TensorFlow_Fold深度探究 Blocks for Composition
Posted 糖果天王
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了TensorFlow_Fold深度探究 Blocks for Composition相关的知识,希望对你有一定的参考价值。
0xFF 未完工说明
Composition某种意义上可以说是基本、核心的一部分,打算一点点慢慢写,无奈Src有点多,我想继续边看边思考,敬请原谅~o(∩_∩)o~
【当前进度 89%】
0x00 前言
想写点东西试试,结果接下来就老老实实躺在了Pipeline上;
决定学跑之前先学爬,老老实实啃一下源码和官方文档,虽然官方还在一点点更新,不少地方还是空白的,不过先动起来多敲点试试看,老等着别人喂饭多不好呀(对呀我也觉得连前言都要重复我真的好懒呀23333);
TFF的基本单位之一是Block,看了下Markdown的结构,个人打算按照这个顺序来看看:
-> Blocks for input -> (Done)♪(^∀^●)ノ
-> Blocks for composition
-> Blocks for tensors
-> Blocks for sequences
-> Other blocks
-> Primitive blocks
-> Block composition
虽说……列完表就有想弃坑的冲动,不过毕竟万事开头难嘛,一个一个来,那下一件事就来看看Blocks4Composition好了。
Reference
- Blocks for Input 官方文档出处
- Blocks 的官方解释及示例Markdown
- Source : TensorFlow_Fold / Python Blocks API
- Source Code : Github / blocks.py
About Block_Info()
因为在探究block,所以时不时看看block的类型以及输入输出是必要的,代码中会常使用block_info()函数来查询与验证。
如果没有特殊说明,block_info()函数指代TFF官方代码里的block描述函数,如下:
# Function for describe blocks
def block_info(block):
print("%s: %s -> %s" % (block, block.input_type, block.output_type))About times_scalar_block()
这一次要学的大约都是块和块,啊不对block和block之间的关系,所以为了偷懒先事先准备一个block放着,后面直接以这个block来举例说明。
这个block是以time_scalar_block(n)函数接受传参,传入的值即输出的block的倍率,如time_scalar_block(3)则返回一个令输入值乘以三输出的block(严格来说这个其实应该是个fn,毕竟是个td.Function()…)。
import functools
def times_scalar_block(n):
return td.Function(functools.partial(tf.multiply, n))0x01 td.Composition()
说明文档
class td.Composition
A composition of blocks, which are connected in a DAG.
td.Composition.init(children=None, name=None)
td.Composition.connect(a, b)
Connect a to the input of b.
The argument a can be either:
A block, in which case the output of a is fed into the input of b.
The i^th output of a block, obtained from a[i].
A tuple or list of blocks or block outputs.
A td.Composition block allows the inputs and outputs of its children to be wired together in an arbitrary DAG.
Testing
说到Composition,我就开始头疼了,虽说就是个连接操作……但是越是这种最基础的东西,底层越麻烦。
哇哦,这些test写的真的好…… 感觉在纸上随便画画就理解不少了,oh,我突然有个好点子,反正连接使用的地方那么广,测试code怕是也特别多,要不然这一节直接用blocks_test里的代码来讲吧~
入门篇:PyObject连接
def test_pyobject_composition(self):
block = tdb.AllOf(tdb.Identity(), tdb.Identity())
self.assertBuildsConst(('foo', 'foo'), block, 'foo')
block = (tdb.AllOf(tdb.Identity(), tdb.Identity()) >>
(tdb.Scalar(), tdb.Scalar()))
self.assertBuilds((42.0, 42.0), block, 42, max_depth=None)既然决定了要带大家看代码的形式来理解,那第一个函数就多说一点,讲一下这些看上去高大上的东西的意思好啦。
这里的tdb 指的是td,好的抬走下一个;
self.assertBuilds(a, block, b, [others...])
这个是一个测试函数,可以理解为“我把b扔进block里,输出的是a吗?”,鉴于这是一个验证函数正确性的code,所以我们可以默认这个文件中的这个函数另一个角度实际是告知我们“你们把b作为输入传给block,输出的是a”;
以这一段为例:
block 为
td.AllOf(td.Identity(), td.Identity()) >> (td.Scalar(), td.Scalar())
在这个block中,只有一个>>,
左侧为: td.AllOf(td.Identity(), td.Identity())
右侧为:(td.Scalar(), td.Scalar())
td.AllOf 也是当前节会介绍的东西,简单来说的话就是,对于其中的每一个都做一件事(微歧义,后面会说明):
# A block that runs all of its children (conceptually) in parallel.
AllOf().eval(inp) => None
AllOf(a).eval(inp) => (a.eval(inp),)
AllOf(a, b, c).eval(inp) => (a.eval(inp), b.eval(inp), c.eval(inp))详细的请拉到本篇较后面的位置寻找或者直接Ctrl+F寻找td.AllOf()
By the way, 这里的td.Identity()之前没有介绍过,贴一条一句话解释:
class td.Identity
A block that merely returns its input.
