函数式编程 读书笔记
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了函数式编程 读书笔记相关的知识,希望对你有一定的参考价值。
函数式编程
函数式编程思想:在思考问题时,使用不可变值和函数,函数对一个值进行处理,映射成另一个值。
已经掌握的使用场景:
1、 获取集合中的最大或最小值,当集合类型为自定义类型时的使用比较器
2、 循环进行一些操作.foreEach( )
3、 统计符合条件的有多少个
List.stream().filter( 条件).count();
|
.map( ) : 方法将一个流中的值转换成一个新的流
|
|
.filter( ) : 方法将流进行过滤,保留符合条件的(返回为true 的结果 )
|
|
.strem( ) 方法 创建stream对象 个人理解为将对象流化
|
|
Stream.of( ) 将参数中的一组初始值变为一个新的流
|
|
.count( ) 方法计算给定 Stream 里包含多少个对象
|
|
.collect( Collectors.toList( ) ) 从 Stream 中生成一个列表 可以是toList( ), toSet( ), toMap( )
|
|
flatMap 方法可用 Stream 替换值,然后将多个 Stream 连接成一个 Stream
List<Integer> together = Stream.of(asList(1, 2), asList(3, 4)) .flatMap(numbers -> numbers.stream()) .collect(toList());
将集合 list1={1,2 } 的stream 和集合 list2={3,4 }的stream 转换为新的 stream 再通过 .collect(toList()); 将新的stream 转为一个list 集合
|
|
.max( ) .min( ) 获取一组Stream 中的最大值 获取集合中最大的值 List < Integer> mylist =Arrays.asList(10,8,7,20,5); Integer num=mylist.stream().max(Integer::compareTo).get();
获取学生集合中年龄最大的学生 List <Student> mylist = Arrays.asList(new Student(‘6,”aa”),new Stduent(20,”bb”)); Student older = mylist.stream().max(Comparator.comping(Student::getAge)).get();
|
|
|
|
|
练习代码:
package com.umuw.pigrecord.dao;
/**
* Created by Jim Calark on 2017/3/30.
*/
public class temp {
package test;
/**
* @ 描述: 练习函数式编程
* @author Jim Calark
*
*/
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collection;
import java.util.Comparator;
import java.util.HashSet;
import java.util.List;
import java.util.Map;
import java.util.Set;
import java.util.function.ToIntFunction;
import java.util.stream.Collectors;
import java.util.stream.Stream;
import org.omg.Messaging.SyncScopeHelper;
import org.w3c.dom.css.Counter;
public class test {
public static void main(String[]
args) {
/**
* 总结: 1、集合的求和、求乘积等对集合元素累积逐一操作
* 2、求最大和最小
* 3、合并集合
* 4、获取平均值
* 5、数据分块 和数据分组
* 6、计数
*/
//一、 max 和 min
.get()方法
List< Integer> nums = Arrays.asList(9,8,7,6,5);
//获取集合中的最大值
int max = nums.stream().max(Integer::compareTo).get();
List <Student> students = Arrays.asList(new Student(6,"aa"),new Student(20,"bb"));
//获取年龄最小的学生
//stream 返回一个optional 对象
// get 方法可以取出 Optional 对象中的值
Student younger=
students.stream().min(Comparator.comparing(Student::getAge)).get();
/**
* @描述: 对比
*
nums.stream().max(Integer::compareTo).get();
*
students.stream().min(Comparator.comparing(Student::getAge)).get();
* 结论: 基本数据类型 实现了 comparator 的比较方法
*/
// 二、
flatMap .collect() 方法将流转为想要的集合
//将多个集合合并为一个集合
//flatMap: 将多个流合并为一个流
//collect: 将流转为指定形式的集合
List <Integer> alltoone =
Stream.of(Arrays.asList(1,2),Arrays.asList(3,4))
.flatMap(a ->
a.stream()).collect(Collectors.toList());
//三reduce 会返回一个最终值
//求和
// reduce(param1,param2)
//param1 是和集合中第一数计算的自定义数
//param2 计算数的方法 括号中 第一个为每次计算的当前值 第二个为下一个数
int sumnumber = alltoone.stream().reduce(0,(currentsum,nextnum)->currentsum+nextnum);
//求乘积
int mulnumber =alltoone.stream().reduce(1,(currentmul,nextnum)->currentmul*nextnum);
//四、 filter
//过滤 将返回为true 的部分留下
