lucene中文分词搜索的核心代码
Posted 编世界
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了lucene中文分词搜索的核心代码相关的知识,希望对你有一定的参考价值。
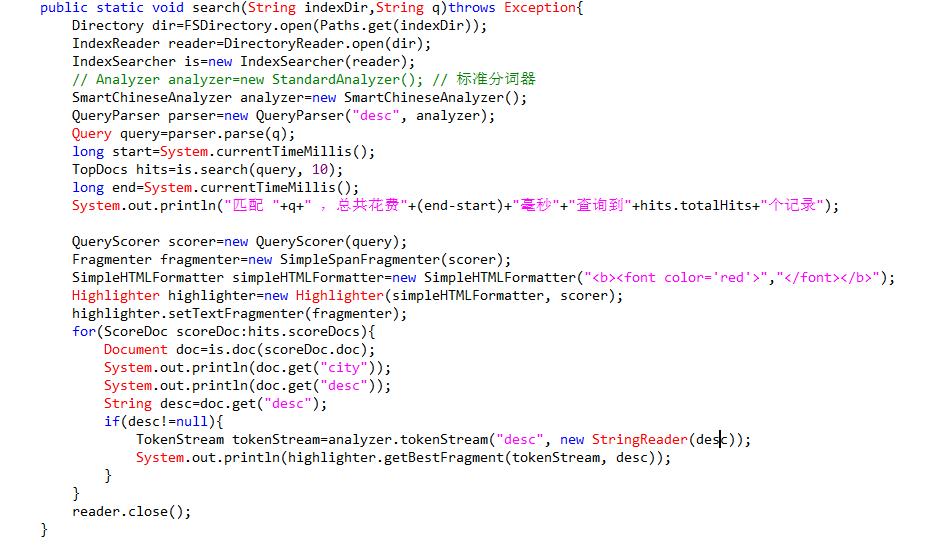
public static void search(String indexDir,String q)throws Exception{ Directory dir=FSDirectory.open(Paths.get(indexDir)); IndexReader reader=DirectoryReader.open(dir); IndexSearcher is=new IndexSearcher(reader); // Analyzer analyzer=new StandardAnalyzer(); // 标准分词器 SmartChineseAnalyzer analyzer=new SmartChineseAnalyzer(); QueryParser parser=new QueryParser("desc", analyzer); Query query=parser.parse(q); long start=System.currentTimeMillis(); TopDocs hits=is.search(query, 10); long end=System.currentTimeMillis(); System.out.println("匹配 "+q+" ,总共花费"+(end-start)+"毫秒"+"查询到"+hits.totalHits+"个记录"); QueryScorer scorer=new QueryScorer(query); Fragmenter fragmenter=new SimpleSpanFragmenter(scorer); SimplehtmlFormatter simpleHTMLFormatter=new SimpleHTMLFormatter("<b><font color=\'red\'>","</font></b>"); Highlighter highlighter=new Highlighter(simpleHTMLFormatter, scorer); highlighter.setTextFragmenter(fragmenter); for(ScoreDoc scoreDoc:hits.scoreDocs){ Document doc=is.doc(scoreDoc.doc); System.out.println(doc.get("city")); System.out.println(doc.get("desc")); String desc=doc.get("desc"); if(desc!=null){ TokenStream tokenStream=analyzer.tokenStream("desc", new StringReader(desc)); System.out.println(highlighter.getBestFragment(tokenStream, desc)); } } reader.close(); }
以上是关于lucene中文分词搜索的核心代码的主要内容,如果未能解决你的问题,请参考以下文章