于是这一段test_pyobject_composition则是:
对于Python_Object的Composition操作测试,是否可以简单地将PyObject类型使用>>连接成为pipeline,将输入的值复制为2份,传给一个包含两个td.Scalar的tuple,示例中,输入42,输出(42.0, 42.0)。
基础篇:Function连接
def test_function_composition(self):
sc = tdb.Scalar()
fn1 = times_scalar_block(2.0)
c = sc >> fn1
self.assertBuilds(42., c, 21)
def test_function_composition_with_block(self):
c = tdb.Composition()
with c.scope():
scalar = tdb.Scalar().reads(c.input)
c.output.reads(times_scalar_block(2.0).reads(scalar))
self.assertBuilds(42., c, 21)上述均是目标为function的连接,所以放在一起看一看~
首先,times_scalar_block文首已经提及过啦,你们肯定都记……好吧不见得你们还记得,再说一次:
import functools
def times_scalar_block(n):
return td.Function(functools.partial(tf.multiply, n))首先解释一下c.scope(),简而言之,就是说c(c = td.Composition())是一个里面有很多小block的大block,“在c里面,我们有blablabla”就是with c.scope():的意思了。
我们需要知道的是,等我们构建完毕之后,c.input是c的输入,同时也是c中与c.input相连的block的输入,同理,与c.output相连的输出即c的输出。
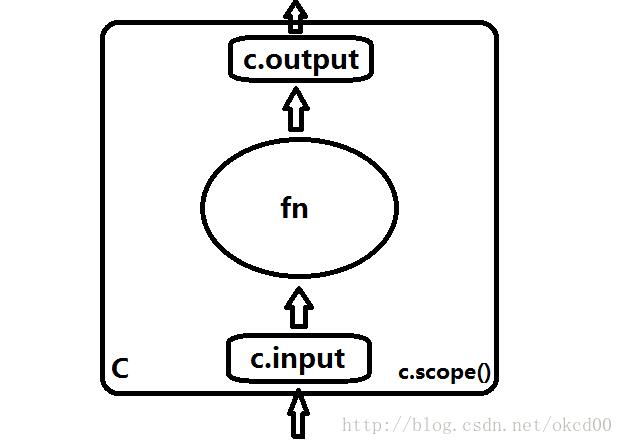
再解释一下.read(),对于一个block而言, blockX.read(blockA)与c.connect(blockA, blockX)是同样的效果,并且.read()函数仅能在scope的范围中使用。我们可以在scope中使用.connect()或是.read()来为blocks连边,从而构建一个DAG(有向无环图)的计算图。
以这两段代码为例,可以看作效果是相同的,都是将输入值传给td.Scalar(),然后连到乘以二的Block上,最后连向输出。可以仔细观察一下这些操作,是block连接的基础或者说基本,不同的是后者使用td.Composition来创建block,并在scope中进行的连接操作。
同样是Function连接,下面讲一下使用lambda快速构造Function:
def test_function_tuple_in_out(self):
# f(a, (b, c)) := ((c, a), b)
b = ((tdb.Vector(1), (tdb.Vector(2), tdb.Vector(3))) >>
tdb.Function(lambda x, y: ((y[1], x), y[0])))
self.assertBuilds((([4., 5., 6.], [1.]), [2., 3.]), b,
([1], ([2, 3], [4, 5, 6])))
def test_function_raises(self):
self.assertRaisesWithLiteralMatch(
TypeError, 'tf_fn is not callable: 42', tdb.Function, 42)td.Function.__init__(tf_fn, name=None, infer_output_type=True)
关于td.Function(),严格上来说应该属于Blocks for tensors的内容,在这里我们只需要知道:
这个函数可以把传入的函数转化为block的形式,特别地,传入的函数需要是TITO(Tensor In, Tensor Out)的,infer_output_type参数与占位符有关,本篇不予多加评论。
(我写到这里才领悟过来,啊原来这个test是用来测试td.Function()的呀,算了不管了等我写到那一篇再贴过去,再说了就算只是为了描述Function连接,多举个例子总是好的)
在这个例子中,我们可以看到,输入(a,(b,c)),输出((a,b),c),这个block的实现只需要简单的td.Function(lambda x, y: ((y[1], x), y[0])))就可以了。
而这里需要尤其注意!td.Function与td.InputTransform不同,后者输入输出都是PyObject,前者输入输出都是TensorType,在这里非常容易遇见TypeError哦!