//获取学生集合中有多少个成年人
long adualtnum = students.stream().filter(s->
s.isAdualt(s)).count();
//将学生集合中的成年人 取出为一个新的集合
List <Student> allAdualts =
students.stream().filter(s-> s.isAdualt(s)).collect(Collectors.toList());
// 五、map 如果有一个函数可以将一种类型的值转换成另外一种类型, map 操作就可以
// 使用该函数,将一个流中的值转换成一个新的流
//将字符串转换为大写的形式
// 先用map
将流的形式转换
//再用collect
将转换后的流生成一个新的集合
List<String> strs = Stream.of("a","b","c","d").map(String::toUpperCase).collect(Collectors.toList());
List<String> newStrs =Arrays.asList("a","b","c","d").stream().map(String::toUpperCase).collect(Collectors.toList());
//练习 获取班级集合中所有年级大于 18 的学生的名字
List<Student> stus = Arrays.asList(new Student(23,"小李"),new Student(13,"小杨"),new Student(29,"小钱"));
List<Grades> grades= Arrays.asList(new Grades("一班",students),new Grades("二班",stus));
List<String> stunames = grades.stream().flatMap(g ->
g.getStudents().stream())
.filter(a ->
a.getAge() >18)
.map(a ->
a.getName())
.collect(Collectors.toList());
// 获取一个班级中的人数
//注意要将班中的学生集合取出来再转为Stream 对象
count 返回的是一个long 型数据
Grades gra = new Grades("一班",students);
long num = gra.getStudents().stream().count();
// 练习 获取一个string
中的小写字母 个数
String str = new String("abcASabc");
Long lowercasenum =
str.chars().filter(Character::isLowerCase).count();
//练习 在一个字符串列表中,找出包含最多小写字母的字符串
String str2= Stream.of(str,"ccccccc","AAAA")
.max(Comparator.comparing(a->(a.chars().filter(Character::isLowerCase)).count())
)
.get();
//平均每个班级有多少学生
double aver=grades.stream().collect(Collectors.averagingInt(g
-> g.getStudents().size() ));
// 数据分块 partitioningBy
//将学生分为成年和未成年 两部分,保存在一个map集合中
//{false=[Student [age=13,
name=小杨]], true=[Student [age=23, name=小李], Student [age=29, name=小钱]]}
Map<Boolean ,List<Student>>
mumaps=
stus.stream().collect(Collectors.partitioningBy(a -> a.isAdualt(a)));
//数据分组
//找出人数最多的班级
Grades maxgrade = grades.stream().max(Comparator.comparing(g
-> g.getStudents().size())).get();
}
}
}
Lambda表达式
l 使用匿名内部类将行为和按钮单击进行关联
l 这实际上是一个代码即数据的例子——我们给按钮传递了一个代表某种行为
的对象。
button.addActionListener(new ActionListener() {
public void actionPerformed(ActionEvent event) {
System.out.println("button clicked");
}
});
l 使用 Lambda 表达式将行为和按钮单击进行关联
button.addActionListener(event -> System.out.println("button clicked"));
和传入一个实现某接口的对象不同,我们传入了一段代码块——一个没有名字的函数。
event 是参数名,和上面匿名内部类示例中的是同一个参数。 -> 将参数和 Lambda 表达式
的主体分开,而主体是用户点击按钮时会运行的一些代码。
和使用匿名内部类的另一处不同在于声明 event 参数的方式。使用匿名内部类时需要显式
地声明参数类型 ActionEvent event ,而在 Lambda 表达式中无需指定类型,程序依然可以
编译。这是因为 javac 根据程序的上下文( addActionListener 方法的签名)在后台推断出
了参数 event 的类型。这意味着如果参数类型不言而明,则无需显式指定
l 编写 Lambda 表达式的不同形式
l Runnable noArguments = () -> System.out.println("Hello World"); 形式1
ActionListener oneArgument = event -> System.out.println("button clicked");形式2
Runnable multiStatement = () -> {形式3
Lambda 表达式 |
7
System.out.print("Hello");
System.out.println(" World");
};
BinaryOperator<Long> add = (x, y) -> x + y; 形式4
BinaryOperator<Long> addExplicit = (Long x, Long y) -> x + y; 形式5
Runnable noArguments = () -> System.out.println("Hello World"); ?
