R数据分析之AdaBoost算法
Posted 阿蛮的杜鹃
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R数据分析之AdaBoost算法相关的知识,希望对你有一定的参考价值。
Rattle实现AdaBoost算法
Boosting算法是简单有效、易使用的建模方法。AdaBoost(自适应提升算法)通常被称作世界上现成的最好分类器。
Boosting算法使用其他的弱学习算法建立多个模型,对数据集中对结果影响较大的对象增加权重,一系列的模型被创建,然后调整那些影响分类的模型的对象权重值,实际上,模型的权重值从一个模型到另一个模型震荡。最后的模型由一系列的模型组合而成,每个模型的输出都根据相应的成绩被赋予权重值。我们注意到,如果数据失效或者弱分类器过于复杂都会导致boosting失败。
Boosting有些类似于随机森林,建立一个整体的模型,最后的模型比弱分类器任何的组合要好。区别于随机森林的,要建完一棵再建另一棵,然后基于之前的模型再细化。内容是建立完一个模型之后,任何错分类的样本都被升高权重(boosted)了。一个提升的样本本质上在数据集中会给予突出,使得单样本观测过多。目的是使下一个模型能更有效的针对此样本正确分类,如果还没有正确分,样本会再次被升高。
相比于随机森林,boosting算法更趋于多元化,任何模型的方法都可以被当作学习算法,决策树是经常使用的算法。
1.boosting概述
Boosting算法通常由一组决策树作为知识表达的基础形式,知识表达关键的地方是我们合并决策的方法。对于boosting,使用权重成绩(score),每一个模型都对应一个权重。
2.算法
作为元学习,boosting使用一些简单的学习算法组成多重模型,boosting经常依赖弱学习算法--通常任何弱分类器都可以被使用。一系列的弱分类模型可以组成一个强分类器。
一个弱分类实际上就比随机猜测的错误率稍好一点。但是组合起来将会有可观的分类效果。
算法开始基于训练数据建立一个弱的初始化模型,然后训练数据中的错分样本将会被提升(权重增加),开始时所有的样本都会被赋予一个权重值,比如权值1。权重通过一个公式被提升,所以被错分的样本的权值将会被提升(大于1)。
