ML中Boosting和Bagging的比较
Posted 耗子来啦
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ML中Boosting和Bagging的比较相关的知识,希望对你有一定的参考价值。
说到ML中Boosting和Bagging,他们属于的是ML中的集成学习,集成学习法(Ensemble Learning)① 将多个分类方法聚集在一起,以提高分类的准确率。
(这些算法可以是不同的算法,也可以是相同的算法。)
② 集成学习法由训练数据构建一组基分类器,然后通过对每个基分类器的预测进行投票来进行分类
③ 严格来说,集成学习并不算是一种分类器,而是一种分类器结合的方法。
④ 通常一个集成分类器的分类性能会好于单个分类器
⑤ 如果把单个分类器比作一个决策者的话,集成学习的方法就相当于多个决策者共同进行一项决策。
下图形象的表示了集成学习的思路
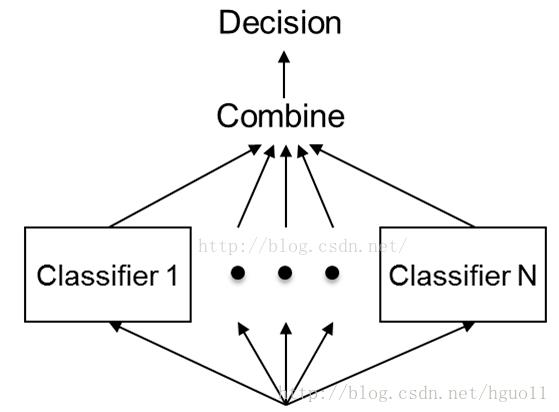
要掌握集成学习法,我们会提出以下两个问题:
1)怎么训练每个算法?
2)怎么融合每个算法?
因此,bagging方法和boosting方法应运而生
Bagging
① Bagging又叫自助聚集(BootstrapAggregating),是一种根据均匀概率分布从数据中重复抽样(有放回)的技术。
② 每个抽样生成的自助样本集上,训练一个基分类器;对训练过的分类器进行投票,将测试样本指派到得票最高的类中。
③ 每个自助样本集都和原数据一样大
④ 有放回抽样,一些样本可能在同一训练集中出现多次,一些可能被忽略。
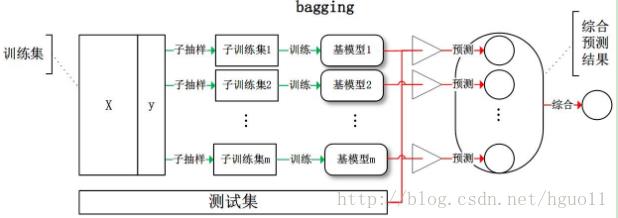
图解如上所示
例子:
X 表示一维属性,Y 表示类标号(1或-1)测试条件:当x<=k时,y=?;当x>k时,y=?;k为最佳分裂点。下表为属性x对应的唯一正确的y类别

现在进行5轮随机抽样,结果如下





每一轮随机抽样后,都生成一个分类器 然后再将五轮分类融合
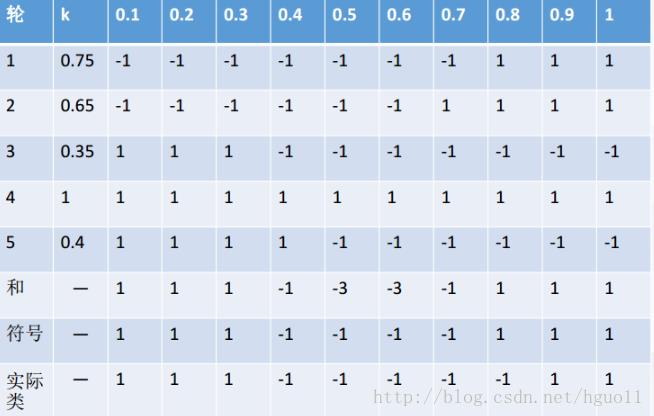
对比符号和实际类,我们可以发现:在该例子中,Bagging使得准确率可达90%
由此,总结一下bagging方法:
① Bagging通过降低基分类器的方差,改善了泛化误差
② 其性能依赖于基分类器的稳定性;如果基分类器不稳定,bagging有助于降低训练数据的随机波动导致的误差;如果稳定,则集成分类器的误差主要由基分类器的偏倚引起
③ 由于每个样本被选中的概率相同,因此bagging并不侧重于训练数据集中的任何特定实例
Boosting
训练过程为阶梯状,基模型按次序一一进行训练(实现上可以做到并行),基模型的训练集按照某种策略每次都进行一定的转化。对所有基模型预测的结果进行线性综合产生最终的预测结果:
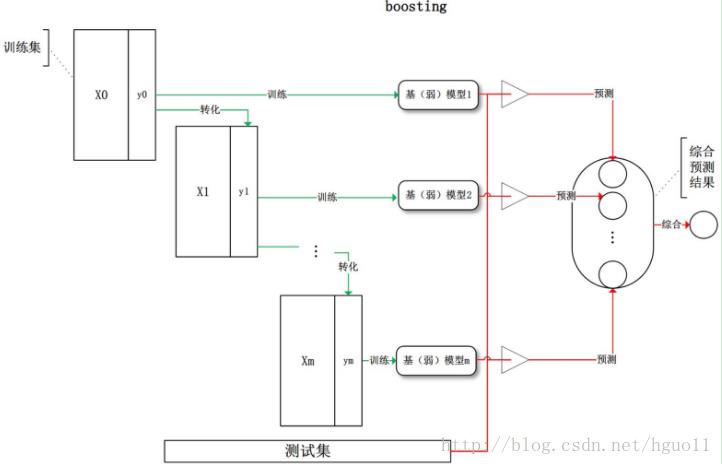
① boosting是一个迭代的过程,用于自适应地改变训练样本的分布,使得基分类器聚焦在那些很难分的样本上
