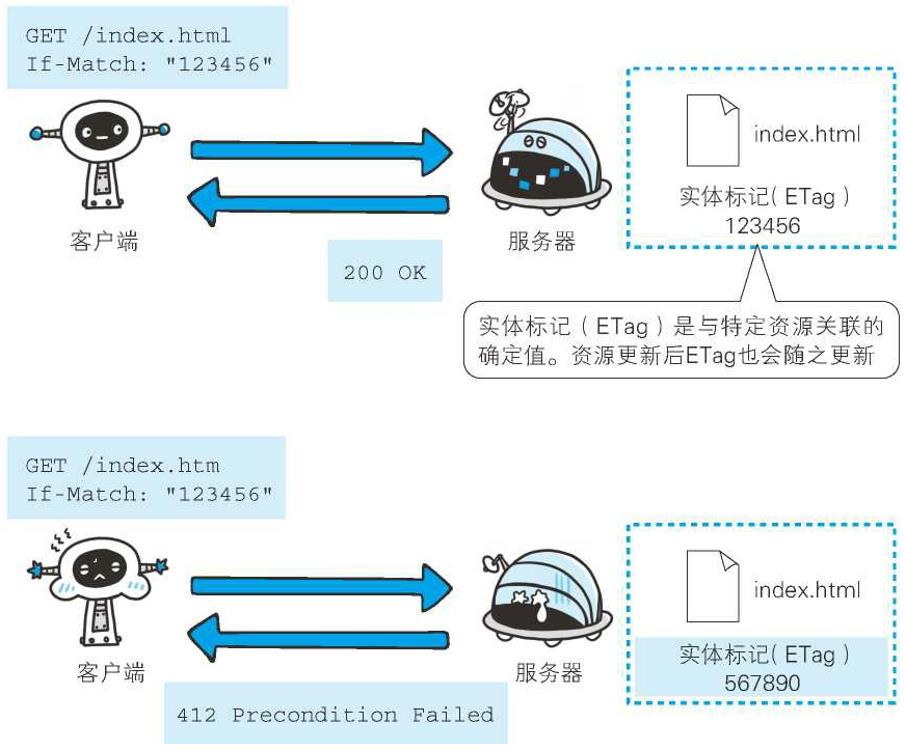
形如If-xxx这种样式的请求首部字段,都可称为条件请求。服务器接收到附带条件的请求后,只有判断指定条件为真时,才会执行请求
首部字段If-Match,属附带条件之一,它会告知服务器匹配资源所用的实体标记(ETag)值。这时的服务器无法使用弱ETag值
服务器会比对If-Match的字段值和资源的ETag值,仅当两者一致时,才会执行请求。反之,则返回状态码412 Precondition Failed的响应
还可以使用星号(*)指定If-Match的字段值。针对这种情况,服务器将会忽略ETag的值,只要资源存在就处理请求
3、If-Modified-Since
If-Modified-Since: Thu, 15 Apr 2004 00:00:00 GMT
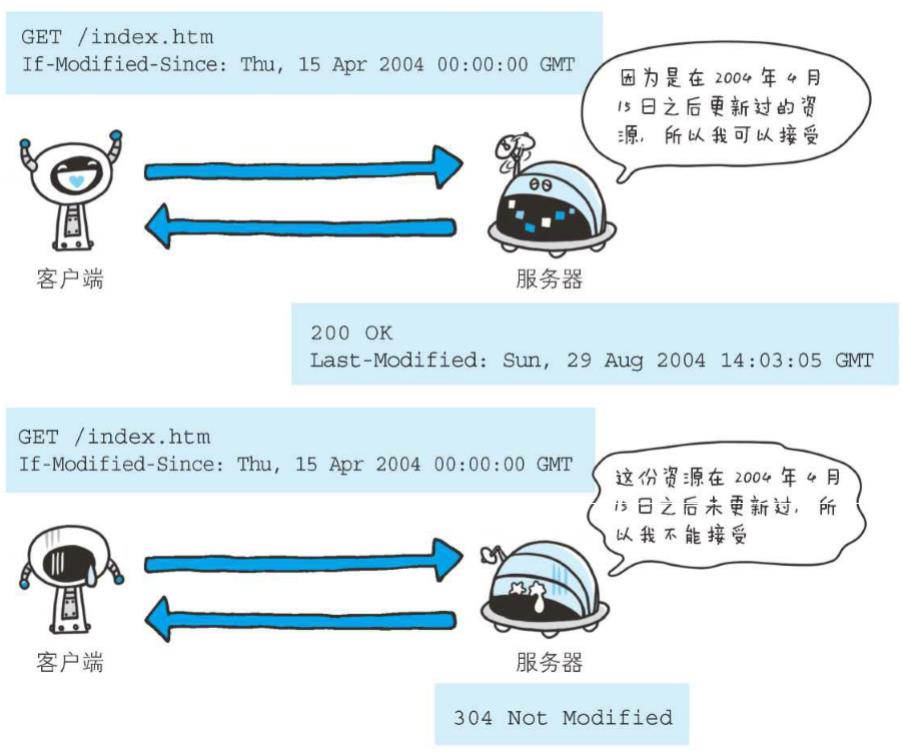
首部字段If-Modified-Since,属附带条件之一,它会告知服务器若If-Modified-Since字段值早于资源的更新时间,则希望能处理该请求。而在指定If-Modified-Since字段值的日期时间之后,如果请求的资源都没有过更新,则返回状态码304 Not Modified的响应
4、If-None-Match
If-None-Match: *
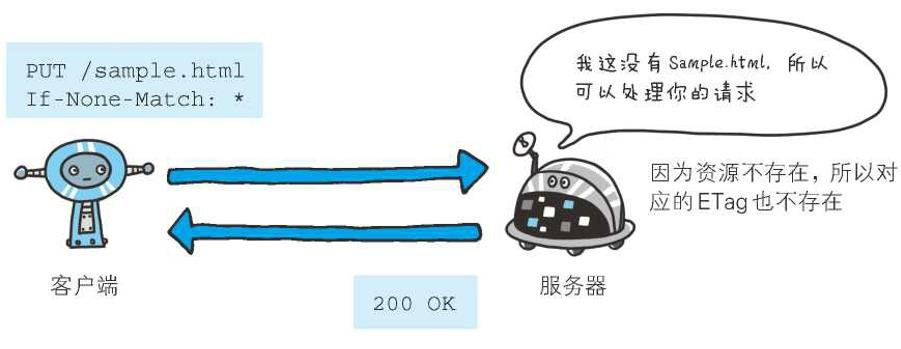
首部字段If-None-Match属于附带条件之一。它和首部字段If-Match作用相反。用于指定If-None-Match字段值的实体标记(ETag)值与请求资源的ETag 不一致时,它就告知服务器处理该请求
在GET或HEAD方法中使用首部字段If-None-Match可获取最新的资源。因此,这与使用首部字段If-Modified-Since时有些类似
5、Range
Range: bytes=5001-10000
对于只需获取部分资源的范围请求,包含首部字段Range即可告知服务器资源的指 范围。上面的示例表示请求获取从第5001字节至第10000字节的资源
接收到附带Range首部字段请求的服务器,会在处理请求之后返回状态码为 206 Partial Content 的响应。无法处理该范围请求时,则会返回状态码 200 OK 的响应及全部资源
6、If-Range
If-Range: "123456"
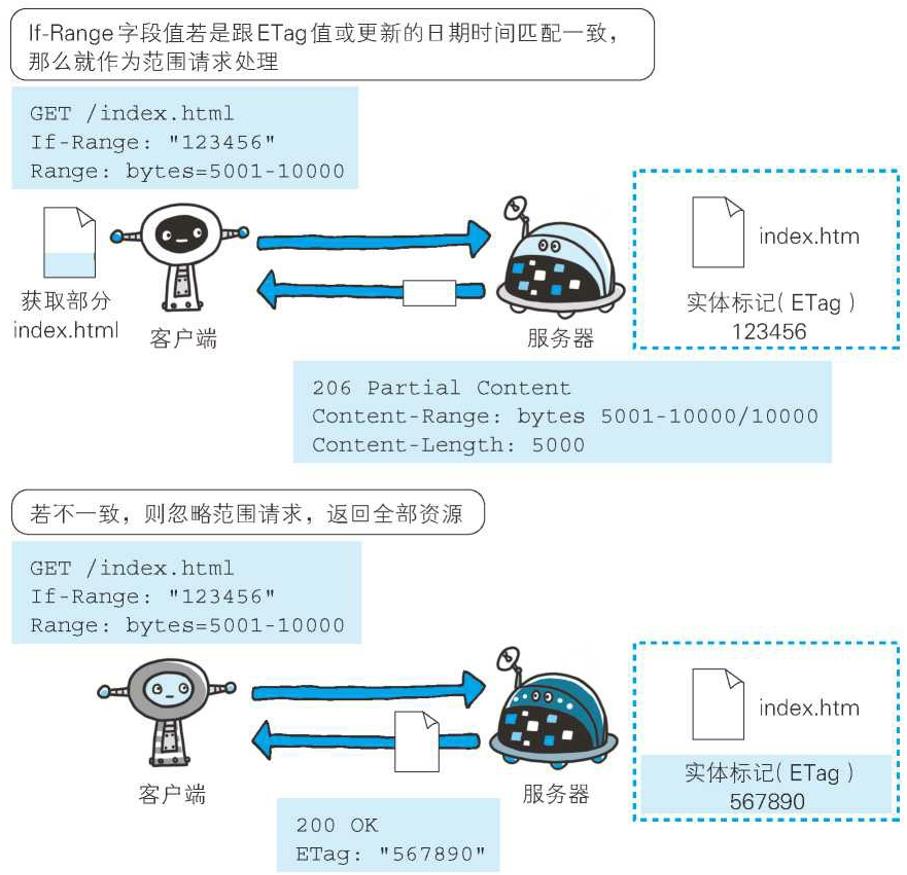
首部字段If-Range属于附带条件之一。它告知服务器若指定的If-Range字段值(ETag值或者时间)和请求资源的ETag值或时间相一致时,则作为范围请求处理。反之,则返回全体资源
下面我们思考一下不使用首部字段If-Range发送请求的情况。服务器端的资源如果更新,那客户端持有资源中的一部分也会随之无效,当然,范围请求作为前提是无效的。这时,服务器会暂且以状态码412 Precondition Failed作为响应返回,其目的是催促客户端再次发送请求。这样一来,与使用首部字段If-Range比起来,就需要花费两倍的功夫
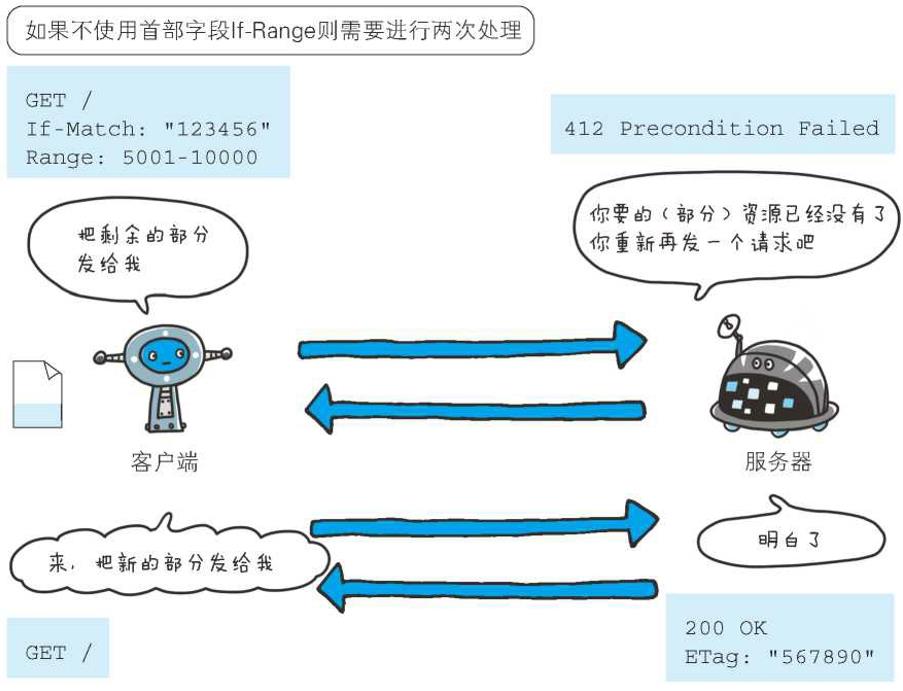
7、If-Unmodified-Since
If-Unmodified-Since: Thu, 03 Jul 2012 00:00:00 GMT
首部字段If-Unmodified-Since和首部字段If-Modified-Since的作用相反。它的作用的是告知服务器,指定的请求资源只有在字段值内指定的日期时间之后,未发生更新的情况下,才能处理请求。如果在指定日期时间后发生了更新,则以状态码412 Precondition Failed作为响应返回
