list列表常用方法
Posted (野生程序员)
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了list列表常用方法相关的知识,希望对你有一定的参考价值。
列表是Python中常用的功能,我们知道,列表可以用来存储很多信息,掌握列表的功能有助于我们处理更多的问题,下面来看看列表都具有那些属性:
1.append(self,p_object)
def append(self, p_object): # real signature unknown; restored from __doc__
""" L.append(object) -> None -- append object to end """
pass
append(self,p_object)是向列表末尾添加元素(append object to end),向列表末尾添加元素,经常在列表转换验证的时候使用,定义一个空的列表,把一个列表中的元素遍历到空的列表中,实例如下:
>>> users = ["alex","tom","aoi","marry","kong"]
>>> names = []
>>> while users:
... name = users.pop()
... names.append(name)
...
>>> print(names)
[\'kong\', \'marry\', \'aoi\', \'tom\', \'alex\']
2.clear(self)
def clear(self): # real signature unknown; restored from __doc__
""" L.clear() -> None -- remove all items from L """
pass
clear(self)清楚列表中所有的元素,就是把一个列表中的元素情况,实例如下:
>>> users = [\'kong\', \'marry\', \'aoi\', \'tom\', \'alex\']
>>> users.clear()
>>> users
[]
下面我们来测试一个实例,我们知道Python中a = b是把a的地址关联到b上,那么清楚b的内容a会变成什么,实例如下:
>>> a = [2,34]
>>> c = a
>>> c
[2, 34]
>>> c.clear()
>>> c
[]
>>> a
[]
上面代码,我们给a定义了一个列表,然后把a列表赋给了c,清除c列表中的元素,结果a列表也变成空的了。
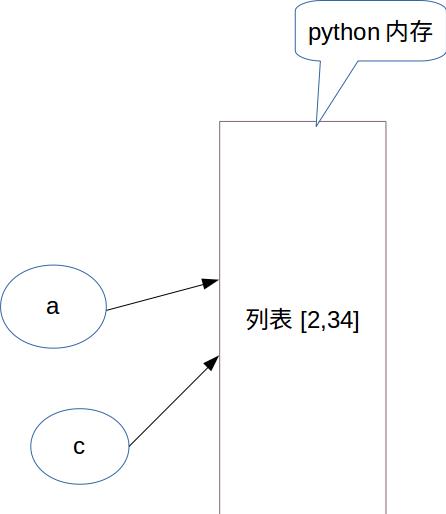
在Python中,列表是存储在内存中,相同的列表关联在同一个内存地址,清除这个列表后,这个内存地址里面的元素消失了。地址还存在,但是元素没有了,并没有开辟新的空间。因而在列表中经常使用索引,因为索引是新开辟的空间,不使用索引一不小心就会清楚原本的列表。
3.copy(self)
def copy(self): # real signature unknown; restored from __doc__
""" L.copy() -> list -- a shallow copy of L """
return []
复制列表元素,形成一个新的列表,如下:
>>> names = ["alex","sb","aoi","marry"]
>>> users = names.copy()
>>> users
[\'alex\', \'sb\', \'aoi\', \'marry\']
>>> users.clear()
>>> names
[\'alex\', \'sb\', \'aoi\', \'marry\']
>>> users
[]
copy(self)在Python中新开辟了一个空间,为什么我们不直接用users = names,因为这样只是关联到同一个地址,而copy()是新开辟了一个内存,用于存放users,users和names之间没有关联。
4.count(self,value)
def count(self, value): # real signature unknown; restored from __doc__
""" L.count(value) -> integer -- return number of occurrences of value """
return 0
count(self,value)统计元素在列表中出现的次数。如果不存在返回0,实例如下:
>>> names = [\'alex\', \'sb\', \'aoi\', \'marry\']
>>> names.count("alex")
1
>>> names.count("SB")
0
5.extend(self,iterable)
def extend(self, iterable): # real signature unknown; restored from __doc__
""" L.extend(iterable) -> None -- extend list by appending elements from the iterable """
pass
extend(self,iterable)是列表的拼接,
>>> names = [\'alex\', \'sb\', \'aoi\', \'marry\']
>>> users = ["gg","bb","ss"]
>>> names.extend(users)
>>> names
[\'alex\', \'sb\', \'aoi\', \'marry\', \'gg\', \'bb\', \'ss\']
>>> name = "ww"
>>> names.extend(name)
>>> names
[\'alex\', \'sb\', \'aoi\', \'marry\', \'gg\', \'bb\', \'ss\', \'w\', \'w\']
6.index(self,value,start=None,stop=None)
def index(self, value, start=None, stop=None): # real signature unknown; restored from __doc__
"""
L.index(value, [start, [stop]]) -> integer -- return first index of value.