② boosting会给每个训练样本赋予一个权值,而且可以再每轮提升过程结束时自动地调整权值。开始时,所有的样本都赋予相同的权值1/N,从而使得它们被选作训练的可能性都一样。根据训练样本的抽样分布来抽取样本,得到新的样本集。然后,由该训练集归纳一个分类器,并用它对原数据集中的所有样本进行分类。每轮提升结束时,更新训练集样本的权值。增加被错误分类的样本的权值,减小被正确分类的样本的权值,这使得分类器在随后的迭代中关注那些很难分类的样本。
Boosting和Bagging对比
- 模型
1)样本选择上
Bagging:训练集是在原始集中有放回选取的,从原始集中选出的各轮训练集之间是独立的。
Boosting:每一轮的训练集不变,只是训练集中每个样例在分类器中的权重发生变化。而权值是根据上一轮的分类结果进行调整。
2)样例权重:
Bagging:使用均匀取样,每个样例的权重相等
Boosting:根据错误率不断调整样例的权值,错误率越大则权重越大。
3)预测函数:
Bagging:所有预测函数的权重相等。
Boosting:每个弱分类器都有相应的权重,对于分类误差小的分类器会有更大的权重。
4)并行计算:
Bagging:各个预测函数可以并行生成
Boosting:各个预测函数只能顺序生成,因为后一个模型参数需要前一轮模型的结果。
- 偏差和方差
对于bagging来说,每个基模型的权重等于1/m且期望近似相等(子训练集都是从原训练集中进行子抽样),故我们可以进一步化简得到:
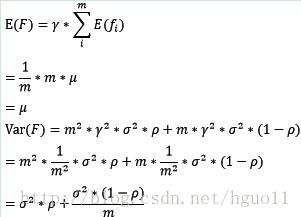
根据上式我们可以看到,整体模型的期望近似于基模型的期望,这也就意味着整体模型的偏差和基模型的偏差近似。同时,整体模型的方差小于等于基模型的方差(当相关性为1时取等号),随着基模型数(m)的增多,整体模型的方差减少,从而防止过拟合的能力增强,模型的准确度得到提高。但是,模型的准确度一定会无限逼近于1吗?并不一定,当基模型数增加到一定程度时,方差公式第二项的改变对整体方差的作用很小,防止过拟合的能力达到极限,这便是准确度的极限了。另外,在此我们还知道了为什么bagging中的基模型一定要为强模型,否则就会导致整体模型的偏差度低,即准确度低。
Random Forest是典型的基于bagging框架的模型,其在bagging的基础上,进一步降低了模型的方差。Random Fores中基模型是树模型,在树的内部节点分裂过程中,不再是将所有特征,而是随机抽样一部分特征纳入分裂的候选项。这样一来,基模型之间的相关性降低,从而在方差公式中,第一项显著减少,第二项稍微增加,整体方差仍是减少。
对于boosting来说,基模型的训练集抽样是强相关的,那么模型的相关系数近似等于1,故我们也可以针对boosting化简公式为:
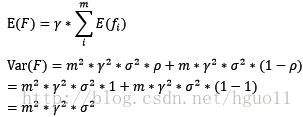
通过观察整体方差的表达式,我们容易发现,若基模型不是弱模型,其方差相对较大,这将导致整体模型的方差很大,即无法达到防止过拟合的效果。因此,boosting框架中的基模型必须为弱模型。