【安全请求首部】
HTTP本身就支持一种简单的机制,可以对请求进行质询/响应认证。这种机制要求客户端在获取特定的资源之前,先对自身进行认证,这样就可以使事务稍微安全一些
下表列出了一些安全请求首部

1、Authorization
Authorization: Basic dWVub3NlbjpwYXNzd29yZA==
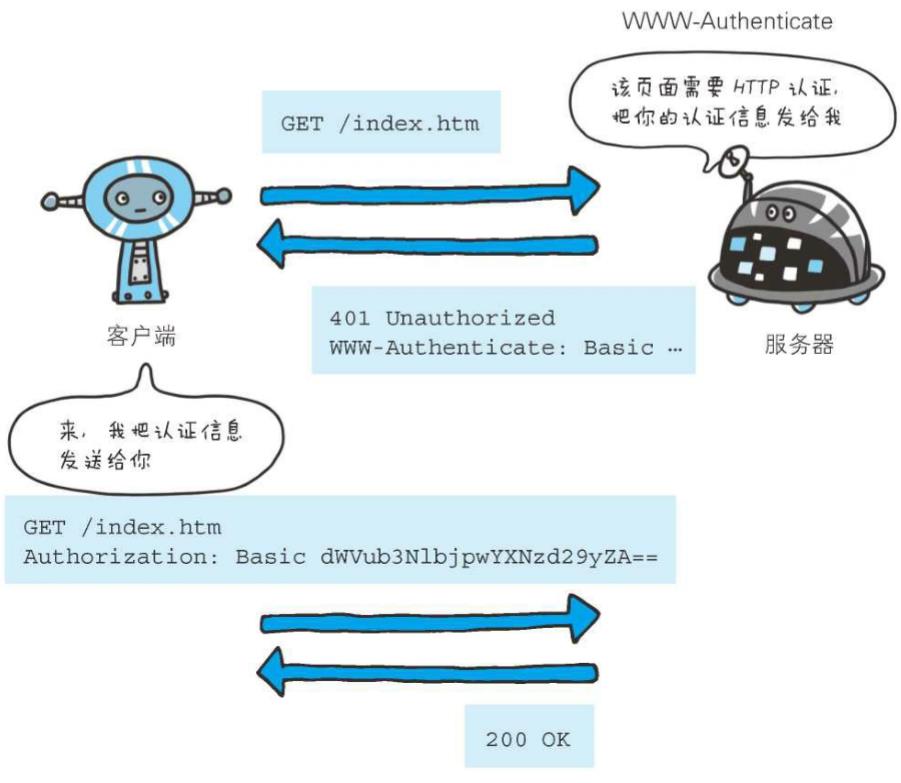
首部字段Authorization是用来告知服务器,用户代理的认证信息(证书值)。通常,想要通过服务器认证的用户代理会在接收到返回的401状态码响应后,把首部字段Authorization加入请求中。共用缓存在接收到含有Authorization首部字段的请求时的操作处理会略有差异
2、Cookie
Cookie: status=enable
首部字段Cookie会告知服务器,当客户端想获得HTTP状态管理支持时,就会在请求中包含从服务器接收到的Cookie。接收到多个Cookie时,同样可以以多个Cookie形式发送
3、Cookie2
Cookie2: $version="1"
Cookie2首部是用于客户端识别和跟踪的扩展首部。Cookie2用于识别请求发起者能够理解哪种类型的Cookie
【代理请求首部】
随着因特网上代理的普遍应用,人们定义了几个首部来协助其更好地工作
下表列出了一些代理请求首部

1、Max-Forwards
Max-Forwards: 10

通过TRACE方法或OPTIONS方法,发送包含首部字段Max-Forwards的请求时,该字段以十进制整数形式指定可经过的服务器最大数目。服务器在往下一个服务器转发请求之前,Max-Forwards的值减1后重新赋值。当服务器接收到Max-Forwards值为0的请求时,则不再进行转发,而是直接返回响应
使用HTTP协议通信时,请求可能会经过代理等多台服务器。途中,如果代理服务器由于某些原因导致请求转发失败,客户端也就等不到服务器返回的响应了。对此,我们无从可知
可以灵活使用首部字段Max-Forwards,针对以上问题产生的原因展开调查。由于当Max-Forwards字段值为0时,服务器就会立即返回响应,由此我们至少可以对以那台服务器为终点的传输路径的通信状况有所把握
2、Proxy-Authorization
Proxy-Authorization: Basic dGlwOjkpNLAGfFY5
接收到从代理服务器发来的认证质询时,客户端会发送包含首部字段ProxyAuthorization的请求,以告知服务器认证所需要的信息
这个行为是与客户端和服务器之间的HTTP访问认证相类似的,不同之处在于,认证行为发生在客户端与代理之间。客户端与服务器之间的认证,使用首部字段Authorization可起到相同作用
3、Proxy-Connection
Netscape的浏览器及代理实现者们提出了一个对盲中继问题的变通做法,这种做法并不要求所有的Web应用程序支持高版本的HTTP。这种变通做法引入了一个名为Proxy-Connection的新首部,解决了在客户端后面紧跟着一个盲中继所带来的问题——但并没有解决所有其他情况下存在的问题。在显式配置了代理的情况下,现代浏览器都实现了Proxy-Connection,很多代理都能够理解它
Proxy-Connection:Keep-alive
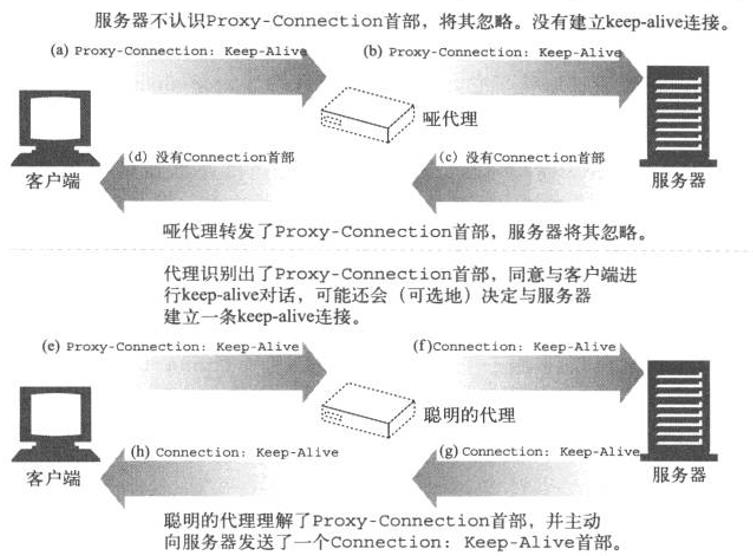
响应首部