小贴士:为了防止被海量的TypeError烦的一拳打穿电脑,推荐每写一个block,用block_info看一眼输入输出的数据类型,类型对上了再连接。
进阶篇:运算图分叉(Diamond形运算图的连接)
def test_composition_diamond(self):
sc = tdb.Scalar()
fn1 = times_scalar_block(2.0)
fn2 = times_scalar_block(3.0)
fn3 = tdb.Function(tf.add)
# out = in*2 + in*3
c = tdb.Composition([sc, fn1, fn2, fn3])
c.connect(c.input, sc)
c.connect(sc, fn1)
c.connect(sc, fn2)
c.connect((fn1, fn2), fn3)
c.connect(fn3, c.output)
self.assertBuilds(25., c, 5, max_depth=2)
def test_composition_diamond_with_block(self):
# out = in*2 + in*3
c = tdb.Composition()
with c.scope():
scalar = tdb.Scalar().reads(c.input)
fn1 = times_scalar_block(2.0).reads(scalar)
fn2 = times_scalar_block(3.0).reads(scalar)
c.output.reads(tdb.Function(tf.add).reads(fn1, fn2))
self.assertBuilds(25., c, 5, max_depth=2)
def test_composition_nested(self):
fn1 = times_scalar_block(2.0)
fn2 = times_scalar_block(3.0)
c = tdb.Composition([fn1, fn2])
c.connect(c.input, fn1)
c.connect(c.input, fn2)
c.connect((fn1, fn2), c.output)
c2 = tdb.Scalar() >> c >> tdb.Function(tf.add)
self.assertBuilds(5.0, c2, 1.0, max_depth=2)上述是我称之为Diamond类型的连接,那么什么是Diamond呢?
灵魂画手参上:
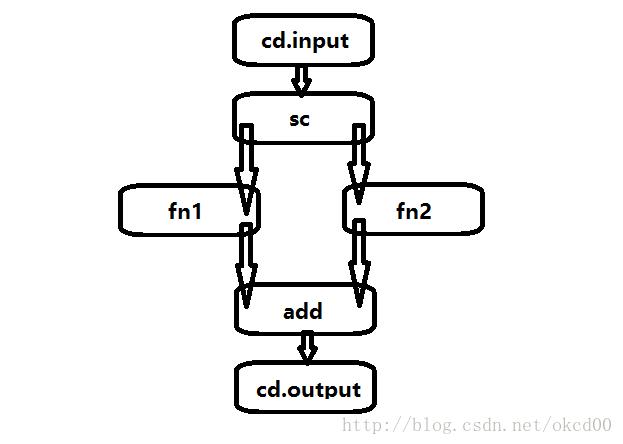
为了实现一个有类似Diamond分叉的计算图,其艰难困苦程度一言以蔽之:
“TypeError:二货点你给我走远点我不想再看到你!”