因为基模型为弱模型,导致了每个基模型的准确度都不是很高(因为其在训练集上的准确度不高)。随着基模型数的增多,整体模型的期望值增加,更接近真实值,因此,整体模型的准确度提高。但是准确度一定会无限逼近于1吗?仍然并不一定,因为训练过程中准确度的提高的主要功臣是整体模型在训练集上的准确度提高,而随着训练的进行,整体模型的方差变大,导致防止过拟合的能力变弱,最终导致了准确度反而有所下降。
基于boosting框架的Gradient Tree Boosting模型中基模型也为树模型,同RandomForrest,我们也可以对特征进行随机抽样来使基模型间的相关性降低,从而达到减少方差的效果。
- 其它
Bagging对样本重采样,对每一重采样得到的子样本集训练一个模型,最后取平均。由于子样本集的相似性以及使用的是同种模型,因此各模型有近似相等的bias和variance(事实上,各模型的分布也近似相同,但不独立)。bagging后的bias和单个子模型的接近,一般来说不能显著降低bias。另一方面,若各子模型独立,此时可以显著降低variance。若各子模型完全相同,则 ,此时不会降低variance。bagging方法得到的各子模型是有一定相关性的,属于上面两个极端状况的中间态,因此可以一定程度降低variance。为了进一步降低variance,Random forest通过随机选取变量子集做拟合的方式de-correlated了各子模型(树),使得variance进一步降低。(用公式可以一目了然:设有i.d.的n个随机变量,方差记为 ,两两变量之间的相关性为 ,则 的方差为 ,bagging降低的是第二项,random forest是同时降低两项。详见ESL p588公式15.1)。
boosting从优化角度来看,是用forward-stagewise这种贪心法去最小化损失函数 ,例如,常见的AdaBoost即等价于用这种方法最小化exponential loss: 。所谓forward-stagewise,就是在迭代的第n步,求解新的子模型f(x)及步长a(或者叫组合系数),来最小化 ,这里 是前n-1步得到的子模型的和。因此boosting是在sequential地最小化损失函数,其bias自然逐步下降。但由于是采取这种sequential、adaptive的策略,各子模型之间是强相关的,于是子模型之和并不能显著降低variance。所以说boosting主要还是靠降低bias来提升预测精度。
结论:bagging主要是减少variance,而boosting主要是减少bias来提升精度
参考:[1] https://www.zhihu.com/question/26760839
[2] http://blog.csdn.net/hguo11/article/details/70495671
[3] http://blog.csdn.net/lihaitao000/article/details/52058486
[4] http://m.blog.csdn.net/article/details?id=49765673
以上是关于ML中Boosting和Bagging的比较的主要内容,如果未能解决你的问题,请参考以下文章