响应报文有自己的响应首部集。响应首部为客户端提供了一些额外信息,比如谁在发送响应、响应者的功能,甚至与响应相关的一些特殊指令。这些首部有助于客户端处理响应,并在将来发起更好的请求
下表列出了一些响应的信息性首部

[注意]Public首部在RFC 2068中定义,但在RFC 2616中并没有出现。此外,RFC 2616中也没有定义Title首部
1、Age
Age: 600
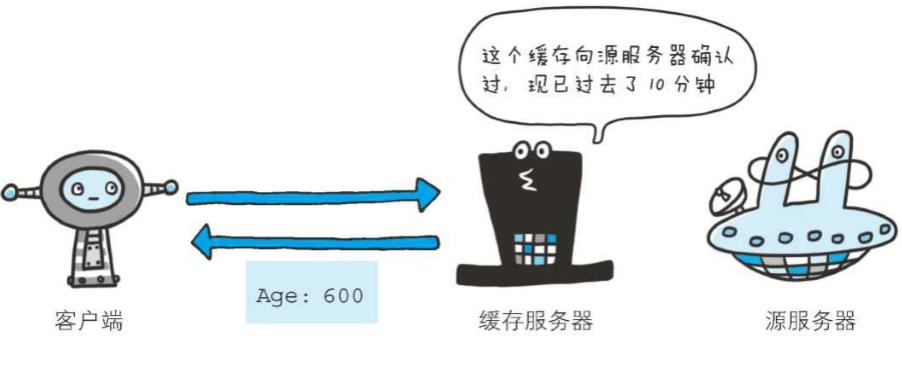
首部字段Age能告知客户端,源服务器在多久前创建了响应。字段值的单位为秒。若创建该响应的服务器是缓存服务器,Age值是指缓存后的响应再次发起认证到认证完成的时间值。代理创建响应时必须加上首部字段Age
2、Retry-After
Retry-After: 120
首部字段Retry-After告知客户端应该在多久之后再次发送请求。主要配合状态码503 Service Unavailable响应,或3xx Redirect响应一起使用
字段值可以指定为具体的日期时间(Wed, 04 Jul 2012 06:34:24 GMT 等格式),也可以是创建响应后的秒数
3、Server
Server: Apache/2.2.17 (Unix) Server: Apache/2.2.6 (Unix) php/5.2.5
首部字段Server告知客户端当前服务器上安装的HTTP服务器应用程序的信息。不单单会标出服务器上的软件应用名称,还有可能包括版本号和安装时启用的可选项
4、Warning
HTTP/1.1的Warning首部是从HTTP/1.0的响应首部(Retry-After)演变过来的。该首部通常会告知用户一些与缓存相关的问题的警告
Warning: 113 gw.hackr.jp:8080 "Heuristic expiration" Tue, 03 Jul 2012 05
Warning首部的格式如下,最后的日期时间部分可省略
Warning: [警告码][警告的主机:端口号]“[警告内容]”([日期时间])
HTTP/1.1中定义了7种警告。警告码对应的警告内容仅推荐参考。另外,警告码具备扩展性,今后有可能追加新的警告码
101 响应过时了
当知道一条响应报文已过期时(比如,原始服务器无法进行再验证时),就必须包含这条警告信息
111 再验证失败
如果缓存试图与原始服务器进行响应再验证,但由于缓存无法抵达原始服务器造成了再验证失败,那就必须在发给客户端的响应中包含这条警告信息
112 断开连接操作
通知性警告信息。如果缓存到网络的连接被删除了就应该使用此警告信息
113 试探性过期
如果新鲜性试探过期时间大于24小时,而且返回的响应使用期大于24小时,缓存中就必须包含这条警告信息
199 杂项警告
收到这条警告的系统不能使用任何自动响应。报文中可能,而且很可能应该包含一个主体,其中携带了为用户提供的额外信息
214 使用了转换
如果中间应用程序执行了任何会改变响应内容编码的转换,就必须由任意一个中间应用程序(比如代理)来添加这条警告
299 持久杂项警告
接收这条警告的系统不能进行任何自动的回应。错误中可能包含一个主体部分,它为用户提供了更多的信息
【协商首部】
如果资源有多种表示方法——比如,如果服务器上有某文档的法语和德语译稿,HTTP/1.1可以为服务器和客户端提供对资源进行协商的能力
下面列出了几个首部,服务器可以用它们来传递与可协商资源有关的信息

1、Accept-Ranges
Accept-Ranges: bytes
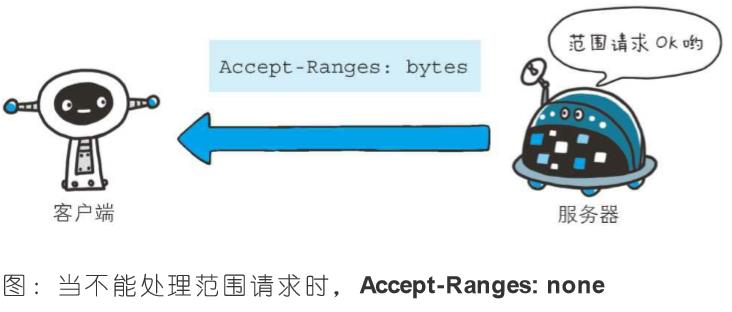