调试许久,最终方案A&B如下:
cd = td.Composition()
with cd.scope():
fn1 = (td.GetItem(0)).reads(cd.input)
fn2 = (td.GetItem(1)).reads(cd.input)
h1 = (td.InputTransform(lookup) >> td.Vector(2)).reads(fn1)
h2 = (td.InputTransform(lookup) >> td.Vector(2)).reads(fn2)
cd.output.reads(td.Concat().reads(h1, h2))
block_info(cd) # => <td.Composition>: None -> TensorType((4,), 'float32')
cd.eval([1,2,'a',4]) # => array([2., 1., 3., 2.], dtype=float32) cd = td.Composition()
with cd.scope():
fn1 = td.GetItem(0)
fn2 = td.GetItem(1)
h1 = td.InputTransform(lookup) >> td.Vector(2)
h2 = td.InputTransform(lookup) >> td.Vector(2)
cc = td.Concat()
cd2.connect(cd2.input, fn1)
cd2.connect(cd2.input, fn2)
cd2.connect(fn1, h1)
cd2.connect(fn2, h2)
cd2.connect((h1, h2), cc)
cd2.connect(cc, cd2.output)
block_info(cd) # => <td.Composition>: None -> TensorType((4,), 'float32')
cd.eval([1,2,'a',4]) # => array([2., 1., 3., 2.], dtype=float32) 哇,单单这一个小任务就把我debug得心力交瘁,我只是想让运算图分个叉而已呀,真不容易。
感觉这一篇不知道啥时候才能写完,我决定,先把我悲惨的Diamond调试过程拎出来单独开一篇写了去
=> 【传送门:《计算图连接初探 Diamond计算图调试历程》】
进阶篇:scope嵌套
def test_composition_nested_with_block(self):
c1 = tdb.Composition()
with c1.scope():
scalar = tdb.Scalar().reads(c1.input)
c2 = tdb.Composition().reads(scalar)
with c2.scope():
fn1 = times_scalar_block(2.0).reads(c2.input)
fn2 = times_scalar_block(3.0).reads(c2.input)
c2.output.reads(fn1, fn2)
c1.output.reads(tdb.Function(tf.add).reads(c2))
self.assertBuilds(5.0, c1, 1.0, max_depth=2)番外篇:运算图拓扑
对于一个顺序七零八落的td.Composition([fn4, fn3, fn0, fn2, fn1])
我们按照如下的顺序将他们连接起来:
input -> fn0
fn0 -> fn1
fn0 -> fn2
fn2 -> fn3
fn1&fn3 -> fn4
fn4 -> output
def test_composition_toposort(self):
fn0 = tdb.Scalar()
fn1 = times_scalar_block(2.0)
fn2 = times_scalar_block(3.0)
fn3 = times_scalar_block(1.0)
fn4 = tdb.Function(tf.add)
c = tdb.Composition([fn4, fn3, fn0, fn2, fn1])
c.connect(c.input, fn0)
c.connect(fn0, fn1)
c.connect(fn0, fn2)
c.connect(fn2, fn3)
c.connect((fn1, fn3), fn4)
c.connect(fn4, c.output)
self.assertBuilds(5.0, c, 1.0, max_depth=3)
def test_composition_toposort_output(self):
block = tdb.Composition()
with block.scope():
s = tdb.Scalar('int32').reads(block.input)
block.output.reads(s, s)
self.assertBuildsConst((3, 3), block, 3)不用在意其原先的先后顺序,Composition会自动按照他们之间的联系得出这个DAG的流从哪里开始一步一步向下走,先前我在一则文章中看到:
给图中的每一个节点(操作)标注一个深度,所有没有任何依赖的节点标注为深度0,依赖的节点深度最大为d的节点的深度标注为d+1;在图中插入pass-through(直通)的操作,使得第d+1层只依赖于第d层;将同一深度涉及相同操作的节点合并到一起,方便并行计算;将同一深度的计算结果按Tensor类型(包括Tensor的形状和数值类型)有序拼接在一起;将输入原始计算图中的每条边标记上(深度,数据类型,序号),对应它们可以获取上一层计算结果的位置。
对于一批不同结构的计算图,我们可以把它们看做不连通的大图同样处理。上面算法的第三步会将这批图中同一深度的相同操作进行合并,方便并行计算。说完图的构建,我们再说说怎么执行:算法在每次迭代中执行一个深度的计算,使用tf.while_loop从深度0一直执行到最大深度。在每一个深度中,tf.gather根据上面第五步的标记为各个Operation获取当前深度各条输入边的Tensor,如果某个Operation没有获取到任何Tensor,说明当前深度这个Operation不需要执行计算。Operation执行完后tf.concat将相同Tensor类型的计算结果拼接在一起,提供给下一个深度的计算。

上面这一幅图来着官方论文,左边是Dynamic Batching为二叉TreeRNN构建的通用计算图。右边是一颗简单的语法解析树。通用计算图中有两种Tensor,代表单词的编码整数、词向量/hidden向量的128维向量。Operation也只有两个一个词向量查表操作(embed lookup)和一个RNN的Cell。图中gather和concat之间的直连表示直通(pass-through)操作。右边的语法解析树可以分为三层计算被执行:第一层,将1、3、5通过词向量查表操作,输出3个128维的词向量;第二层,1和3对应的词向量通过RNN Cell输出一个128维的隐含层向量,5对应的词向量直通输出;第三层,上一层计算的隐含层向量和5对应的词向量通过RNN Cell,输出一个128维的隐含层向量。计算完毕。
后传篇:连接过程中需要注意的错误
TypeError
最常见的错误,输入输出记得要统一数据类型呀……
话虽这么说,我也在这里头疼了真的很久,到现在还没绕明白,等我哪天弄明白了,写个Fold的Type解说章好了……
- PyObject
- TensorType
- TupleType
- SequenceType (2017 Apr.21:又出现一种Type,烦躁不已瞬间爆炸,特此记录)
def test_composition_connect_raises(self):
self.assertRaises(TypeError, tdb.Pipe, tdb.Scalar(), tdb.Concat())ValueError: have Cycles
DAG,来跟我念,有向无环图,好的,记住别连成环了。
def test_composition_raises_cycle(self):
fn1 = times_scalar_block(2.0)
