机器学习 —— 基础整理:线性判别函数——感知器松弛算法Ho-Kashyap算法
Posted Determined22
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习 —— 基础整理:线性判别函数——感知器松弛算法Ho-Kashyap算法相关的知识,希望对你有一定的参考价值。
这篇总结继续复习分类问题。本文简单整理了以下内容:
(一)线性判别函数与广义线性判别函数
(二)感知器
(三)松弛算法
(四)Ho-Kashyap算法
闲话:本篇是本系列[机器学习基础整理]在timeline上最新的,但实际上还有(七)、(八)都发布的比这个早,因为这个系列的博客是之前早就写好的,不过会抽空在后台修改,感觉自己看不出错误(当然因为水平有限肯定还是会有些错误)了之后再发出来。后面还有SVM、聚类、tree-based和boosting,但现在的情况是前八篇结束后,本系列无限期停更……
(一)线性判别函数与广义线性判别函数
一、线性判别函数
现假设判别函数(Discriminant function)的参数形式已知,用训练的方法直接根据样本估计判别函数的参数。例如,线性判别函数的形式为:
$$g(\\textbf x)=\\textbf w^{\\top}\\textbf x+w_0$$
$\\textbf x\\in \\mathbb R^d$ 是给定的样本,$\\textbf w=(w_1,w_2,\\cdots,w_d)$ 是权重向量,$w_0$ 是偏置。对于多类分类问题,如果有 $c$ 个类,那么有 $c$ 个判别函数,将样本的类别判定为各判别函数取值最大的一个(实际上这是一种one-vs-all的方式,因为一个判别函数只可以解决二类的分类问题。下面会简单介绍)。
二分类问题的线性判别函数
如果是二分类问题,则可以只有一个判别函数,当 $g(\\textbf x)>0$ 时判为正类,$g(\\textbf x)<0$ 时判为负类,$g(\\textbf x)=0$ 时任意。因此,$g(\\textbf x)=0$ 就是决策面,对于线性判别函数来说,这是一个超平面(hyperplane,直线的高维推广)。对于一组来源于两类的样本来说,如果存在一个超平面可以将它们完全正确地分开,则称它们是线性可分的。
就这个描述来说,之前总结过的二项Logistic回归模型(如果只考虑线性决策面)和这里的描述是一致的,本质上都是需要学习出 $\\textbf w$ 、$w_0$ ,二项Logistic回归模型还更进一步,将判别函数的值通过logistic函数 $\\sigma(\\cdot)$ 映射到了 $(0,1)$ 区间,进而给出了样本属于正类的概率。
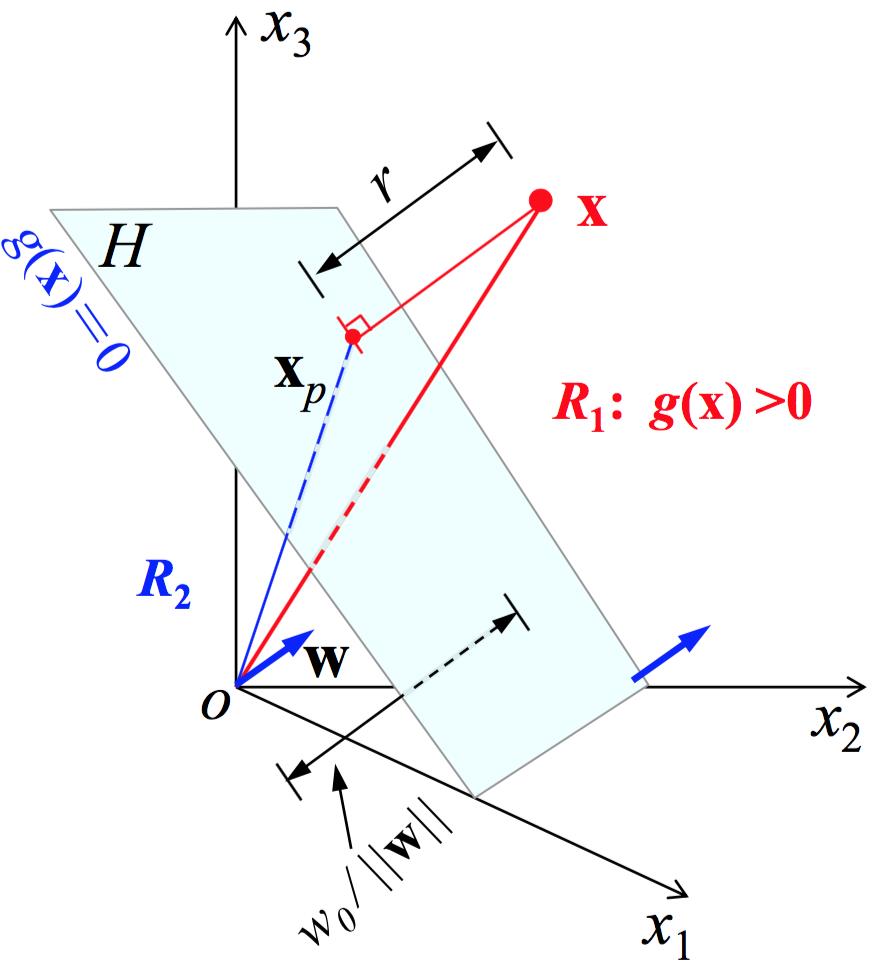
根据几何关系,对于任一样本 $\\textbf x$ 来说,设它到决策面的投影点为 $\\textbf x_p$ ,到决策面的距离为 $r$ (有正负,如果大于零则表示样本属于正类,处在决策面的正侧),那么如下关系成立:
$$\\textbf x=\\textbf x_p+r\\frac{\\textbf w}{||\\textbf w||}$$
由于 $g(\\textbf x_p)=0$ ,所以可得到 $r=g(\\textbf x)/||\\textbf w||$ 。如果决策面过原点,就表明 $w_0=0$ (原点到决策面的距离为 $w_0/||\\textbf w||$ ),这时称判别函数是齐次(homogeneous)的。