Raises ValueError if the value is not present.
"""
return 0
index(self,value,start=None,stop=None)查找元素在列表中的位置索引,可以指定起始位置,实例如下:
>>> names = [\'alex\', \'sb\', \'aoi\', \'marry\', \'gg\', \'bb\', \'ss\', \'w\', \'w\', \'alex\', \'bb\', \'alex\']
>>> names.index("alex")
0
>>> names.index("bb")
5
>>> names.index("alex",2)
9
>>> names.index("Alexsb")
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: \'Alexsb\' is not in list
上面我们查找指定元素,可以指定起始位置,当元素不存在列表中的时候会报错。
7.insert(self,index,p_object)
def insert(self, index, p_object): # real signature unknown; restored from __doc__
""" L.insert(index, object) -- insert object before index """
"""向列表指定位置插入元素,index指定索引,object插入元素
pass
append(object)是向列表末尾添加元素,而insert(self,index,object)是向列表中我们指定的位置索引处插入元素,实例如下:
>>> names = [\'alex\', \'sb\', \'aoi\', \'marry\', \'bb\', \'ss\', \'alex\', \'bb\', \'alex\']
>>> names.insert(1,"is")
>>> names
[\'alex\', \'is\', \'sb\', \'aoi\', \'marry\', \'bb\', \'ss\', \'alex\', \'bb\', \'alex\']
8.pop(self,index=None)
def pop(self, index=None): # real signature unknown; restored from __doc__
"""
L.pop([index]) -> item -- remove and return item at index (default last).
Raises IndexError if list is empty or index is out of range.
"""
pass
pop(self,index=None)弹出列表中的元素,并将它赋给另外一个变量,可以指定弹出哪个位置的值(index),在遍历的时候经常结合append()一起使用,pop()是弹出元素,可以再利用弹出的元素,而remove()是删除元素,没有返回值的:实例如下:
>>> names = [\'alex\', \'is\', \'sb\', \'aoi\', \'marry\', \'bb\', \'ss\', \'alex\', \'bb\', \'alex\']
>>> name1 = names.pop()
>>> name2 = names.pop(4)
>>> name1
\'alex\'
>>> name2
\'marry\'
9.remove(self,value)
def remove(self, value): # real signature unknown; restored from __doc__
"""
删除列表中特定的值
L.remove(value) -> None -- remove first occurrence of value.
Raises ValueError if the value is not present.