首部字段Accept-Ranges是用来告知客户端服务器是否能处理范围请求,以指定获取服务器端某个部分的资源
可指定的字段值有两种,可处理范围请求时指定其为bytes,反之则指定其为none
2、Vary
Vary: Accept-Language
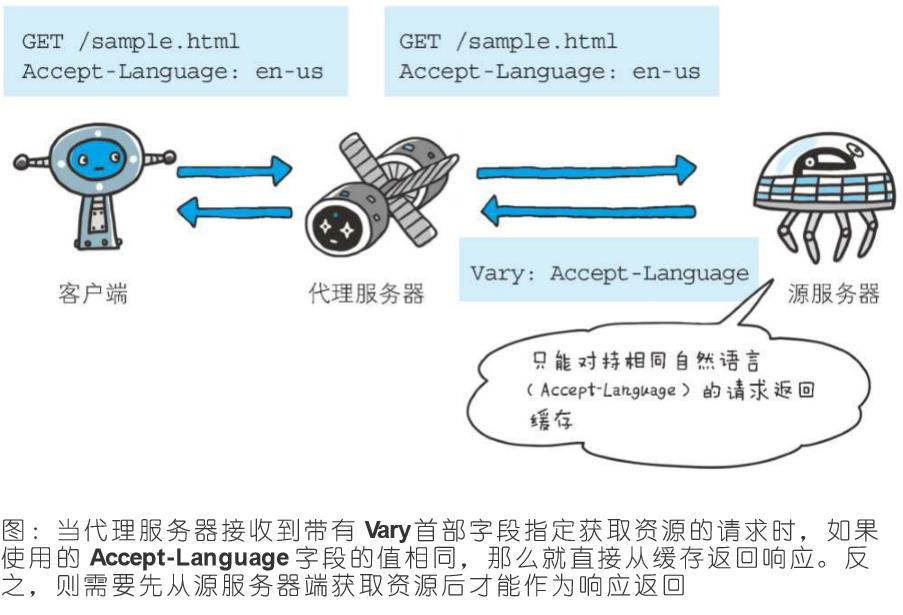
首部字段Vary可对缓存进行控制。源服务器会向代理服务器传达关于本地缓存使用方法的命令
从代理服务器接收到源服务器返回包含Vary指定项的响应之后,若再要进行缓存,仅对请求中含有相同Vary指定首部字段的请求返回缓存。即使对相同资源发起请求,但由于Vary指定的首部字段不相同,因此必须要从源服务器重新获取资源
【安全响应首部】
上面已经介绍过安全请求首部,本质上这里说的就是HTTP的质询/响应认证机制的响应侧。
下表列出了安全响应首部

1、Proxy-Authenticate
Proxy-Authenticate: Basic realm="Usagidesign Auth"
首部字段Proxy-Authenticate会把由代理服务器所要求的认证信息发送给客户端。它与客户端和服务器之间的HTTP访问认证的行为相似,不同之处在于其认证行为是在客户端与代理之间进行的。而客户端与服务器之间进行认证时,首部字段WWW-Authorization有着相同的作用
2、Set-Cookie
Set-Cookie: status=enable; expires=Tue, 05 Jul 2011 07:26:31 GMT; path=/;
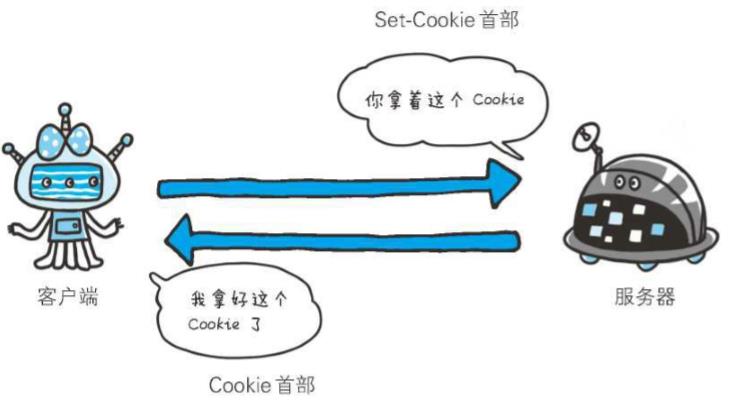
当服务器准备开始管理客户端的状态时,会事先告知各种信息
下面的表格列举了Set-Cookie的字段值
属性 说明 NAME=VALUE 赋予Cookie的名称和其值(必需项) expires=DATE Cookie的有效期(若不明确指定则默认为浏览器 关闭前为止) path=PATH 将服务器上的文件目录作为Cookie的适用对象(若不指定则默认为文档所在的文件目录) domain=域名 作为Cookie适用对象的域名(若不指定则默认为 创建Cookie的服务器的域名) Secure 仅在HTTPS安全通信时才会发送Cookie HttpOnly 加以限制,使Cookie不能被javascript脚本访问
(expires)
Cookie的expires属性指定浏览器可发送Cookie的有效期。当省略expires属性时,其有效期仅限于维持浏览器会话(Session)时间段内。这通常限于浏览器应用程序被关闭之前
另外,一旦Cookie从服务器端发送至客户端,服务器端就不存在可以显式删除Cookie的方法。但可通过覆盖已过期的Cookie,实现对客户端Cookie的实质性删除操作
(path)
Cookie的path属性可用于限制指定Cookie的发送范围的文件目录。不过另有办法可避开这项限制,看来对其作为安全机制的效果不能抱有期待
(domain)
通过Cookie的domain属性指定的域名可做到与结尾匹配一致。比如,当指定example.com后,除example.com以外,www.example.com或www2.example.com等都可以发送Cookie
因此,除了针对具体指定的多个域名发送Cookie之外,不指定domain属性显得更安全
(secure)
Cookie的secure属性用于限制Web页面仅在HTTPS安全连接时,才可以发送Cookie。发送Cookie时,指定secure属性的方法如下所示