fn2 = times_scalar_block(3.0)
c = tdb.Composition([fn2, fn1]).set_input_type(tdt.VoidType())
c.connect(fn1, fn2)
c.connect(fn2, c.output)
c.connect(fn2, fn1) # cycle
self.assertRaisesWithLiteralMatch(
ValueError, 'Composition cannot have cycles.', c._validate, None)TypeError: Unused
我也常犯类似的错误……写了半天有几个block给忘记了,这就是scope中有的小block的输出没有被使用的错误,而Fold中这种问题并不是Warning,而是Error并无法继续执行,所以代码习惯不太好的同学这里要注意啦。
def test_composition_raises_unused(self):
fn0 = tdb.Scalar()
fn1 = times_scalar_block(2.0)
c = tdb.Composition([fn1, fn0])
c.connect(c.input, fn0)
c.connect(fn0, fn1)
c.connect(fn0, c.output)
six.assertRaisesRegex(
self, TypeError, 'children have unused outputs: .*', c._validate, None)ValueError: is already connected
这个也很常见,不过我觉得这里在设计上确实需要想想办法改进一下,一旦某一个block被连接,那么它下一次被连接的时候就会报错double_connect,对于我们这种用ipython或者jupyter notebook的coder感觉就很不友好,因为我们就算敲错了都会在内存里一直在,有时甚至需要kill掉当前kernel才可以……
不过,基于DAG的理念及其底层的实现,这样的check是必要甚至必需的,大家在coding的时候也要尤为注意这一点才行。
def test_composition_raises_double_connect(self):
a = tdb.Scalar()
c = tdb.Composition([a])
c.connect(c.input, a)
self.assertRaisesWithLiteralMatch(
ValueError,
'input of block is already connected: <td.Scalar dtype=\\'float32\\'>',
c.connect, c.input, a)
def test_composition_raises_double_connect_output(self):
a = tdb.Scalar()
b = tdb.Scalar()
c = tdb.Composition([a, b])
c.connect(a, c.output)
self.assertRaisesWithLiteralMatch(
ValueError,
'input of block is already connected: <td.Composition.output>',
c.connect, b, c.output)TypeError:bad i/o type
本质上与之前的TypeError报错没有什么区别,是输入输出数据类型不对的另一种特例,即输出不能为VoidType以及对于输入要求非PyObject的block输入不能为PyObject。
def test_composition_backward_type_inference(self):
b = tdb._pipe([tdb.Map(tdb.Identity()), tdb.Identity(), tdb.Identity()])
six.assertRaisesRegex(
self, TypeError, 'bad output type VoidType',
b.output.set_output_type, tdt.VoidType())
def test_composition_forward_type_inference(self):
b = tdb._pipe([tdb.Identity(), tdb.Identity(),
tdb.Map(tdb.Function(tf.negative))])
six.assertRaisesRegex(
self, TypeError, 'bad input type PyObjectType',
b.input.set_input_type, tdt.PyObjectType())
备用篇:不知道在干什么,以后再回来看
主要是……星号(大概是指针吧)在这里是干啥的……
def test_composition_slice(self):
c1 = tdb.Composition().set_input_type(tdt.VoidType())
with c1.scope():
t = tdb.AllOf(*[np.array(t) for t in range(5)]).reads(c1.input)
c1.output.reads(tdb.Function(tf.add).reads(t[1:-1:2]))
self.assertBuilds(4, c1, None, max_depth=1)Source Code
Github / blocks.py : Line 712
# 考虑到篇幅,仅保留部分函数(隐去大部分以下划线开头的函数)
class Composition(Block):
"""A composition of blocks, which are connected in a DAG."""
def __init__(self, children=None, name=None):
# Dict from block to list of input_wires feeding into the block.
self._child_input_wire_dict = {}
# Dict from block to set of blocks reading from the block.
self._child_output_block_dict = collections.defaultdict(set)
self._child_to_index = {}
self._child_input_wires = []
self._input_ph = _ComposeIO(self, name, is_input=True)
self._output_ph = _ComposeIO(self, name, is_input=False)
self._output_wires = None
if children is not None: children = [convert_to_block(c) for c in children]
super(Composition, self).__init__(children=children, name=name)
@property
def input(self):
"""Return a placeholder whose output is the input to the composition."""
return self._input_ph
@property
def output(self):
"""Return a placeholder whose input is the output of the composition."""
return self._output_ph
# pylint:disable=g-doc-return-or-yield
# This linter warning doesn't really apply to a context manager.
@contextlib.contextmanager
def scope(self):
"""Creates a context for use with the python `with` statement.