?所示的 Lambda 表达式不包含参数,使用空括号 () 表示没有参数。该 Lambda 表达式实现了 Runnable 接口,该接口也只有一个 run 方法,没有参数,且返回类型为 void 。
ActionListener oneArgument = event -> System.out.println("button clicked"); ?
?中所示的 Lambda 表达式包含且只包含一个参数,可省略参数的括号,这和例 2-2 中的
形式一样。Lambda 表达式的主体不仅可以是一个表达式,而且也可以是一段代码块,使用大括号( {} )将代码块括起来,如?所示
Runnable multiStatement = () -> { ?
System.out.print("Hello");
System.out.println(" World");
};。
该代码块和普通方法遵循的规则别无二致,可以用返回或抛出异常来退出。只有一行代码的 Lambda 表达式也可使用大括号,用以明确 Lambda表达式从何处开始、到哪里结束。
Lambda 表达式也可以表示包含多个参数的方法,如?所示。
BinaryOperator<Long> add = (x, y) -> x + y; ?
这时就有必要思考怎样去阅读该 Lambda 表达式。这行代码并不是将两个数字相加,而是创建了一个函数,用来计算两个数字相加的结果。变量 add 的类型是 BinaryOperator<Long> ,它不是两个数字的和,而是将两个数字相加的那行代码。到目前为止,所有 Lambda 表达式中的参数类型都是由编译器推断得出的。这当然不错,但有时最好也可以显式声明参数类型,此时就需要使用小括号将参数括起来,多个参数的情况也是如此。如?所示。
BinaryOperator<Long> addExplicit = (Long x, Long y) -> x + y; ?
Lambda 表达式的类型依赖于上下文环境,是由编译器推断出来的
如果你曾使用过匿名内部类,也许遇到过这样的情况:需要引用它所在方法里的变量。这
时,需要将变量声明为 final ,如例 2-5 所示。将变量声明为 final ,意味着不能为其重复赋值。同时也意味着在使用 final 变量时,实际上是在使用赋给该变量的一个特定的值。
例 2-5 匿名内部类中使用 final 局部变量
final String name = getUserName();
button.addActionListener(new ActionListener() {
public void actionPerformed(ActionEvent event) {
System.out.println("hi " + name);
}
});
函数接口
函数接口是只有一个抽象方法的接口,用作 Lambda 表达式的类型
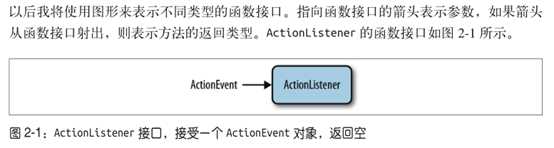

javac 根据 Lambda 表达式上下文信息就能推断出参数的正确类型。程序依然要经过类型检查来保证运行的安全性,但不用再显式声明类型罢了。这就是所谓的类型推断。
从外部迭代到内部迭代
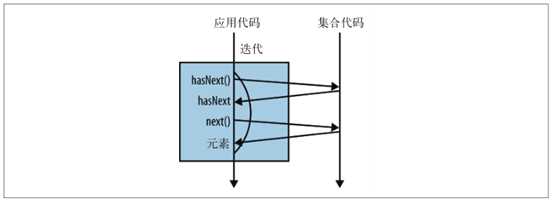
外部迭代:
使用 for 循环计算来自伦敦的艺术家人数
int count = 0;
for (Artist artist : allArtists) {
if (artist.isFrom("London")) {
count++;
}
}
迭代过程中的方法调用,对上面的代码进行展开:
使用迭代器计算来自伦敦的艺术家人数
int count = 0;
Iterator<Artist> iterator = allArtists.iterator();
while(iterator.hasNext()) {
Artist artist = iterator.next();
if (artist.isFrom("London")) {
count++;
}
}
外部迭代原理图:
内部迭代:
该方法不是返回一个控制迭代的 Iterator 对象,而是返回内部迭代中的相应接口: Stream
使用内部迭代计算来自伦敦的艺术家人数
long count = allArtists.stream()
.filter(artist -> artist.isFrom("London"))
.count();