Set-Cookie: name=value; secure
以上例子仅当在https://www.example.com/(HTTPS)安全连接的情况下才会进行Cookie的回收。也就是说,即使域名相同,http://www.example.com/(HTTP)也不会发生Cookie回收行为
当省略secure属性时,不论HTTP还是HTTPS,都会对Cookie进行回收
(HttpOnly)
Cookie的HttpOnly属性是Cookie的扩展功能,它使JavaScript脚本无法获得Cookie。其主要目的为防止跨站脚本攻击(Cross-site scripting,XSS)对Cookie的信息窃取
发送指定HttpOnly属性的Cookie的方法如下所示
Set-Cookie: name=value; HttpOnly
通过上述设置,通常从Web页面内还可以对Cookie进行读取操作。但使用JavaScript的document.cookie就无法读取附加HttpOnly属性后的Cookie的内容了。因此,也就无法在XSS中利用JavaScript劫持Cookie了
虽然是独立的扩展功能,但IE6以上版本等浏览器都已经支持该扩展了。另外顺带一提,该扩展并非是为了防止XSS而开发的
3、Set-Cookie2
Set-Cookie2比网景公司标准的可用属性要多。下表对这些属性做了快速汇总


Cookie2会带回与传送的每个cookie相关的附加信息,用来描述每个cookie途径的过滤器。每个匹配的cookie都必须包含来自相应Set-Cookie2首部的所有Domain、Port或Path属性
比如,假设客户端以前曾收到下列五个来自Web站点www.joes-hardware.com的Set-Cookie2响应
Set-Cookie2: ID="29046"; Domain=".joes-hardware.com" Set-Cookie2: color=blue Set-Cookie2: support-pref="L2";Domain="customer-care.joes-hardware.com" Set-Cookie2: Coupon="hammer027"; Version="1"; Path="/tools" Set-Cookie2: Coupon="handvac103"; Version="l”; Path="/tools/cordless"
如果客户端对路径/tools/cordless/specials.html又发起了一次请求,会同时发送这样一个很长的Cookie首部
Cookie: $Version="l";
ID-"29046";$Domain=".joes-hardware.com";
color="blue";
Coupon="hammer027"; $Path="/tools";
Coupon="handvac103"; $Path="/tools/cordless"
所有匹配cookie都是和它们的set-Cookie2过滤器一同传输的,而且保留关键字都是以美元符号($)开头的
4、WWW-Authenticate
WWW-Authenticate: Basic realm="Usagidesign Auth"
首部字段WWW-Authenticate用于HTTP访问认证。它会告知客户端适用于访问请求URI所指定资源的认证方案(Basic或是Digest)和带参数提示的质询(challenge)。状态码401 Unauthorized响应中,肯定带有首部字段WWW-Authenticate
上述示例中,realm字段的字符串是为了辨别请求URI指定资源所受到的保护策略