Entering this context enabled the use of a block's `reads` method. Once
inside a context calling `some_block.reads(...)` sets `some_block`'s inputs
within the composition.
For example, you could make a composition which computes $x^2 + 10*x$
element-wise for vectors of length 3 as follows:
```python
c = td.Composition()
with c.scope():
x = td.Vector(3).reads(c.input)
x_squared = td.Function(tf.mul).reads(x, x)
ten = td.FromTensor(10 * np.ones(3, dtype='float32'))
ten_x = td.Function(tf.mul).reads(ten, x)
c.output.reads(td.Function(tf.add).reads(x_squared, ten_x)
```
"""
old_composition_context = _COMPOSITION_CONTEXT.current
_COMPOSITION_CONTEXT.current = self
try:
yield
finally:
if _COMPOSITION_CONTEXT.current is not self:
raise AssertionError('scope nesting violation.')
_COMPOSITION_CONTEXT.current = old_composition_context
# pylint:enable=g-doc-return-or-yield
def connect(self, a, b):
"""Connect `a` to the input of `b`.
The argument `a` can be either:
* A block, in which case the output of `a` is fed into the input of `b`.
* The i^th output of a block, obtained from `a[i]`.
* A tuple or list of blocks or block outputs.
Args:
a: Inputs to the block (see above).
b: The block to connect the inputs to.
Raises:
ValueError: if `a` includes the output of the composition.
ValueError: if `b` is the input of the composition.
ValueError: if the input of `b` is already connected.
"""
b = convert_to_block(b)
input_wires = self._create_input_wires(a)
# Make sure everything we're connecting is a child.
for iw in input_wires:
self._maybe_add_child(iw.block)
if iw.block is self.output:
raise ValueError('cannot read from composition output')
self._maybe_add_child(b)
if b is self.input:
raise ValueError('cannot write to composition input')
if b in self._child_input_wire_dict:
raise ValueError('input of block is already connected: %s' % (b,))
self._child_input_wire_dict[b] = input_wires
if b is self.output: self._output_wires = input_wires
if not input_wires:
b.set_input_type(tdt.VoidType())
elif len(input_wires) > 1:
b.set_input_type_classes(tdt.TupleType, tdt.PyObjectType)
for block, index in input_wires:
if index is not None:
block.set_output_type_classes(tdt.TupleType)
if block.output_type is not None:
arity = len(block.output_type)
if arity < index:
raise TypeError('cannot get %d-th output of block %s with %d '
'outputs' % (index, block, arity))
self._child_output_block_dict[block].add(b)
for wire in input_wires:
self._types_forward(wire.block) # propagate types to `b`
self._propagate_types_from_child(b) # propagate types from `b`
Github / blocks_test.py : Line 118
# Source Code in Testing Part.0x02 td.Pipe()
说明文档
td.Pipe(*blocks, **kwargs)
Creates a composition which pipes each block into the next one.
Pipe(a, b, c) is equivalent to a >> b >> c.
Pipe(a, b, c).eval(x) => c(b(a(x)))
Testing
怎么办我觉得说明文档里的那句
Pipe(a,b,c)等效于a>>b>>c
就解释完了呀……
- Return : A block
Source Code
Github / blocks.py : Line 1002
def Pipe(*blocks, **kwargs): # pylint: disable=invalid-name
"""Creates a composition which pipes each block into the next one.
`Pipe(a, b, c)` is equivalent to `a >> b >> c`.
```python
Pipe(a, b, c).eval(x) => c(b(a(x)))
```
Args:
*blocks: A tuple of blocks.
**kwargs: Optional keyword arguments. Accepts name='block_name'.
Returns:
A block.