内部迭代原理图: Stream 是用函数式编程方式在集合类上进行复杂操作的工具
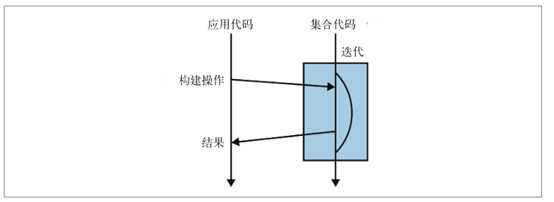
每种操作都对应 Stream 接口的一个方法。为了找出来自伦敦的艺术家,需要对 Stream 对
象进行过滤: filter 。过滤在这里是指“只保留通过某项测试的对象”。测试由一个函数完
成,根据艺术家是否来自伦敦,该函数返回 true 或者 false 。由于 Stream API 的函数式编程风格,我们并没有改变集合的内容,而是描述出 Stream 里的内容。 count() 方法计算给定 Stream 里包含多少个对象
整个过程被分解为两种更简单的操作:过滤和计数
只过滤,不计数
allArtists.stream().filter(artist -> artist.isFrom("London"));
这行代码并未做什么实际性的工作, filter 只刻画出了 Stream ,但没有产生新的集合。像
filter 这样只描述 Stream ,最终不产生新集合的方法叫作惰性求值方法;而像 count 这样
最终会从 Stream 产生值的方法叫作及早求值方法
由于使用了惰性求值,没有输出艺术家的名字
allArtists.stream().filter(artist -> {
System.out.println(artist.getName());
return artist.isFrom("London");
});
如果将同样的输出语句加入一个拥有终止操作的流,艺术家的名字就会被输出
输出艺术家的名字
long count = allArtists.stream().filter(artist -> {
System.out.println(artist.getName());
return artist.isFrom("London");
})
.count();
这里.count();会终止流的操作,所以会输出艺术家的名字
l 判断一个操作是惰性求值还是及早求值很简单:只需看它的返回值。如果返回值是 Stream ,那么是惰性求值;如果返回值是另一个值或为空,那么就是及早求值。使用这些操作的理想方式就是形成一个惰性求值的链,最后用一个及早求值的操作返回想要的结果
整个过程和建造者模式有共通之处。建造者模式使用一系列操作设置属性和配置,最后调用一个 build 方法,这时,对象才被真正创建。
常用流的操作
List<String> collected = Stream.of("a", "b", "c") 1
.collect(Collectors.toList()); 2
assertEquals(Arrays.asList("a", "b", "c"), collected); 3
首先由列表生成一个 Stream ?,然后进行一些 Stream 上的操作,继而是 collect 操作,由 Stream 生成列表?,最后使用断言判断结果是否和预期一致?。
Stream 的 of 方法使用一组初始值生成新的 Stream
使用 collect(toList()) 方法从 Stream 中生成一个列表,collect(toList()) 方法由 Stream 里的值生成一个列表,是一个及早求值操作
Map 原理:

使用 map 操作将字符串转换为大写形式
List<String> collected = Stream.of("a", "b", "hello")
.map(string ->
string.toUpperCase()) 1
.collect(Collectors.toList());
assertEquals(asList("A", "B", "HELLO"), collected);
传给 map ? 的 Lambda 表达式只接受一个 String 类型的参数,返回一个新的 String 。参数和返回值不必属于同一种类型,但是 Lambda 表达式必须是 Function 接口的一个实例
Function 接口是只包含一个参数的普通函数接口

使用 toCollection ,用定制的集合收集元素
stream.collect(toCollection(TreeSet::new));
Filter 原理图:
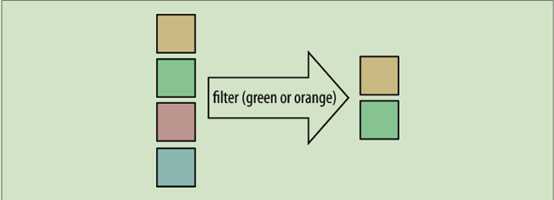
filter 模式。该模式的核心思想是保留 Stream中的一些元素,而过滤掉其他的
List<String> beginningWithNumbers