实体首部
有很多首部可以用来描述HTTP报文的负荷。由于请求和响应报文中都可能包含实体部分,所以在这两种类型的报文中都可能出现这些首部
实体首部提供了有关实体及其内容的大量信息,从有关对象类型的信息,到能够对资源使用的各种有效的请求方法。总之,实体首部可以告知报文的接收者它在对什么进行处理
下表列出了实体的信息性首部

1、Allow
Allow: GET, HEAD
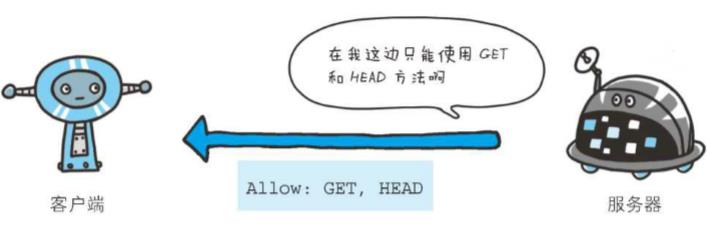
首部字段Allow用于通知客户端能够支持Request-URI指定资源的所有HTTP方法。当服务器接收到不支持的HTTP方法时,会以状态码405 Method Not Allowed作为响应返回。与此同时,还会把所有能支持的HTTP方法写入首部字段Allow后返回
2、Location
Location: http://www.usagidesign.jp/sample.html
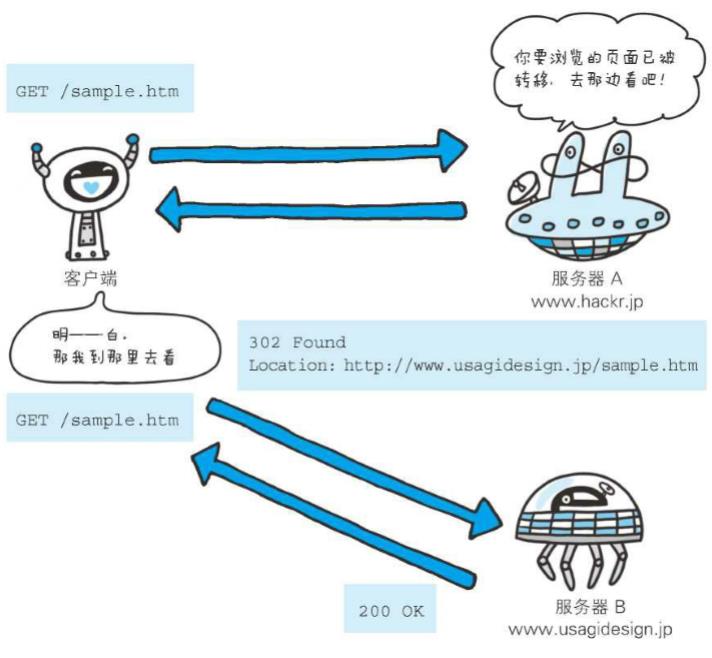
使用首部字段Location可以将响应接收方引导至某个与请求URI位置不同的资源。基本上,该字段会配合3xx:Redirection的响应,提供重定向的URI
几乎所有的浏览器在接收到包含首部字段Location的响应后,都会强制性地尝试对已提示的重定向资源的访问
【内容首部】
内容首部提供了与实体内容有关的特定信息,说明了其类型、尺寸以及处理它所需的其他有用信息。比如,Web浏览器可以通过査看返回的内容类型,得知如何显示对
下表列出了各种内容首部

[注意]RFC 2616中没有定义Content-Base首部
1、Content-Encoding
Content-Encoding: gzip

首部字段Content-Encoding会告知客户端服务器对实体的主体部分选用的内容编码方式。内容编码是指在不丢失实体信息的前提下所进行的压缩
主要采用以下4种内容编码的方式:gzip、compress、deflate、identity
2、Content-Language
Content-Language: zh-CN

首部字段Content-Language会告知客户端,实体主体使用的自然语言(指中文或英文等语言)
3、Content-Length
Content-Length: 15000
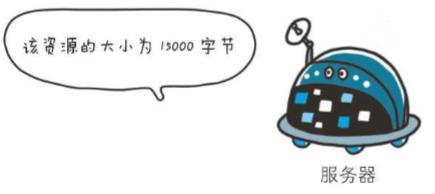
首部字段Content-Length表明了实体主体部分的大小(单位是字节)。对实体主体进行内容编码传输时,不能再使用Content-Length首部字段
4、Content-Location
Content-Location: http://www.hackr.jp/index-ja.html
首部字段Content-Location给出与报文主体部分相对应的URI。和首部字段 Location不同,Content-Location表示的是报文主体返回资源对应的URI
比如,对于使用首部字段Accept-Language的服务器驱动型请求,当返回的页面内容与实际请求的对象不同时,首部字段Content-Location内会写明URI。(访问http://www.hackr.jp/返回的对象却是http://www.hackr.jp/index-ja.html等类似情况)
5、Content-MD5
Content-MD5: OGFkZDUwNGVhNGY3N2MxMDIwZmQ4NTBmY2IyTY==
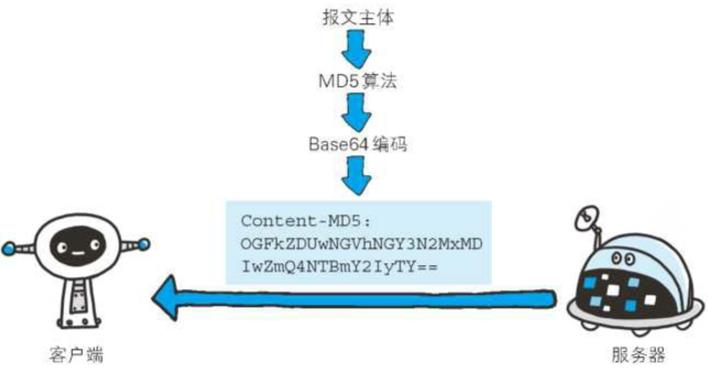