"""
blocks = [convert_to_block(b) for b in blocks]
blocks = [b for b in blocks if not isinstance(b, Identity)]
if not blocks: return Identity(**kwargs)
if len(blocks) == 1: return blocks[0]
return _pipe(blocks, **kwargs)
def _pipe(blocks, name=None):
"""Internal implementation of Pipe."""
c = Composition(blocks, name=name)
c.connect(c.input, blocks[0])
prev = blocks[0]
for b in blocks[1:]:
c.connect(prev, b)
prev = b
c.connect(prev, c.output)
return c.set_constructor_name('td.Pipe')Github / blocks_test.py : Line 1100
# 基本没有单独用来测试Pipe的函数0x03 td.Record()
说明文档
class td.Record
Dispatch each element of a dict, list, or tuple to child blocks.
A Record block takes a python dict or list of key-block pairs, or a tuple of blocks, processes each element, and returns a tuple of results as the output.
Testing
Record是一个字典,是一个value为block,key可以自定(不指定那就是从0开始依次表示)。作为一个容器,处理其内部block时的等效形式如下:
Record({'a': a_block, 'b': b_block}).eval(inp)
# => (a_block.eval(inp['a']), b_block.eval(inp['b']))
Record([('a', a_block), ('b', b_block)]).eval(inp)
# => (a_block.eval(inp['a']), b_block.eval(inp['b']))
Record((a_block, b_block)).eval(inp)
# => (a_block.eval(inp[0]), b_block.eval(inp[1]))那么,我们在使用它的时候可以用来做哪些事情呢?
def test_record(self):
d = tdb.Record(collections.OrderedDict([('b', tdb.Scalar()),
('a', tdb.Scalar())]))
c = d >> tdb.Function(tf.subtract)
c.eval({'a': 1.0, 'b': 5.0}) # => array(4.0, dtype=float32)用来确定传入值之间的关系,如上述示例中,b为被减数,a为减数,由此定义好了之后,无论以什么顺序传入,都会是output = ( b - a )。
def test_record_one_child(self):
self.assertBuildsConst((42,), tdb.Record({0: tdb.Scalar('int32')}), {0: 42})Record中只有一个child的时候也是可行的,说到这里我就去试了一下三个child的,就会报错了,定位到__NonZero__这里,报错如下,我猜会不会暂时Record就不能当list,只能当pair用之类的(未确认,需要调查研究下)……:
TypeError("Using a `tf.Tensor` as a Python `bool` is not allowed. "
"Use `if t is not None:` instead of `if t:` to test if a "
"tensor is defined, and use TensorFlow ops such as "
"tf.cond to execute subgraphs conditioned on the value of "
"a tensor.") def test_record_composition(self):
d = tdb.Record({'a': tdb.Scalar(), 'b': tdb.Scalar()})
fn1 = times_scalar_block(2.0)
fn2 = times_scalar_block(3.0)
fn3 = tdb.Function(tf.add)
c = tdb.Composition([d, fn1, fn2, fn3])
c.connect(c.input, d)
c.connect(d['a'], fn1)
c.connect(d['b'], fn2)
c.connect((fn1, fn2), fn3)
c.connect(fn3, c.output)
self.assertBuilds(17.0, c, {'a': 1.0, 'b': 5.0}, max_depth=2)啊这不是我们的老朋友Composition嘛,这里为我们展现了Record在运算图中的连接方式,d['a']与d['b']这样的表达方式还真是简单明朗呢。
Source Code
Github / blocks.py : Line 1037
class Record(Block):
def __init__(self, named_children, name=None):
"""Create a Record Block.
If named_children is list or tuple or ordered dict, then the
output tuple of the Record will preserve child order, otherwise
the output tuple will be ordered by key.
Args:
named_children: A dictionary, list of (key, block) pairs, or a
tuple of blocks (in which case the keys are 0, 1, 2, ...).
name: An optional string name for the block.
"""
self._unordered = (isinstance(named_children, dict) and
not isinstance(named_children, collections.OrderedDict))
named_children = _get_sorted_list(named_children)
self._named_children = named_children
self._keys = [k for k, _ in named_children]
super(Record, self).__init__(
children=[c for (_, c) in named_children], name=name)
if not self.children: self.set_output_type(())
if not self.children: self.set_output_type(())
def _repr_kwargs(self):
return dict(ordered=not self._unordered)
def __getitem__(self, k):
"""Return a reference to the k^th output, where k is a child key."""