使用这些被提升的样本再去建立新的模型,我们可以将其作为问题样本,之后的模型将会重视这些错分样本(权值大的样本)。
我们可以通过一个简单的例子展示一下过程。假设有10个样本,每个样本有初始权重,0.1,我们建立一个决策树,有四个错分的样本(样本7,8,9,10),我们可以计算错分样本的权重之和0.4(通常我们用e表示)。这是模型准确率的测量。e被用作更新权重的测量值,变换后的值a=0.5*log((1-e)/e),错分样本新的权重值将会是ea,我们的例子当中,a=0.2027,样本7,8,9,10新的权重值将会是0.1*ea,(0.1225)
新的模型比如还有错分样本,1和8,它们现在的权重是0.1和0.1225,新的e是0.2225,新的a值为0.6275,所以样本1的权重变为0.1*ea,(0.1869)。样本8的权重为0.1225*ea(0.229).我们可以看到现在样本8的权重进一步增加了,程序继续执行直到单一树的错误率大于50%。
3.实验实例
使用rattle建立模型
在model工具栏中有Boost选项,单独的决策树建立使用rpart.建立一个模型的结果信息打印到文本视区。使用weather数据集(在数据栏data点击执行按钮可以自动加载)。
文本视区开始输出的是建立模型的一些函数:
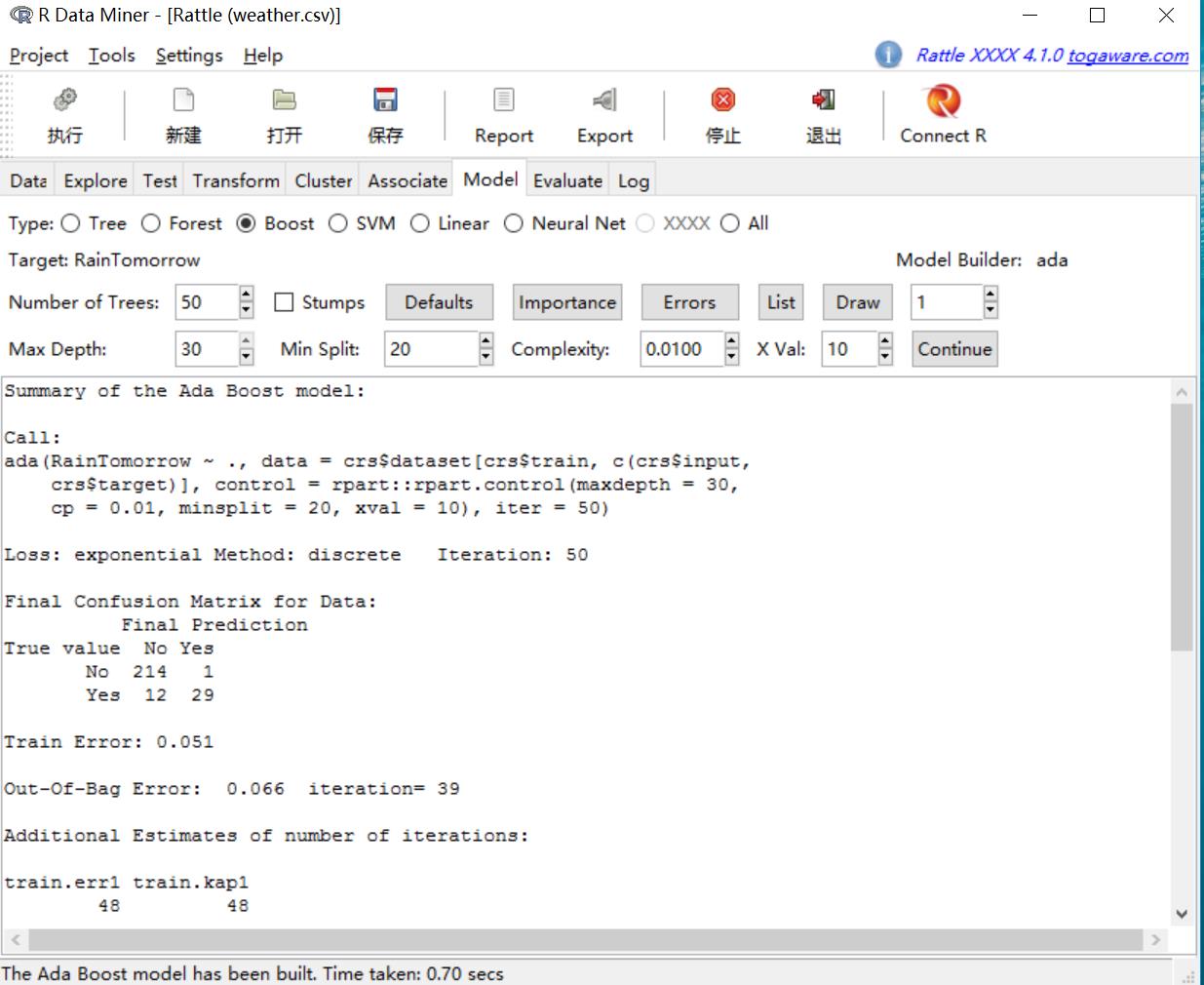
文本视区的Call基本信息中:
模型预测变量是RainTomorrow,data表示是基本数据信息,contol=参数直接传参给rpart(),iter=是建立树的数量。loss是指数损失函数,Iteration是要求建立的树的数目。
性能评估:
混淆矩阵显示了模型的性能,列出了训练数据的预测正确情况。
train error 是模型训练的错误率=1-(214+29)/(214+1+12+29) 预测正确的样本/总样本
out-of-bag 方法的错误率和相应的迭代次数。