= Stream.of("a", "1abc", "abc1")
.filter(value ->
isDigit(value.charAt(0)))
.collect(Collectors.toList());
filter 接受一个函数作为参数,该函数用 Lambda 表达式表示。该函数和前面示例中 if 条件判断语句的功能一样,如果字符串首字母为数字,则返回 true 。若要重构遗留代码, for 循环中的 if 条件语句就是一个很强的信号,可用 filter 方法替代。由于此方法和 if 条件语句的功能相同,因此其返回值肯定是 true 或者 false 。经过过滤,Stream 中符合条件的,即 Lambda 表达式值为 true 的元素被保留下来。该 Lambda 表达式的函数接口正是前面章节中介绍过的 Predicate

FilterMap
flatMap 方法可用 Stream 替换值,然后将多个 Stream 连接成一个 Stream
filtermap 原理图:
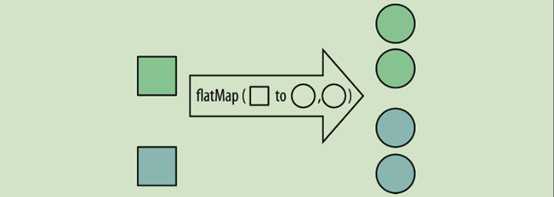
List<Integer>
together = Stream.of(asList(1, 2), asList(3, 4))
.flatMap(numbers ->
numbers.stream())
.collect(Collectors.toList());
调用 stream 方法,将每个列表转换成 Stream 对象,其余部分由 flatMap 方法处理,方法的返回值限定为 Stream 类型
max 和 min
使用 Stream 查找最短曲目
List<Track> tracks = asList(new Track("Bakai", 524),
new Track("Violets
for Your Furs", 378),
new Track("Time
Was", 451));
Track shortestTrack = tracks.stream()
.min(Comparator.comparing(track
-> track.getLength()))
.get();
为了让 Stream 对象按照曲目长度进行排序,需要传给它一个 Comparator 对象
调用空 Stream 的 max 方法,返回 Optional 对象,通过调用 get 方法可以取出 Optional 对象中的值
Track shortestTrack = tracks.get(0);
for (Track track : tracks) {
if (track.getLength() < shortestTrack.getLength()) {
shortestTrack = track;
}
}
这段代码先使用列表中的第一个元素初始化变量 shortestTrack ,然后遍历曲目列表,如果
找到更短的曲目,则更新 shortestTrack ,最后变量 shortestTrack 保存的正是最短曲目。
reduce 模式
Object accumulator = initialValue;
for(Object element : collection) {
accumulator = combine(accumulator, element);
}
首先赋给 accumulator 一个初始值: initialValue ,然后在循环体中,通过调用 combine 函
数,拿 accumulator 和集合中的每一个元素做运算,再将运算结果赋给 accumulator ,最后accumulator 的值就是想要的结果
reduce 操作可以实现从一组值中生成一个值。在上述例子中用到的 count 、 min 和 max 方法,因为常用而被纳入标准库中。事实上,这些方法都是 reduce 操作。
通过 reduce 操作对 Stream 中的数字求和。以 0 作起点——一个空流 Stream 的求和结果,每一步都将 Stream 中的元素累加至 accumulator ,遍历至 Stream 中的最后一个元素时, accumulator 的值就是所有元素的和
使用 reduce 操作实现累加原理图:
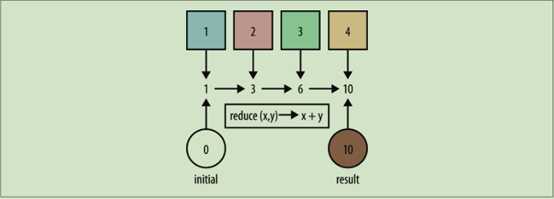
使用 reduce 求和
有两个参数:传入 Stream 中的当前元素和 acc 。将两个参数相加, acc 是累加器,保存着当前的累加结果。