首部字段Content-MD5是一串由MD5算法生成的值,其目的在于检查报文主体在传输过程中是否保持完整,以及确认传输到达
对报文主体执行MD5算法获得的128位二进制数,再通过Base64编码后将结果写入Content-MD5字段值。由于HTTP首部无法记录二进制值,所以要通过Base64编码处理。为确保报文的有效性,作为接收方的客户端会对报文主体再执行一次相同的MD5算法。计算出的值与字段值作比较后,即可判断出报文主体的准确性
采用这种方法,对内容上的偶发性改变是无从查证的,也无法检测出恶意篡改。其中一个原因在于,内容如果能够被篡改,那么同时意味着Content-MD5也可重新计算然后被篡改。所以处在接收阶段的客户端是无法意识到报文主体以及首部字段Content-MD5是已经被篡改过的
6、Content-Range
Content-Range: bytes 5001-10000/10000
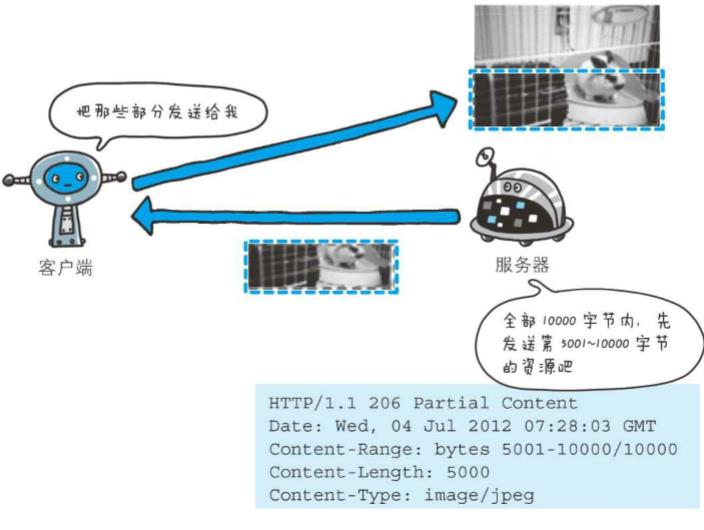
针对范围请求,返回响应时使用的首部字段Content-Range,能告知客户端作为响应返回的实体的哪个部分符合范围请求。字段值以字节为单位,表示当前发送部分及整个实体大小
7、Content-Type
Content-Type: text/html; charset=UTF-8
首部字段Content-Type说明了实体主体内对象的媒体类型。和首部字段Accept一样,字段值用type/subtype形式赋值
参数charset使用iso-8859-1或euc-jp等字符集进行赋值
【实体缓存首部】
通用的缓存首部说明了如何或什么时候进行缓存。实体的缓存首部提供了与被缓存实体有关的信息——比如,验证已缓存的资源副本是否仍然有效所需的信息,以及更好地估计已缓存资源何时失效所需的线索
下表列出了一些实体缓存首部

1、Etag
ETag: "82e22293907ce725faf67773957acd12"
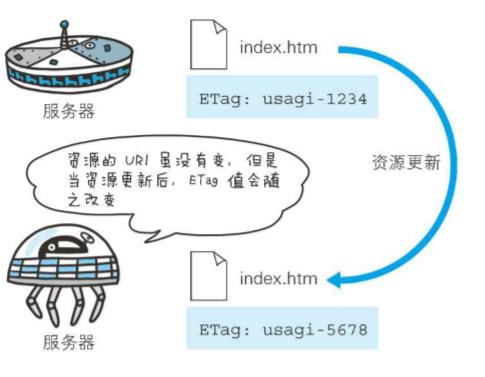
首部字段ETag能告知客户端实体标识。它是一种可将资源以字符串形式做唯一性标识的方式。服务器会为每份资源分配对应的ETag值。另外,当资源更新时,ETag值也需要更新。生成ETag值时,并没有统一的算法规则,而仅仅是由服务器来分配
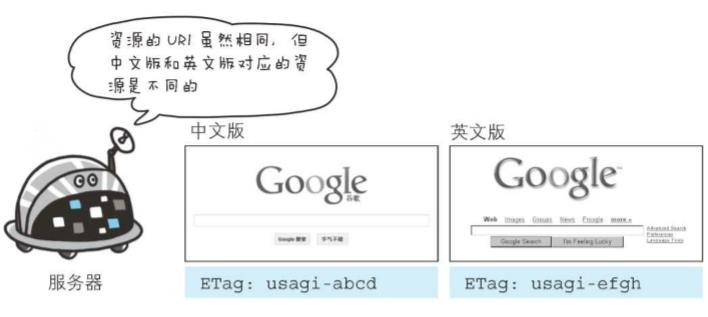
资源被缓存时,被分配唯一性标识。例如,当使用中文版浏览器访问http://www.google.com/时,就会返回中文版对应的资源,而使用英文版浏览器访问时,则会返回英文版对应的资源。两者的URI是相同的,所以仅凭URI指定缓存的资源是相当困难的。若在下载过程中出现连接中断、再连接的情况,都会依照ETag值来指定资源
ETag中有强ETag值和弱ETag值之分
强ETag值——不论实体发生多么细微的变化都会改变其值
ETag: "usagi-1234"
弱ETag值只用于提示资源是否相同。只有资源发生了根本改变,产生差异时才会改变ETag值。这时,会在字段值最开始处附加W/
ETag: W/"usagi-1234"
2、Expires
Expires: Wed, 04 Jul 2012 08:26:05 GMT
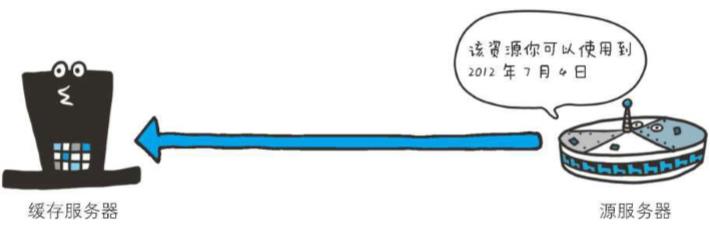
首部字段Expires会将资源失效的日期告知客户端。缓存服务器在接收到含有首部字段Expires的响应后,会以缓存来应答请求,在Expires字段值指定的时间之前,响应的副本会一直被保存。当超过指定的时间后,缓存服务器在请求发送过来时,会转向源服务器请求资源