图片来源:[1]
one-vs-rest
这里多提一句,如果是二分类器想用于多分类问题( $c$ 类),一般采用的策略是 one-vs-all(one-vs-rest),就是说训练 $c$ 个二分类器,其中分类器 $i$ 给出样本属于 $i$ 类的后验概率( $i=1,2,\\cdots, c$ ),从而将样本的类别判定为后验概率最大的那个类。
二、广义线性判别函数
既然可以有线性判别函数,那么同理可以有二次判别函数(quadratic),其决策面是超二次曲面;进一步可以有多项式判别函数(polynomial)。所谓广义线性判别函数(generalized linear),就是指
$$g(\\textbf x)=\\sum_{i=1}^{\\hat d}a_iy_i(\\textbf x)=\\textbf a^{\\top}\\textbf y$$
这里 $\\textbf y=(y_1(\\textbf x),y_2(\\textbf x),\\cdots,y_{\\hat d}(\\textbf x))^{\\top}\\in \\mathbb R^{\\hat d}$ ,将 $\\textbf x$ 映射到 $\\hat d$ 维空间。齐次的形式标明了该判别函数所决定的决策面通过新空间的原点,新空间中的任一点到决策面的距离为 $\\textbf a^{\\top}\\textbf y/||\\textbf a||$ (根据上面 $r$ 的表达式可类似得到)。如果 $\\hat d$ 足够大,那么 $g(\\textbf x)$ 可以逼近任意判别函数,但是如果新空间的维数远高于原始空间的维数则会带来维数灾难(因为随着维数增多,需要的样本量指数级增长,之前的总结中提到过)。
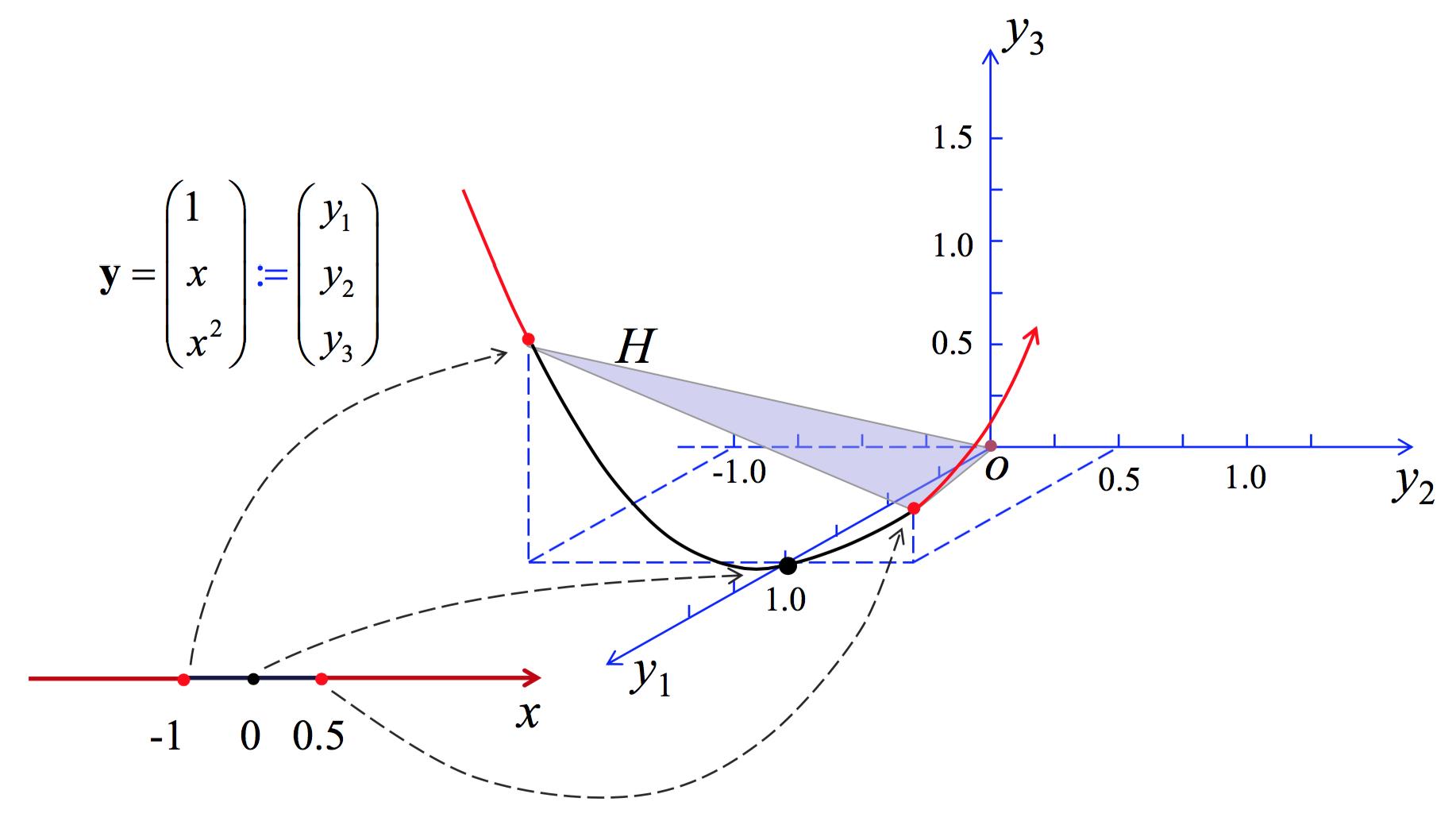
举个例子:设一维空间下的样本,希望 $x<-1$ 或 $x>0.5$ 为正类,那么可以得到符合要求的判别函数为 $g(x)=(x-0.5)(x+1)=-0.5+0.5x+x^2$ ,所以这里就将一维样本映射到了三维空间:$\\textbf y=(y_1,y_2,y_3)^{\\top}=(1,x,x^2)^{\\top}$ 。从图里可以看出,映射后的概率密度其实是退化的,在曲线上无穷大,曲线外为0,这是映射到高维空间时的一个普遍问题。
图片来源:[1]
借着这个讨论,规定一下记号:在后面的讨论中,假设样本 $\\textbf x$ 都将转换为规范化增广表示形式 $\\textbf y$ :增广就是说先把 $\\textbf x$ 加一个维度 $x_0$ 且 $x_0=1$ ,规范化就是说当样本属于负类时,将样本的每个维度(包括 $x_0$ )取负号。并且权重向量 $\\textbf w$ 和偏置 $w_0$ 合为一个向量 $\\textbf a=(w_0,w_1,\\cdots,w_d)^{\\top}$ 。
三、解区
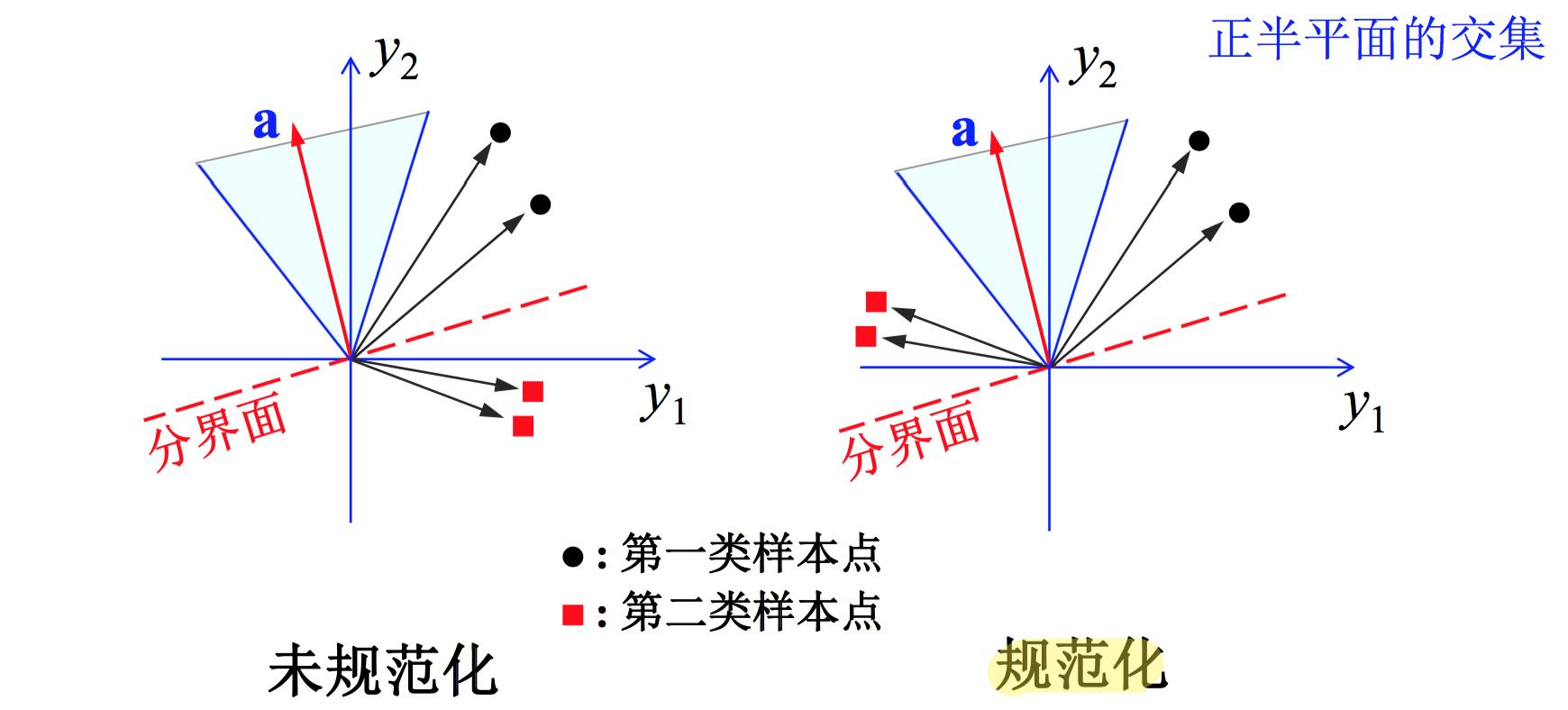
在这样的表示下,目标就成了:求出使 $\\textbf a^{\\top}\\textbf y_i>0$ 对所有样本 $\\textbf y_i$( $i=1,2,\\cdots,N$)都成立的权向量 $\\textbf a$。在线性可分的情况下,满足该要求的权向量被称为解向量(Solution vector) $\\textbf a$ 。