return _InputWire(self, self._keys.index(k))
_expected_input_types = (tdt.PyObjectType, tdt.TupleType)
_expected_output_types = (tdt.PyObjectType, tdt.TupleType)
def _update_input_type(self):
if isinstance(self.input_type, tdt.PyObjectType):
# If we have input type PyObjectType then all children must also.
for b in self.children:
b.set_input_type(tdt.PyObjectType())
elif self._unordered:
# Prevent user from shooting self in foot.
raise RuntimeError(
'record block %s created with an unordered dict cannot take ordered '
'inputs; use an OrderedDict or list of (key, block) instead' % self)
else:
assert isinstance(self.input_type, tdt.TupleType)
# If we have a tuple input type, then children must correspond to items.
if len(self.children) != len(self.input_type):
raise TypeError('Record block has %d children but %d inputs: %s' %
(len(self.children), len(self.input_type),
list(self.input_type)))
for b, t in zip(self.children, self.input_type):
b.set_input_type(t)
self._infer_output_type_from_children()
def _update_output_type(self):
if isinstance(self.output_type, tdt.PyObjectType):
# If we have output type PyObjectType then all children must also.
for b in self.children:
b.set_output_type(tdt.PyObjectType())
else:
assert isinstance(self.output_type, tdt.TupleType)
# If we have a tuple output type, then children must correspond to items.
if len(self.children) != len(self.output_type):
raise TypeError('Record block has %d children but %d outputs: %s' %
(len(self.children), len(self.output_type),
list(self.output_type)))
for b, t in zip(self.children, self.output_type):
b.set_output_type(t)
def _propagate_types_from_child(self, _):
if not any(b.input_type is None for b in self.children):
self.set_input_type(tdt.TupleType(b.input_type for b in self.children))
self._infer_output_type_from_children()
def _infer_output_type_from_children(self):
if not any(b.output_type is None for b in self.children):
self.set_output_type(tdt.TupleType(b.output_type for b in self.children))
def _evaluate(self, eval_ctx, x):
# pylint: disable=protected-access
return tuple(b._evaluate(eval_ctx, x[k]) for (k, b) in self._named_children)Github / blocks_test.py : Line 383
def test_record_tuple(self):
block = (tdb.AllOf(tdb.Scalar(), tdb.OneHot(3, dtype='int32')) >>
(tdb.Function(tf.square), tdb.Function(tf.negative)))
self.assertBuilds((4., [0, 0, -1]), block, 2)
def test_record_raises(self):
six.assertRaisesRegex(
self, RuntimeError,
'created with an unordered dict cannot take ordered',
tdb.Pipe, (tdb.Scalar(), tdb.Scalar()),
{'a': tdb.Identity(), 'b': tdb.Identity()})
def test_record_slice_key(self):
b = tdb.Record([
(0, tdb.Scalar()),
(slice(1, 3), (tdb.Scalar(), tdb.Scalar()) >> tdb.Concat())])
self.assertBuilds((1., [2., 3.]), b, [1, 2, 3])0x04 td.AllOf()
说明文档
td.AllOf(*blocks, **kwargs)
A block that runs all of its children (conceptually) in parallel.
Testing
AllOf().eval(inp) => None
AllOf(a).eval(inp) => (a.eval(inp),)
AllOf(a, b, c).eval(inp) => (a.eval(inp), b.eval(inp), c.eval(inp))td.AllOf()可以看作一个并联线路,被包裹起来的里面的所有blocks,会并行地进行,官方这里的示例可能有一点点歧义:
AllOf(a, b, c).eval(inp) => (a.eval(inp), b.eval(inp), c.eval(inp))
请不要理解成里面所有的blocks都执行了相同的eval操作,从而误解为AllOf是一个批量分发任务的函数,请看下面这个例子,应该可以很好的解释清楚这个问题:
def test_tuple_of_seq(self):
block = tdb.AllOf(
tdb.Map(tdb.Scalar() >> tdb.Function(tf.negative)),
tdb.Map(tdb.Scalar() >> tdb.Function(tf.identity)))
self.assertBuilds(([], []), block, [], max_depth=0)
self.assertBuilds(([-1., -2.], [1., 2.]), block, [1, 2])在该例中,[1, 2]传入之后同时被AllOf()内部的两个td.Map(td.Scalar() >> ...)接收到,然后他们俩开始并行的跑Pipeline,上面的那个进行了求反操作,下面的那个则原封不动,输出为([-1., -2.], [1., 2.])——综上,是可能存在有AllOf内部blocks进行不同操作的情况的。
def test_concat_nested(self):
block = (tdb.AllOf(tdb.AllOf(tdb.Scalar(), tdb.Scalar()),
tdb.AllOf(tdb.Scalar(), tdb.Scalar())) >>
tdb.Concat(flatten=