int count = Stream.of(1, 2, 3)
.reduce(0, (acc, element)
-> acc + element);
展开 reduce 操作: reduce 底层代码
BinaryOperator<Integer>
accumulator = (acc, element) -> acc + element;
int count = accumulator.apply(
accumulator.apply(
accumulator.apply(0, 1),
2),
3);
实际操作例子:
问题:找出某张专辑上所有乐队的国籍。艺术家列表里既有个人,也有乐队。利用一点领域知识,假定一般乐队名以定冠词 The 开头
思路: 1. 找出专辑上的所有表演者。
2. 分辨出哪些表演者是乐队。
3. 找出每个乐队的国籍。
4. 将找出的国籍放入一个集合。
1. Album 类有个 getMusicians 方法,该方法返回一个 Stream 对象,包含整张辑中所有的
表演者;
2. 使用 filter 方法对表演者进行过滤,只保留乐队;
3. 使用 map 方法将乐队映射为其所属国家;
4. 使用 collect(Collectors.toList()) 方法将国籍放入一个列表。
Set<String> origins = album.getMusicians()
.filter(artist ->
artist.getName().startsWith("The"))
.map(artist -> artist.getNationality())
.collect(Collectors.toSet());
任何时候想转化或替代代码,都该使用 map 操作。这里将使用比 map 更复杂的 flatMap 操作,把多个Stream 合并成一个 Stream 并返回
Java 的泛型是基于对泛型参数类型的擦除——换句话说,假设它是 Object 对象的实例——
因此只有装箱类型才能作为泛型参数。这就解释了为什么在 Java 中想要一个包含整型值的
列表 List<int> ,实际上得到的却是一个包含整型对象的列表 List<Integer>
不同的函数接口有不同的方法。如果使用 Predicate ,就应该调用 test 方法,如果使用 Function ,就应该调用 apply 方法。
@FunctionalInterface 函数式接口注释
l 三定律:
默认方法的工作原理特别是在多重继承的下的行为:
1. 类胜于接口。如果在继承链中有方法体或抽象的方法声明,那么就可以忽略接口中定义的方法
2. 子类胜于父类。如果一个接口继承了另一个接口,且两个接口都定义了一个默认方法,
那么子类中定义的方法胜出。
3. 没有规则三。如果上面两条规则不适用,子类要么需要实现该方法,要么将该方法声明为抽象方法
Optional 对象
方法引用
Lambda 表达式经常调用参数。比如想得到艺术家的姓名,Lambda 的表达式如下:
artist -> artist.getName()
这种用法如此普遍,因此 Java 8 为其提供了一个简写语法,叫作方法引用,帮助程序员重
用已有方法。用方法引用重写上面的 Lambda 表达式,代码如下:
Artist::getName ;
标准语法为 Classname::methodName 。需要注意的是,虽然这是一个方法,但不需要在后面加括号,因为这里并不调用该方法
Artist::new
String[]::new
在一个有序集合中创建一个流时,流中的元素就按出现顺序排列; 如果集合本身就是无序的,由此生成的流也是无序的。 HashSet 就是一种无序的集合
收集器让流生成一个值。 maxBy 和 minBy 允许用户按某种特定的顺序生成一个值
通过调用 stream 方法让集合生成流,然后调用 collect 方法收集结果。averagingInt 方法接受一个 Lambda 表达式作参数,将流中的元素转换成一个整数,然后再计算平均数:
public double averageNumberOfTracks(List<Album> albums) {
return albums.stream().collect(averagingInt(album -> album.getTrackList().size()));
}
数据分块partitioningBy收集器:
它接受一个流,并将其分成两部分,它使用 Predicate 对象判断一个元素应该属于哪个部分,并根据布尔值返回一个 Map 到列表。因此,对于 true List 中的元素, Predicate 返回 true ;对其他 List 中的元素, Predicate 返回 false 。
原理图:

将艺术家组成的流分成乐队和独唱歌手两部分
public Map<Boolean, List<Artist>>
bandsAndSolo(Stream<Artist> artists) {
return artists.collect(partitioningBy(artist
-> artist.isSolo()));
}
使用方法引用将艺术家组成的 Stream 分成乐队和独唱歌手两部分
public Map<Boolean, List<Artist>>
bandsAndSoloRef(Stream<Artist> artists) {
return artists.collect(partitioningBy(Artist::isSolo));
}
数据分组: groupingBy 收集器
数据分组是一种更自然的分割数据操作,与将数据分成 ture 和 false 两部分不同,可以使
用任意值对数据分组。比如现在有一个由专辑组成的流,可以按专辑当中的主唱对专辑分组
使用主唱对专辑分组
public Map<Artist, List<Album>>
albumsByArtist(Stream<Album> albums) {
return albums.collect(groupingBy(album
-> album.getMainMusician()));
}
原理图:SQL 中的 group by 操作,我们的方法是和这类似的一个概念,只不过在 Stream 类库中实现了而已。
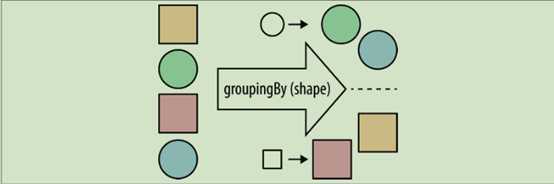
l 字符串:
使用流和收集器格式化艺术家姓名
String result =
artists.stream()
.map(Artist::getName)
.collect(Collectors.joining(", ", "[", "]"));
这里使用 map 操作提取出艺术家的姓名,然后使用 Collectors.joining 收集流中的值,该方法可以方便地从一个流得到一个字符串,允许用户提供分隔符(用以分隔元素)、前缀和后缀。
使用收集器计算每个艺术家的专辑数
只需要对专辑计数就可以了,核心类库已经提供了一个这样的收集器:counting
public Map<Artist, Long>
numberOfAlbums(Stream<Album> albums) {
return albums.collect(groupingBy(album
-> album.getMainMusician(),
counting()));
}
groupingBy 先将元素分成块,每块都与分类函数 getMainMusician 提供的键值相关联,然
后使用下游的另一个收集器收集每块中的元素
StringBuilder builder = new StringBuilder("[");
artists.stream()
.map(Artist::getName)
.forEach(name -> {
if (builder.length() > 1)
builder.append(", ");
builder.append(name);
});
builder.append("]");
String result = builder.toString();
将上面代码进行优化:
StringBuilder
reduced =
artists.stream()
.map(Artist::getName)
.reduce(new StringBuilder(), (builder, name) -> {
if (builder.length() > 0)
builder.append(", ");
builder.append(name);
return builder;
}, (left, right)
-> left.append(right));
reduced.insert(0, "[");
reduced.append("]");
String result = reduced.toString();
以上是关于函数式编程 读书笔记的主要内容,如果未能解决你的问题,请参考以下文章