权向量 $\\textbf a$ 可认为是权空间中的一点,任一样本 $\\textbf y_i$ 对解向量的位置都起限制作用。由于任一样本 $\\textbf y_i$ 都可以确定一个以 $\\textbf y_i$ 为法向量的超平面 $\\textbf a^{\\top}\\textbf y_i=0$ ,所以如果解向量存在,则它必处在超平面的正侧,因为只有处在正侧才满足 $\\textbf a^{\\top}\\textbf y_i>0$ 。
那么,如果解向量存在,则它必处在所有超平面 $\\textbf a^{\\top}\\textbf y_i=0$ 的正侧区域的交集内,这个交集称为解区(Solution region)。如下图所示,阴影部分的区域内都是解向量。
图片来源:[1]
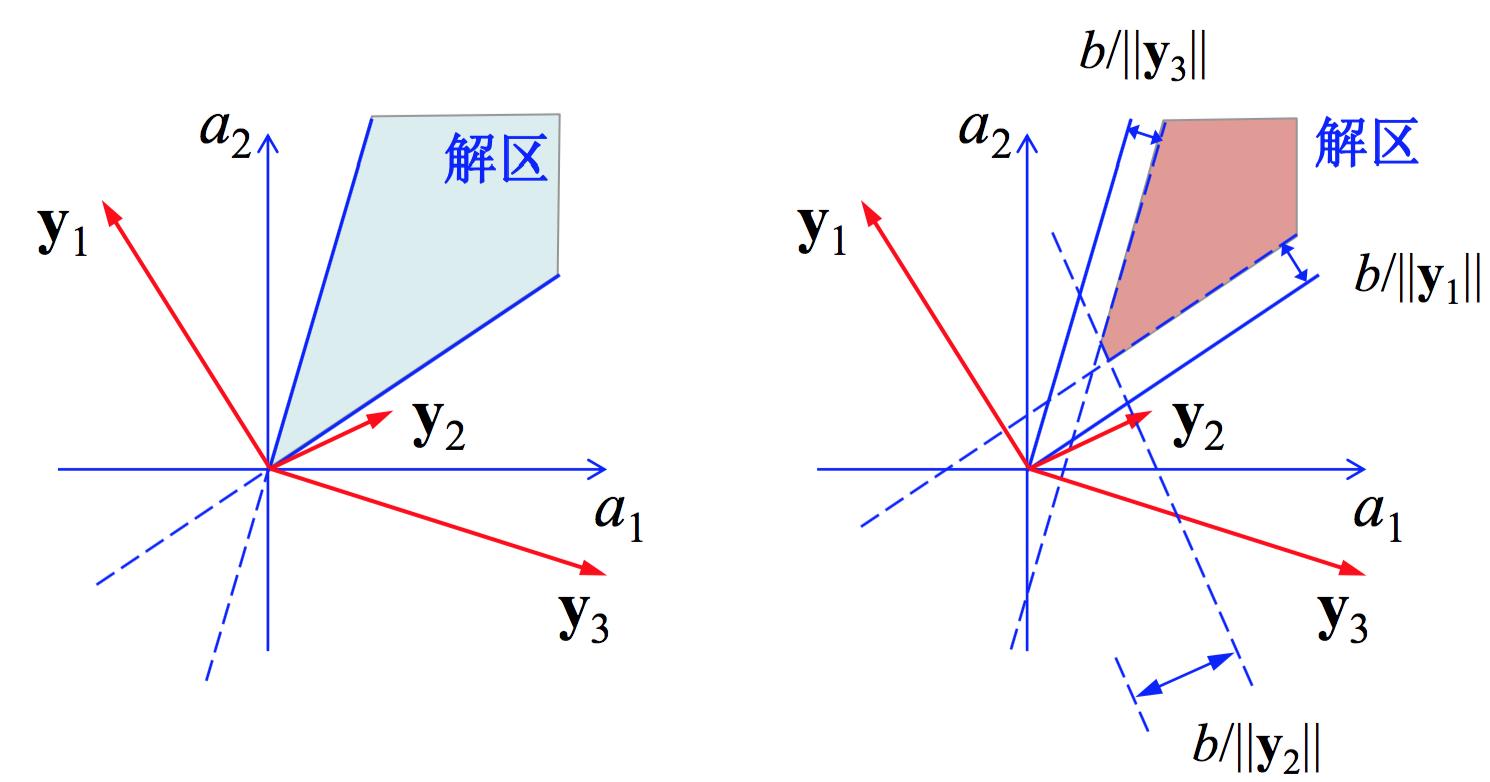
其实还可以对解区进行限制,比如说将目标变得严苛一些: $\\textbf a^{\\top}\\textbf y_i\\geq b>0$ ,$b$ 被称为margin(译为“间隔”、“边沿裕量”,SVM的一个核心概念)。限制解区后的情形如下图所示。
图片来源:[1]
四、准则函数
从上面可以知道,对于线性可分的情况,解向量有无数个。所以要引入准则函数(Criterion function),通过迭代的方式进行训练,求取准则函数的最小值,来得到唯一一个解向量。并且尽量不收敛到解区边界,因为解区中间的解向量往往泛化性更好。
准则函数有点像之前介绍的经验风险(刻画模型在训练样本上的平均损失),都是训练模型时的优化目标。
下面就开始介绍各种用来训练线性判别函数的准则。
(二)感知器Perceptron
零、历史
既然说到感知器了,那就跑题说点历史好了。
1890年,美国生物学家W. James出版了《Physiology》(生理学)一书,讲述有关人脑结构和功能,以及学习、记忆等基本规律,指出当两个基本处理单元同时活动,或两个单元靠得很近时,一个单元的兴奋状态会传递给另一单元,并且一个单元的活动程度与其周围的活动数量和密度成正比。
1943年,Warren McCulloach, Walter Pitts提出了著名的MP神经元模型,认为单元的输入存在兴奋边、抑制边两种,如果没有抑制边输入并且兴奋边的数量超过一个阈值,则神经元处于兴奋,否则处于抑制——这个模型给出了神经元的结构,使用阈值函数来输出,但所有输入边的权重都为1,并且只要有一条抑制边输入那么就不可能兴奋。
1949年,心理学家Hebb提出用于确定输入边权重的Hebb规则,该规则认为两个具有相同状态的神经元之间的权重要大。
1957年,Frank Rosenblatt提出感知器(Perceptron),随后在IBM704计算机上进行模拟从而证明了该模型有能力通过调整权重的学习达到正确分类的效果,第一次把神经网络从纯理论推到工程实践,掀起了研究高潮;在1962年感知器算法被证明是收敛的。
1960年,Bernard Widrow和Ted Hoff提出自适应线性单元(Adaptive linear neuron,ADALINE),学习规则也由Hebb规则转向Delta规则:利用实际输出与期望输出的误差来指导学习,即LMS filter(上篇总结的线性回归部分提到过)。
1969年,Minsky出版《Perceptron》,但同时指出感知器的两个问题:一个就是著名的“单层感知器无法解决异或(XOR,相异取真,相同取假)这样的线性不可分问题”,另外一个是这种局限在复杂结构中依然存在。不只是神经网络,整个AI都迎来寒冬。那时候晶体管还没有普及,大多是电子管(真空管),支持不了大规模计算。