"""
pass
remove(self,value)删除列表中特定的值,我们知道这个value并且删除它。实例如下:
>>> names = [\'alex\', \'is\', \'sb\', \'aoi\', \'bb\', \'ss\', \'alex\', \'bb\']
>>> names.remove("ss")
>>> names
[\'alex\', \'is\', \'sb\', \'aoi\', \'bb\', \'alex\', \'bb\']
10.reverse(self)
def reverse(self): # real signature unknown; restored from __doc__
""" L.reverse() -- reverse *IN PLACE* """
"""颠倒列表中的元素,反转列表中的元素"""
pass
reverse(self)把列表中的元素倒置,反转列表元素,实例如下:
>>> names = [\'alex\', \'is\', \'sb\', \'aoi\', \'bb\', \'alex\', \'bb\']
>>> names.reverse()
>>> names
[\'bb\', \'alex\', \'bb\', \'aoi\', \'sb\', \'is\', \'alex\']
11.sort(self,key=None,reverse=False)
def sort(self, key=None, reverse=False): # real signature unknown; restored from __doc__
""" L.sort(key=None, reverse=False) -> None -- stable sort *IN PLACE* """
pass
sort(self,key=None,reverse=False)把列表中的元素进行排序,在排序的时候也可以对列表进行导致,只需要设置reverse = True,开启导致的参数。实例如下:
>>> names = [\'bb\', \'alex\', \'bb\', \'aoi\', \'sb\', \'is\', \'alex\']
>>> names.sort()
>>> names
[\'alex\', \'alex\', \'aoi\', \'bb\', \'bb\', \'is\', \'sb\']
>>> names.sort(reverse=True)
>>> names
[\'sb\', \'is\', \'bb\', \'bb\', \'aoi\', \'alex\', \'alex\']
上面代码可以看出,进行排序之后列表有进行倒置。
12.__add__(self,*args,**kwargs)
def __add__(self, *args, **kwargs): # real signature unknown
""" Return self+value. """
"""两个列表进行拼接"""
pass
__add__(self,*args,**kwargs)两个列表的元素相加,实例如下:
>>> names = [\'sb\', \'is\', \'bb\', \'bb\', \'aoi\', \'alex\', \'alex\']
>>> li = [11,22]
>>> names.__add__(li)
[\'sb\', \'is\', \'bb\', \'bb\', \'aoi\', \'alex\', \'alex\', 11, 22]
>>> names
[\'sb\', \'is\', \'bb\', \'bb\', \'aoi\', \'alex\', \'alex\']
>>> names.extend(li)
>>> names
[\'sb\', \'is\', \'bb\', \'bb\', \'aoi\', \'alex\', \'alex\', 11, 22]
我们知道,两个列表的元素拼接可以使用extend(self,list),使用extend()拼接之后,原来的列表发生了变化,是把元素添加到原来的列表中,而__add__(self,*args,**kwargs)是新生成了一个列表,并不修改原来列表中的值,我们在使用的时候要看不改变原来的列表还是改变原来的列表。
13.__contains__(self,*args,**kwargs)
def __contains__(self, *args, **kwargs): # real signature unknown
""" Return key in self. """
pass
__contains__(self,*args,**kwargs)判断列表中是否包含指定的元素,实例如下:
>>> names = [\'sb\', \'is\', \'bb\', \'bb\', \'aoi\', \'alex\', \'alex\', 11, 22]
>>> names.__contains__("alex")
True
>>> names.__contains__("TOM")
False
14.__delitem__(self,*args,**kwargs)
def __delitem__(self, *args, **kwargs): # real signature unknown
""" Delete self[key]. """
pass
__delitem__(self,*args,**kwargs)删除列表中某个元素,相当于del self[key],实例如下:
>>> names = [\'sb\', \'is\', \'bb\', \'bb\', \'aoi\', \'alex\', \'alex\', 11, 22]
>>> names.__delitem__(0)
>>> del names[0]
>>> names
[\'bb\', \'bb\', \'aoi\', \'alex\', \'alex\', 11, 22]
15.__eq__(self,value)
def __eq__(self, *args, **kwargs): # real signature unknown
"""__eq__(self,value)等价于判断 self == value,判断是否与要求的数字相等"""
""" Return self==value. """
pass
__eq__()是中的eq是单词equal的缩写,equal是相等的意思,判断两个数字是否相等。如下:
16.__ne__(self,value)
def __ne__(self, *args, **kwargs): # real signature unknown
"""判断两个数字是否不想等,如果不想等返回True;否则返回布尔值False."""