源服务器不希望缓存服务器对资源缓存时,最好在Expires字段内写入与首部字段Date相同的时间值
但是,当首部字段Cache-Control有指定max-age指令时,比起首部字段Expires,会优先处理max-age指令
3、Last-Modified
Last-Modified: Wed, 23 May 2012 09:59:55 GMT

首部字段Last-Modified指明资源最终修改的时间。一般来说,这个值就是RequestURI指定资源被修改的时间。但类似使用CGI脚本进行动态数据处理时,该值有可能会变成数据最终修改时的时间
扩展首部
HTTP首部字段是可以自行扩展的。所以在Web服务器和浏览器的应用上,会出现各种非标准的首部字段。接下来,我们就一些最为常用的首部字段进行说明
1、X-Frame-Options
X-Frame-Options: DENY
首部字段X-Frame-Options属于HTTP响应首部,用于控制网站内容在其他Web网站的Frame标签内的显示问题。其主要目的是为了防止点击劫持(click jack ing)攻击
首部字段X-Frame-Options有以下两个可指定的字段值
DENY:拒绝
SAMEORIGIN:仅同源域名下的页面(Top-level-browsing-context)匹配时 许可。(比如,当指定http://hackr.jp/sample.html页面为SAMEORIGIN时,那么hackr.jp上所有页面的frame都被允许可加载该页面,而example.com等其他域名的页面就不行了)
能在所有的Web服务器端预先设定好X-Frame-Options字段值是最理想的状态
对apache2.conf的配置实例
<IfModule mod_headers.c>
Header append X-FRAME-OPTIONS "SAMEORIGIN"
</IfModule>
2、X-XSS-Protection
X-XSS-Protection: 1
首部字段X-XSS-Protection属于HTTP响应首部,它是针对跨站脚本攻击(XSS)的一种对策,用于控制浏览器XSS防护机制的开关
首部字段X-XSS-Protection可指定的字段值如下
0:将 XSS 过滤设置成无效状态 1:将 XSS 过滤设置成有效状态
3、DNT
DNT: 1
首部字段DNT属于HTTP请求首部,其中DNT是 Do Not Track的简称,意为拒绝
个人信息被收集,是表示拒绝被精准广告追踪的一种方法
首部字段DNT可指定的字段值如下
0:同意被追踪 1:拒绝被追踪
由于首部字段DNT的功能具备有效性,所以Web服务器需要对DNT做对应的支持
4、P3P
P3P: CP="CAO DSP LAW CURa ADMa DEVa TAIa PSAa PSDa IVAa IVDa OUR BUS IND UNI COM NAV INT"
首部字段P3P属于HTTP相应首部,通过利用P3P(The Platform for Privacy Preferences,在线隐私偏好平台)技术,可以让Web网站上的个人隐私变成一种仅供程序可理解的形式,以达到保护用户隐私的目的
要进行P3P的设定,需按以下操作步骤进行
步骤1:创建P3P隐私
步骤2:创建P3P隐私对照文件后,保存命名在w3cp3p.xml
步骤3:从P3P隐私中新建Compact policies后,输出到HTTP响应中
以上是关于前端学HTTP之报文首部的主要内容,如果未能解决你的问题,请参考以下文章