1974年,Paul Werbos的博士论文里提出了BP算法(后被称为广义Delta规则),但是没有引起重视。
在70年代,据说全球只有几十个人在研究,但还是有一些成果:1976年Stephen Crossberg的共振自适应理论(Adaptive resonance theory,ART网络)、1979年日本Fukusima的神经认知机(Neocognitron,将感受野应用到NN)、80年代芬兰Kohonen的自组织竞争神经网络等。
1982年,物理学家John Hopfield提出Hopfield网络,基本思路是对于一个给定的神经网络,设计一个正比于每个神经元的活性和权重的能量函数,活性的改变算法向能量函数减小的方向进行,直到达到极小值。神经网络开始复兴。
1986年,Rumelhart、Hinton、Williams将BP应用到神经网络;1987年,第一届世界神经网络大会在美国召开,千人参会。
1989年,使用sigmoid激活的单隐层神经网络被证明可以逼近任意非线性函数;LeCun的CNN用在文本识别;1990年,RNN;1997年,LSTM;2006年,DBN,深度学习的概念被提出;2011年,语音识别领域首先取得突破;2012年,AlexNet在ImageNet夺冠,引爆这个领域,之后……
一、感知器
首先说明:感知器算法(以及接下来介绍的松弛算法)对于线性不可分的数据是不收敛的。对于线性可分的数据,可以在有限步内找到解向量。收敛速度取决于权向量的初始值和学习率。
感知器(Perceptron)属于判别模型(Discriminative model),从样本中直接学习判别函数,所有类别的样本放在一起学习。它是神经网络和SVM的基础。
感知器准则函数被定义为
$$J_p(\\textbf a)=\\sum_{\\textbf y\\in \\mathcal Y(\\textbf a)}(-\\textbf a^{\\top}\\textbf y)$$
式中的 $\\mathcal Y(\\textbf a)$ 是被当前 $\\textbf a$ 错分的样本(即满足 $\\textbf a^{\\top}\\textbf y\\leq 0$ 的全部 $\\textbf y$ )构成的集合。
也就是说,感知器算法是错误驱动(error-correcting procedure)的:被正确分类的样本对准则函数没有贡献,不产生误差;又因为对于被错分的样本 $\\textbf y$ ,$\\textbf a^{\\top}\\textbf y\\leq 0$ ,那么可以知道 $J_p(\\textbf a)\\geq 0$ 。如果不存在错分样本,那么准则函数的值就为0。因此,优化目标就是最小化 $J_p(\\textbf a)$ :
$$\\min_{\\textbf a}J_p(\\textbf a)$$
使用梯度下降法,迭代求取解向量。准则函数的梯度以及更新规则为
$$\\nabla_{\\textbf a}J_p=\\frac{\\partial J_p}{\\partial\\textbf a}=\\sum_{\\textbf y\\in \\mathcal Y(\\textbf a)}(-\\textbf y)$$
$$\\textbf a_{k+1}=\\textbf a_{k}-\\eta_k\\nabla_{\\textbf a}J_p$$