""" Return self!=value. """
pass
判断两个数字是否相等,相等返回True,否则返回False。__ne__(self,value)是单词not equal的缩写,表示不等于的
含义,下面我会进行总结:
17.__ge__(self,value)
def __ge__(self, *args, **kwargs): # real signature unknown
"""__ge__(self,value)是用来判断self>=value,如果self大于等于要比较的value值,则返回布尔值True,否则返回
False"""
""" Return self>=value. """
pass
__ge__(self,value)是大于等于的含义,比较self>=value,ge是单词greater than or equal to的缩写,表示大于等于:
判断如下:
18.__gt__(self,value)
def __gt__(self, *args, **kwargs): # real signature unknown
"""__gt__(self,value)判断self是否大于给定的值value"""
""" Return self>value. """
pass
判断self是否大于给定的值value,如果大于返回True;否则返回Fasle.__gt__(self,value)中的ge是单词greater than的
缩写,表示大于。
19.__le__(self,value)
def __le__(self, *args, **kwargs): # real signature unknown
"""__le__(self,value)判断self <= value,如果条件成立返回True,否则返回False."""
""" Return self<=value. """
pass
__le__(self,value)是用于判断self是否小于等于value的,如果成立返回True;否则返回False.__le__(self,value)中le是
单词less than equal的缩写,函数是小于等于。
20.__lt__(self,value)
def __lt__(self, *args, **kwargs): # real signature unknown
"""用于判断self<value是否成立"""
""" Return self<value. """
pass
__lt__(self,value)是用来判断self是否小于给定值value,如果条件成立,则返回True;否则返回False。__lt__中lt是单
词less than的缩小,表示小于,用来比较一个数是否小于另外一个数,实例如下:
下面总结了int类中几种相似的方法,以及简写和单词含义,可以帮助我们进行记忆: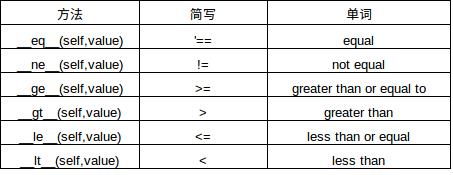
21.__getattribute__(self,*args,**kwargs)
def __getattribute__(self, *args, **kwargs): # real signature unknown
""" Return getattr(self, name). """
pass
22.__getitem__(self,y)
def __getitem__(self, y): # real signature unknown; restored from __doc__
""" x.__getitem__(y) <==> x[y] """
pass
__getitem__(self,y)获取列表中指定位置索引的值,等价于x[y],示例如下:
>>> names = [\'bb\', \'bb\', \'aoi\', \'alex\', \'alex\', 11, 22]
>>> names.__getitem__(2)
\'aoi\'
>>> names[2]
\'aoi\'
23.__iadd__(self,*args,**kwargs)
def __iadd__(self, *args, **kwargs): # real signature unknown
""" Implement self+=value. """
pass
__iadd__(self,*args,**kwargs)两个列表的合并,把另外一个列表中的值添加到原列表中,等价于extend()方法,实例如下:
>>> names = [\'bb\', \'bb\', \'aoi\', \'alex\', \'alex\']
>>> li = [11, 22]
>>> names.__iadd__(li)
[\'bb\', \'bb\', \'aoi\', \'alex\', \'alex\', 11, 22]
>>> names
[\'bb\', \'bb\', \'aoi\', \'alex\', \'alex\', 11, 22]
我们上面了解过__add__()是生成一个新的列表,并不改变原来的列表,而__iadd__()是把另外一个列表中的元素添加到列表中,与extend()方法类似,改变了列表的元素值。
24.__imul__(self,*args,**kwargs)
def __imul__(self, *args, **kwargs): # real signature unknown
""" Implement self*=value. """
pass
25.__init__(self,seq=())
def __init__(self, seq=()): # known special case of list.__init__
"""
list() -> new empty list
list(iterable) -> new list initialized from iterable\'s items
# (copied from class doc)
"""
pass
__init__(self,seq=())是类中的方法,在类中经常使用。
26.__iter__(self,*args,**kwargs)
def __iter__(self, *args, ** 以上是关于list列表常用方法的主要内容,如果未能解决你的问题,请参考以下文章