train.err1 train.kap1 48 48 Variables actually used in tree construction: [1] "Cloud3pm" "Cloud9am" "Evaporation" "Humidity3pm" [5] "Humidity9am" "MaxTemp" "MinTemp" "Pressure3pm" [9] "Pressure9am" "Rainfall" "Sunshine" "Temp3pm" [13] "Temp9am" "WindDir3pm" "WindDir9am" "WindGustDir" [17] "WindGustSpeed" "WindSpeed3pm" "WindSpeed9am" Frequency of variables actually used: WindDir9am WindGustDir Sunshine WindDir3pm Pressure3pm 36 26 25 25 23 Cloud3pm MaxTemp MinTemp Temp9am WindSpeed3pm 12 8 6 6 6 Evaporation WindGustSpeed Cloud9am Humidity3pm Humidity9am 5 5 3 3 2 Pressure9am Rainfall Temp3pm WindSpeed9am 2 2 2 1 Time taken: 0.70 secs
Variables actually used in tree construction 是模型的决策树构造实际使用的属性。
Frequency of variables actually used是模型属性使用到的频次,从大到小列出。
最后是花费的时间0.7秒,因为数据量较小,所以花费的时间是很少的。
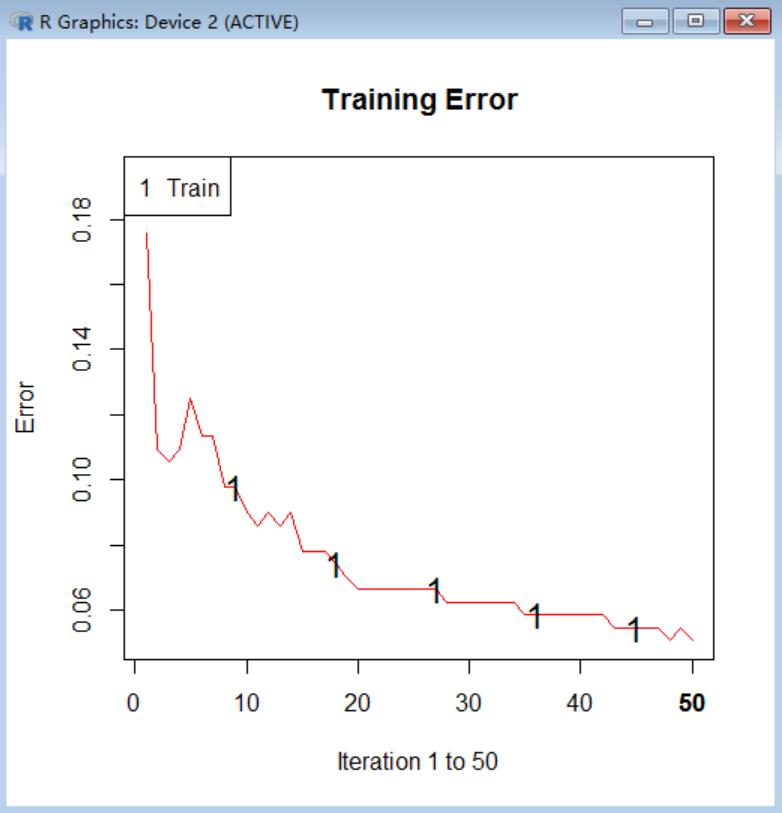
一旦模型建立完成,工具栏的error按钮将会绘制如下图所示的错误率图,随着更多的树加入模型,错误率不断降低,开始下降比较迅速,后来慢慢趋于平坦。
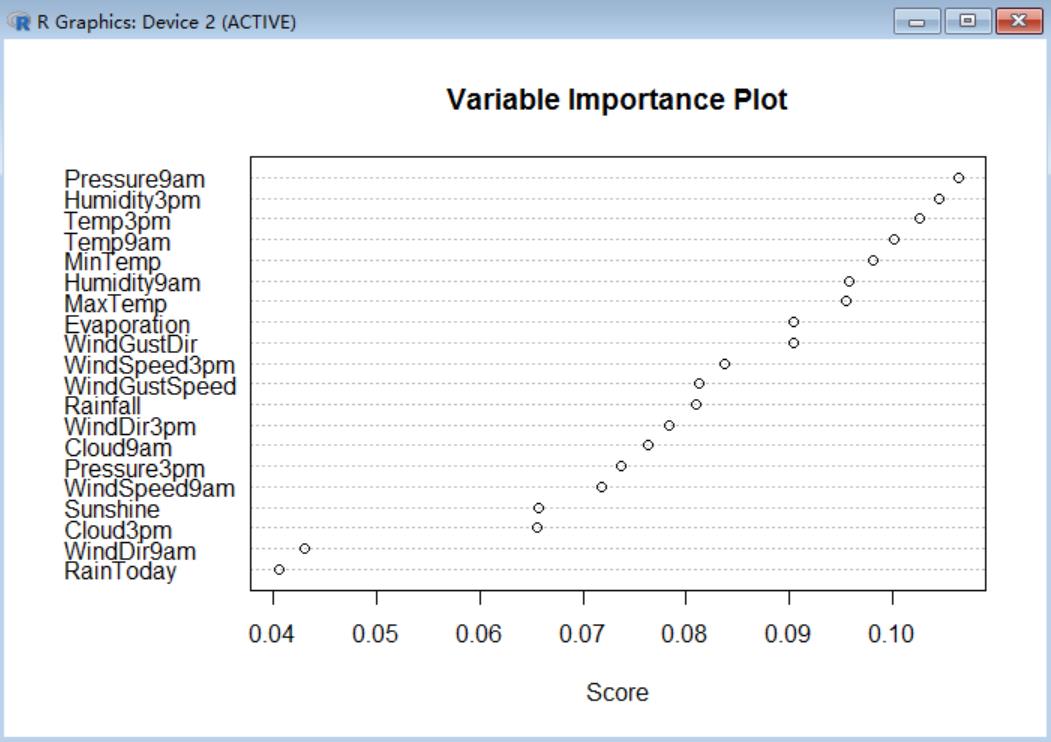
importance按钮绘制了模型重要的属性:
右下角的continue按钮可以继续增加树的数目进行训练模型。
以上是关于R数据分析之AdaBoost算法的主要内容,如果未能解决你的问题,请参考以下文章