式中的下标 $k$ 表示第 $k$ 次迭代。停机条件可以是全部样本都被权向量所决定的超平面正确分类,也可以放松一点,例如 $J_p(\\textbf a)$ 小于某个很小的值,或达到了最大的迭代次数时强制停机。
得到解向量 $\\textbf a$ 后,就唯一确定了判别函数 $g(\\textbf x)$ ,进而可以对样本 $\\textbf x$ 进行分类。
这种更新方式被称为批处理(batch)梯度下降,因为在一次迭代过程中求取了全部训练样本的梯度,这种方式在样本量很大且特征维数很高的时候效率比较低。
与之相对应的一种方式是随机梯度下降(Stochastic gradient descent),一次迭代中随机选取一个被错分的样本求梯度然后更新权向量。随机梯度下降的方式可以有非常显而易见的解释:当前的权向量会把一个样本错误分类,那么就把此时的超平面向这个样本移动,使新的权向量有可能将其正确分类。设在一次迭代中挑选出的被错分的样本为 $\\textbf y^k$ ,那么更新规则为
$$\\textbf a_{k+1}=\\textbf a_{k}-\\eta_k(-\\textbf y^k)$$
一种折中的方式是mini-batch梯度下降,这正是目前采用最广泛的一种方式。
学习率是非常关键的,太大会导致震荡,太小则会使收敛过程很慢。现在有不少策略使学习率自适应调整,例如AdaGead、Adam、AdaDelta、RMSprop等;另外,还有加动量的方式,在当前迭代中加入上一次的梯度进行加速。这里就不展开了,具体哪种方式更好是取决于具体任务的。
将感知器的更新准则和神经网络的BP算法进行比较可知,后者主要是多出来了一项激活函数的导函数。
二、带margin的感知器
感知器可以带margin,也就是说进一步要求解向量必须满足 $\\textbf a^{\\top}\\textbf y_i\\geq b>0$ 。相比于不带margin的感知器,梯度是没有变的所以更新规则的表达式是一样的,但变化的是 $\\mathcal Y(\\textbf a)$ 以及停机条件。
三、多类感知器
原始的感知器只能处理两类问题,不提供概率形式的输出,所以不能处理多类分类问题。通过引入特征函数 $\\phi(x,y)$ 将输入输出对映射到向量空间中,可以得到多类感知器。在特征函数的作用下,感知器不仅可以处理多类问题,也能处理结构化输出任务(这类任务也有专门的算法,比如structured-SVM等)。这里不展开了,因为没有在实战中用过,所以也没有太多理解,具体讲解可以参考[3]。
(三)松弛算法Relaxation procedure
一、平方准则函数
在介绍松弛算法之前,先介绍平方准则函数。
上面所提到的感知器准则函数可以被称为线性准则函数。所谓平方准则函数是下面的形式:
$$J_q(\\textbf a)=\\sum_{\\textbf y\\in \\mathcal Y(\\textbf a)}(\\textbf a^{\\top}\\textbf y)^2$$
可以看出二者之间的共同点是都只关注被错分的样本,区别在于 $J_p$ 的梯度是不连续的(因为 $J_p$ 分段线性),$J_q$ 的梯度是连续的。但是即便如此,$J_q$ 依然存在两个问题:首先, $J_q$ 过于平滑导致收敛很慢,而且其在解区边界很光滑导致可能收敛到解区边界,对泛化性不利;其次,其得到的解向量可能依赖于模值最大的样本向量。由于上面两个问题,引出下面的松弛准则函数。
二、松弛准则函数
与感知器相同,松弛算法(Relaxation procedure)也是错误驱动的。松弛准则函数的形式如下
$$J_r(\\textbf a)=\\frac12\\sum_{\\textbf y\\in \\mathcal Y(\\textbf a)}\\frac{(\\textbf a^{\\top}\\textbf y-b)^2}{||\\textbf y||^2}$$
式中的 $\\mathcal Y(\\textbf a)$ 是满足 $\\textbf a^{\\top}\\textbf y\\leq b$ 的全部 $\\textbf y$ 构成的集合。同样地,可以用批处理的方式更新权向量,梯度和更新规则为
$$\\nabla_{\\textbf a}J_r=\\sum_{\\textbf y\\in \\mathcal Y(\\textbf a)}\\frac{\\textbf a^{\\top}\\textbf y-b}{||\\textbf y||^2}\\textbf y$$
$$\\textbf a_{k+1}=\\textbf a_{k}-\\eta_k\\nabla_{\\textbf a}J_r$$
类似于感知器,可得随机梯度下降方式下松弛算法的更新规则:
$$\\textbf a_{k+1}=\\textbf a_{k}-\\eta_k\\frac{\\textbf a_k^{\\top}\\textbf y^k-b}{||\\textbf y^k||^2}\\textbf y^k$$
下面讨论一下学习率 $\\eta_k$ 取值不同时,$\\textbf a_{k+1}$ 是否可以把被 $\\textbf a_{k}$ 错分的样本 $\\textbf y^k$ 正确分类。根据这个式子,稍加计算就可以得到
$$\\frac{\\textbf a_{k+1}^{\\top}\\textbf y^k-b}{1-\\eta_k}=\\textbf a_k^{\\top}\\textbf y^k-b\\leq 0$$
所以如果想要 $\\textbf a_{k+1}$ 将样本 $\\textbf y^k$ 正确分类(即 $\\textbf a_{k+1}^{\\top}\\textbf y^k-b\\geq 0$ ),就必须有
$$\\eta_k>1$$
这种情况被称为超松弛(过松弛)。类似地,$\\eta_k<1$ 被称为软松弛(欠松弛)。
实际使用中,通常限定 $0<\\eta_k<2$ ,做了这样的限定之后,对于线性可分的数据来说松弛算法可以收敛到解向量。与感知器相同,松弛算法对于线性不可分数据是不收敛的。
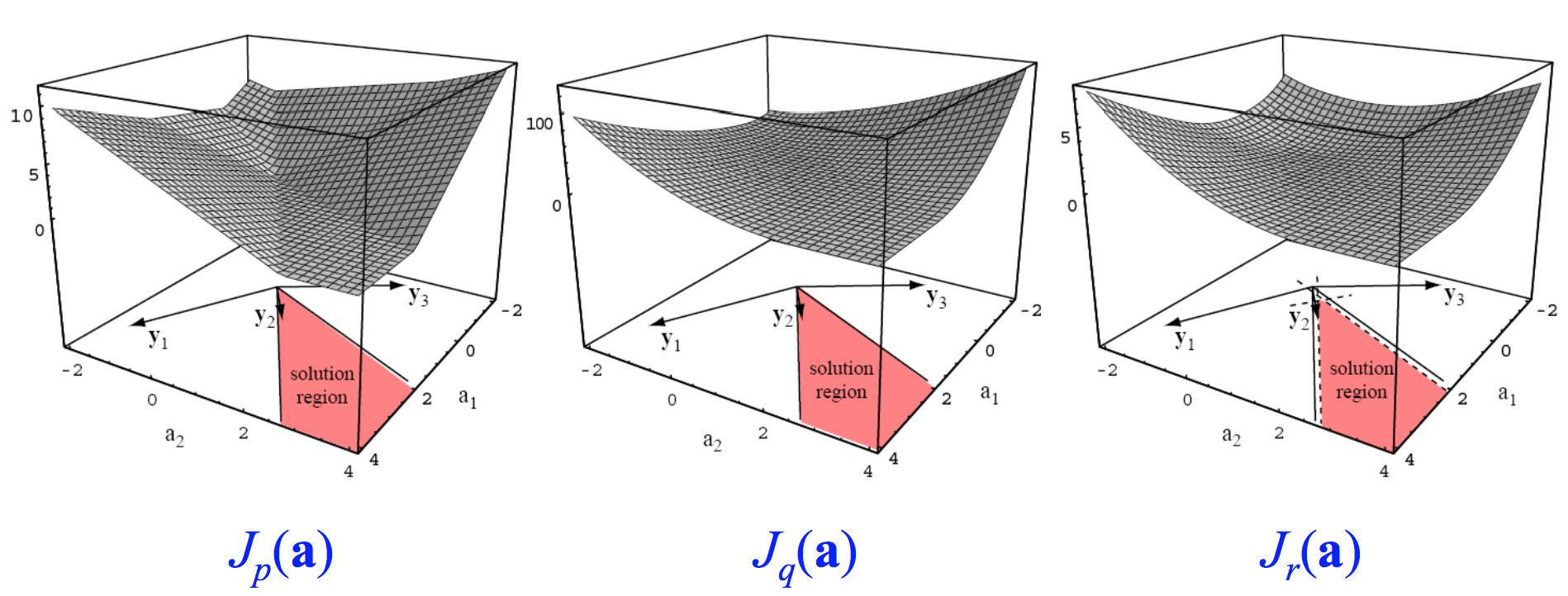
图片来源:[1]
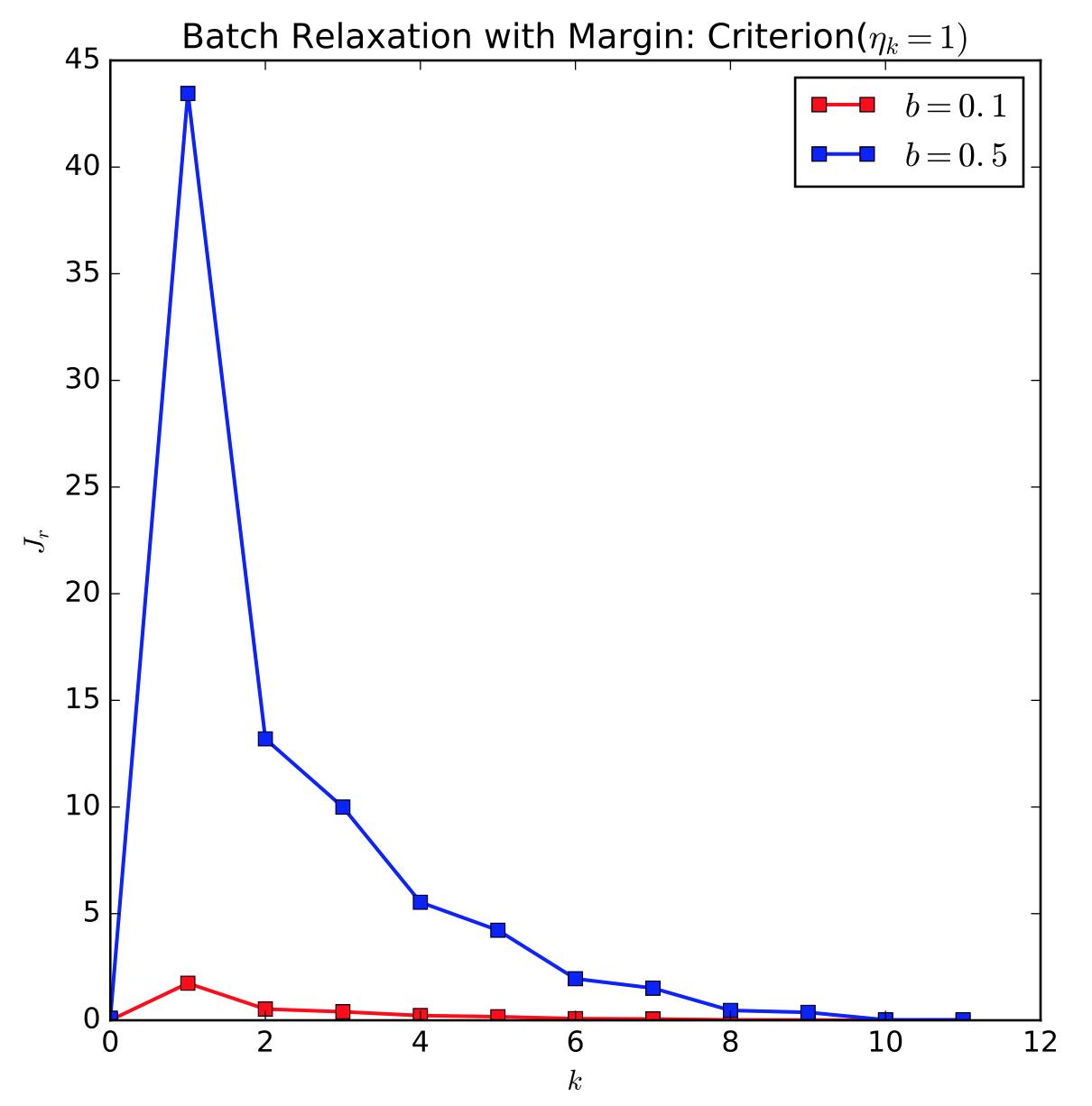
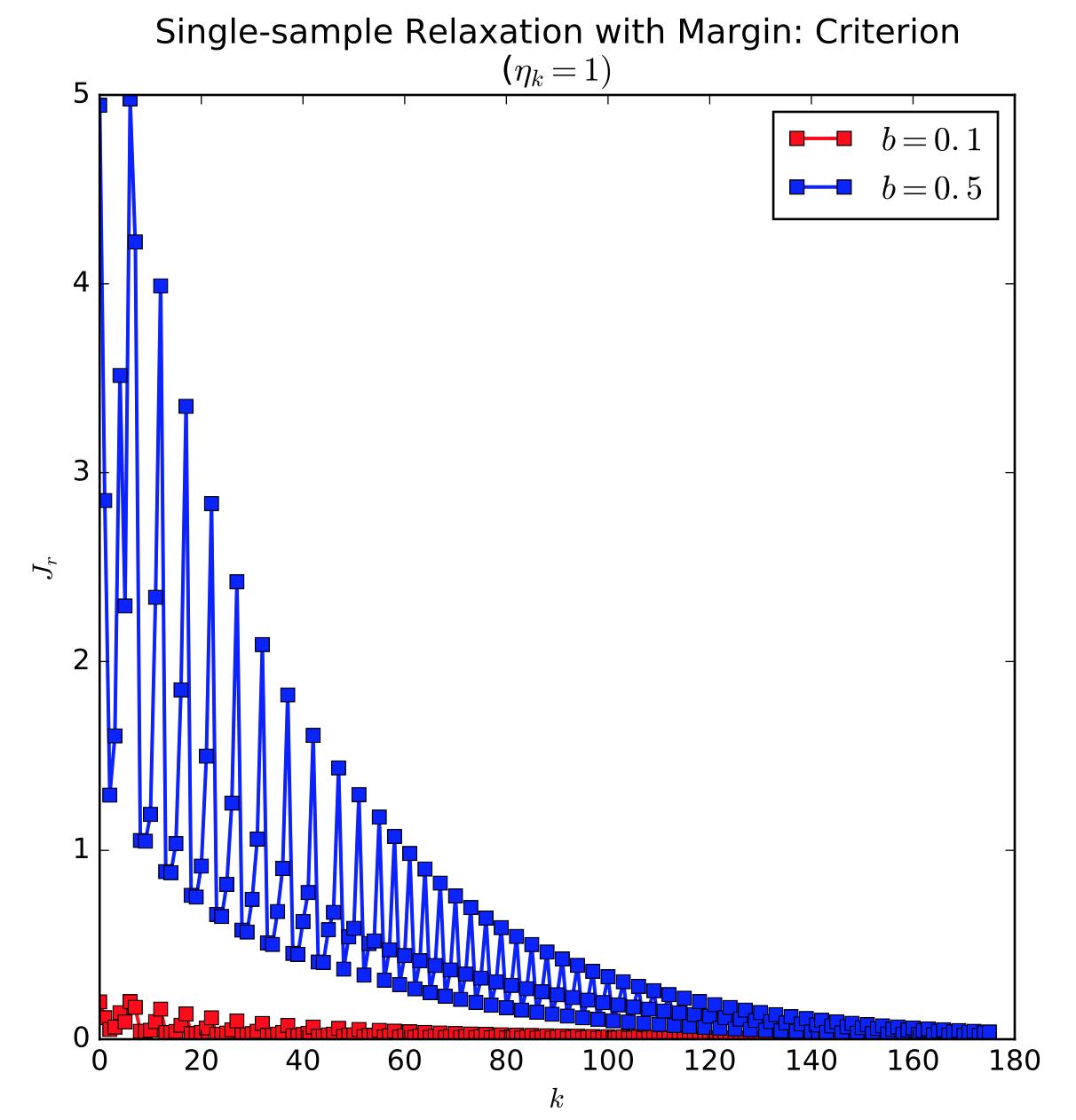
我简单实现了松弛算法(批处理和SGD),在不能更toy的线性可分数据(二维特征,每类10个点。。。)上运行,画出了准则函数的值随迭代次数的变化趋势图:第一张图是批处理梯度下降,初始向量为全零,margin分别取0.1和0.5,固定增量 $\\eta_k=1$ ;第二张图是随机梯度下降,初始向量为全零,margin分别取0.1和0.5,固定增量 $\\eta_k=1$ 。可以看出,批处理梯度下降方法会让准则函数值的变化趋势平滑一些。
(四)Ho-Kashyap算法
一、MSE准则函数
在介绍Ho-Kashyap算法之前,先介绍最小误差平方和准则函数。在上一篇总结中,线性回归就是用的平方损失函数来求取权重向量,这里的思路和线性回归是一致的。
刚才的准则函数都是关注于错分样本,而对正确分类的样本则没有考虑在内。MSE准则函数把求解目标从不等式形式变成了等式形式:求取满足 $\\textbf a^{\\top}\\textbf y_i=b_i$ 的权向量。在这里,$b_i$ 是任取的正常数。
如果记矩阵 $Y\\in\\mathbb R^{N\\times \\hat d}$ 且其每行都是一个样本 $\\textbf y^{\\top}$ ,向量 $\\textbf b=(b_1,b_2,\\cdots,b_N)^{\\top}$ ,那么就可以表述为求方程 $Y\\textbf a=\\textbf b$ 的解。为了求解这个问题,使用MSE准则函数:
$$J_s(\\textbf a)=||Y\\textbf a-\\textbf b||^2=\\sum_{i=1}^N(\\textbf a^{\\top}\\textbf y_i-b_i)^2$$
到这里其实就没必要继续说下去了,因为上篇刚整理过——这不就是线性回归吗?只不过在这里求出来的解向量被用来定义决策面。最小化上述准则函数有两种方法,一种是直接求一阶导数等于零这个方程(正规方程组),一种是LMS规则迭代求解。MSE准则函数的梯度以及LMS规则(batch和SGD)为
$$\\nabla_{\\textbf a}J_s=2Y^{\\top}(Y\\textbf a-\\textbf b)$$
$$\\textbf a_{k+1}=\\textbf a_{k}-\\eta_k\\nabla_{\\textbf a}J_s$$
$$\\textbf a_{k+1}=\\textbf a_{k}-\\eta_k(\\textbf a_k^{\\top}\\textbf y^k-b)\\textbf y^k$$
乍一看好像和松弛算法一样,其实有两个区别——第一个区别是停机条件不同:松弛算法要求对于全部的样本都有 $\\textbf a^{\\top}\\textbf y_i>b$ ,而MSE则要求 $\\textbf a^{\\top}\\textbf y_i=b_i$ ,所以后者必须令学习率随迭代次数的增加而减少才能保证收敛(实际中这种精确相等关系几乎是不可能的),例如取 $\\eta_k=\\eta_1/k$ ;第二个区别是松弛算法对于不可分的样本不收敛,而MSE总能收敛到一个权向量。
那么问题就来了,MSE方法得到的解向量所决定的超平面实际上未必是分类面,因为它的本质是最小化样本到超平面的距离的平方和,而不是分类。
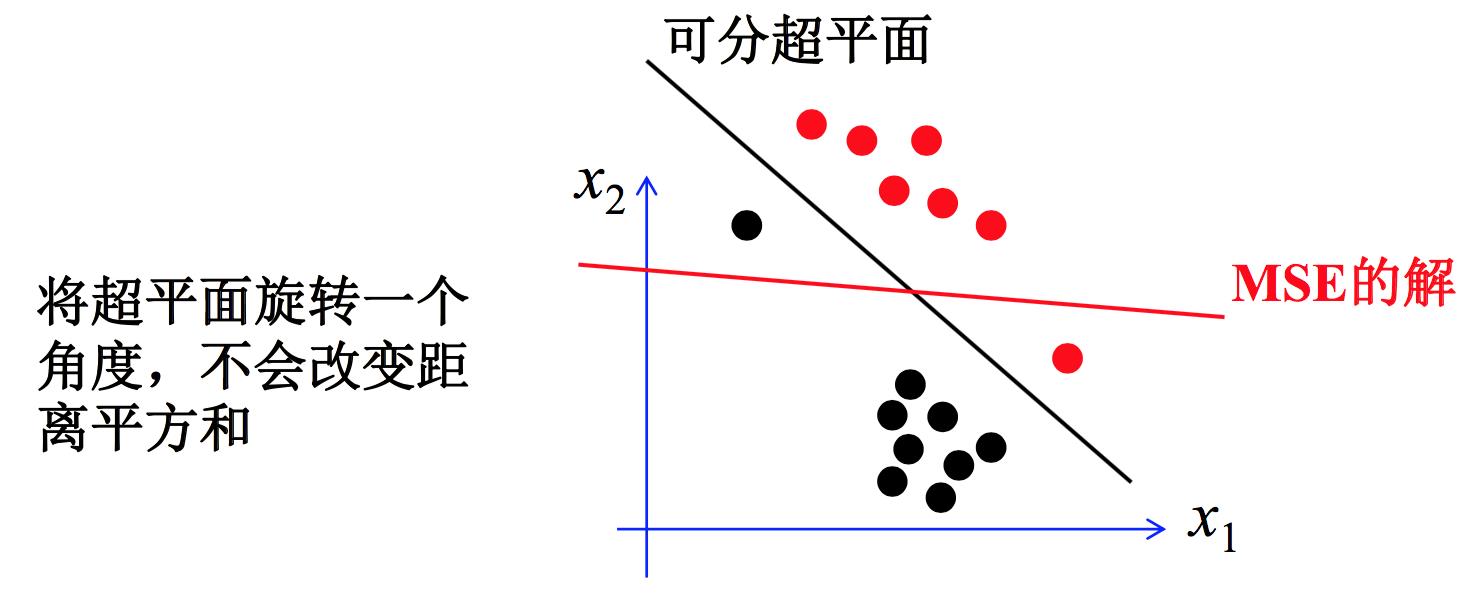
图片来源:[1]
二、Ho-Kashyap算法
为了保证算法可以收敛到分类超平面,必须做出改进。我们知道,对于线性可分的数据一定可以找到解向量 $\\textbf a$ 使 $\\textbf a^{\\top}\\textbf y_i>0$ 对所有样本 $\\textbf y_i$( $i=1,2,\\cdots,N$)都成立。那么换句话说,一定存在一个 $\\textbf a$ 和 $\\textbf b$ ,使下式成立
$$Y\\textbf a=\\textbf b>0$$
接下来要做的就是调整MSE的准则函数,做法就是让 $\\textbf b$ 也是需要学习的参数,而不是事先指定好的,这就引出了Ho-Kashyap算法:
$$J_s(\\textbf a,\\textbf b)=||Y\\textbf a-\\textbf b||^2$$
直接优化上式将导致平凡解,所以需要给 $\\textbf b$ 加一个约束条件,要求其每个分量都大于零,进而可以解释成margin
$$\\textbf b>\\textbf 0$$
梯度如下
$$\\nabla_{\\textbf a}J_s=2Y^{\\top}(Y\\textbf a-\\textbf b)$$
$$\\nabla_{\\textbf b}J_s=-2(Y\\textbf a-\\textbf b)$$
先看 $\\textbf a$ :对于任一 $\\textbf b$ ,可令
$$\\textbf a=Y^{\\dagger}\\textbf b$$
这样的话就使得 $\\nabla_{\\textbf a}J_s=\\textbf 0$ 且 $J_s$ 关于 $\\textbf a$ 是极小的。
再看 $\\textbf b$ :由于需要满足分量全正,所以必须避免收敛到 $\\textbf b=\\textbf 0$ 。因此可以将初值的分量全部置为正值,并要求梯度必须为负,这样每个分量的值只会增加而不会减小。
这样以来,可以给出如下更新规则:
$$\\textbf a_k=Y^{\\dagger}\\textbf b_k$$
$$\\textbf b_1>\\textbf 0,\\quad\\textbf b_{k+1}=\\textbf b_k-\\eta_k\\frac12(\\nabla_{\\textbf b}J_s-|\\nabla_{\\textbf b}J_s|)$$
第二个式子的做法使得 $\\nabla_{\\textbf b}J_s$ 中原先为负的变量保持不变,而原先为正的分量变为零,从而实现了负梯度。停机条件可以设置为 $|Y\\textbf a_k-\\textbf b_k|<b_{\\min}$( $b_{\\min}$ 是一个很小的正数)。
下面看一下这个算法与众不同的地方——收敛性。记为 $\\textbf e_k=Y\\textbf a_k-\\textbf b_k$ ,那么停机条件就是 $|\\textbf e_k|<b_{\\min}$ 。当 $\\textbf e_k=Y\\textbf a_k-\\textbf b_k=\\textbf 0$ 时,由于 $\\textbf b_k$ 不再更新,因此得到一个解。
1. 对于线性可分的情况,若 $0<\\eta<1$ ,则该算法在有限步内收敛;
2. 如果 $\\textbf e_k$ 有小于零的元素,就证明数据是线性不可分的,算法终止。
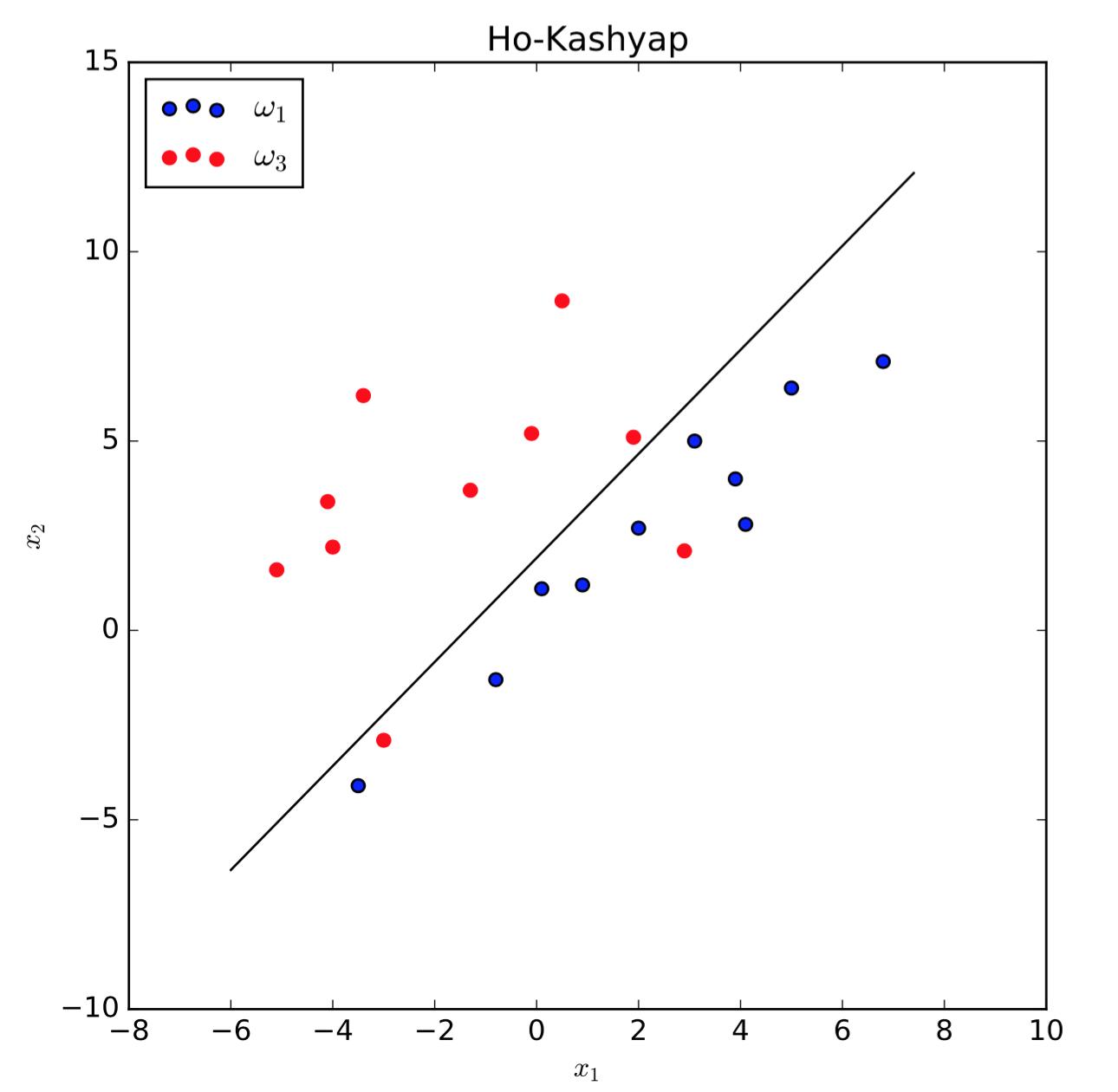
我简单实现了这个算法,在图示的toy不可分数据上运行,margin向量初始值为 $\\textbf b_1=\\textbf 1$ ,收敛准则 $b_{\\min}=0.1$ ,固定增量 $\\eta_k=0.8$ 时,迭代131步后算法判断出样本线性不可分,此时准则函数的值为 $J_s(\\textbf a,\\textbf b)=8.451$ ,并给出如下图所示的决策面:
参考资料:
[1] 《模式分类》及slides
[2] 《统计学习方法》
[3] 《神经网络与深度学习讲义》
[4] 《人工智能理论与实践》课程slides
以上是关于机器学习 —— 基础整理:线性判别函数——感知器松弛算法Ho-Kashyap算法的主要内容,如果未能解决你的问题,请参考以下文章