JAVA正则表达式判断 只能包含汉字、英文、“_”和数字 ,正则该怎么写呢?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JAVA正则表达式判断 只能包含汉字、英文、“_”和数字 ,正则该怎么写呢?相关的知识,希望对你有一定的参考价值。
正则表达式:[\\\\u4e00-\\\\u9fa5]*|\\\\w*|\\\\d*|_*
代码如下:
@Test
public void test1()
//匹配正则表达式表达式
String str = "[\\\\u4e00-\\\\u9fa5]*|\\\\w*|\\\\d*|_*";
Pattern pattern = Pattern.compile(str);
//要匹配的字符串
String mStr = "还有多远_344fjdk";
System.out.println("测试的字符串:"+mStr);
Matcher m = pattern.matcher(mStr);
//如果匹配到了
if(m.find())
System.out.println("匹配内容:"+m.group());
程序运行结果:

扩展资料
匹配包括下划线的任何单词字符。类似但不等价于“[A-Za-z0-9_]”,"单词"字符使用Unicode字符集,中文的为:[\\\\u4e00-\\\\u9fa5],表示英文字母的为\\w,表示数字的为\\d,表示_的为_,而*号表示的则是0个或多个,|表示的则是或,所以把每个要匹配的用|拼接可以表示要匹配的正则表达式。
参考资料:oracle官网-Java SE API 和文档
参考技术A 正则表达式如下:String pattern = "[\u4e00-\u9fa5\\w]+";
其中:\u4e00-\u9fa5 代表中文,\\w代表英文、数字和“_",中括号代表其中的任意字符,最后的加号代表至少出现一次。本回答被提问者和网友采纳 参考技术B 匹配中文:[\u4e00-\u9fa5]
英文字母:[a-zA-Z]
数字:[0-9]
匹配中文,英文字母和数字及_:
^[\u4e00-\u9fa5_a-zA-Z0-9]+$
同时判断输入长度:
[\u4e00-\u9fa5_a-zA-Z0-9_]4,10
^[\w\u4E00-\u9FA5\uF900-\uFA2D]*$ 1、一个正则表达式,只含有汉字、数字、字母、下划线不能以下划线开头和结尾:
^(?!_)(?!.*?_$)[a-zA-Z0-9_\u4e00-\u9fa5]+$ 其中:
^ 与字符串开始的地方匹配
(?!_) 不能以_开头
(?!.*?_$) 不能以_结尾
[a-zA-Z0-9_\u4e00-\u9fa5]+ 至少一个汉字、数字、字母、下划线
$ 与字符串结束的地方匹配
放在程序里前面加@,否则需要\\进行转义 @"^(?!_)(?!.*?_$)[a-zA-Z0-9_\u4e00-\u9fa5]+$"
(或者:@"^(?!_)\w*(?<!_)$" 或者 @" ^[\u4E00-\u9FA50-9a-zA-Z_]+$ " )
2、只含有汉字、数字、字母、下划线,下划线位置不限:
^[a-zA-Z0-9_\u4e00-\u9fa5]+$
3、由数字、26个英文字母或者下划线组成的字符串
^\w+$
4、2~4个汉字
@"^[\u4E00-\u9FA5]2,4$";
5、
^[\w-]+(\.[\w-]+)*@[\w-]+(\.[\w-]+)+$
用:(Abc)+ 来分析: XYZAbcAbcAbcXYZAbcAb
XYZAbcAbcAbcXYZAbcAb6、
[^\u4E00-\u9FA50-9a-zA-Z_]
34555#5' -->34555#5'
[\u4E00-\u9FA50-9a-zA-Z_] eiieng_89_ --->eiieng_89_
_';'eiieng_88&*9_ -->_';'eiieng_88&*9_
_';'eiieng_88_&*9_ -->_';'eiieng_88_&*9_
public bool RegexName(string str)
bool flag=Regex.IsMatch(str,@"^[a-zA-Z0-9_\u4e00-\u9fa5]+$");
return flag;
Regex reg=new Regex("^[a-zA-Z_0-9]+$");
if(reg.IsMatch(s))
\\符合规则
else
\\存在非法字符
最长不得超过7个汉字,或14个字节(数字,字母和下划线)正则表达式
^[\u4e00-\u9fa5]1,7$|^[\dA-Za-z_]1,14$
参考:http://hi.baidu.com/slcands2/item/fc1f75fa412f7219a62988ac 参考技术C [a-zA-Z0-9\u4E00-\u9FA5_]+ 参考技术D ([\u4e00-\u9fa5a-zA-Z_0-9]*
php 正则表达式 只能包含字母和数字
php 正则表达式 只能包含字母和数字判断字符串是否只包含字母和数字
例如
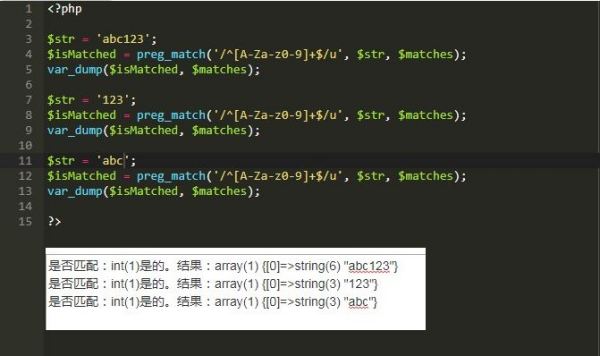
$a = "123";
$b = "acb";
$c = "abc123";
abc变量都可以通过判断
实在不会正则 多谢大佬了/抱拳
式子:/^[a-zA-Z0-9]+$/u
释义:
"/":表示正则表达式的定义,固定写法。
"^":表示开头。
"[]":表示字符组。匹配所包含的任意一个字符。如,“[ab]”匹配“plain”中的“a”。
"a-z":表示匹配小写字母a-z的字母范围。
"A-Z":表示匹配大写字母A-Z的字母范围。
"0-9":表示匹配0-9的数字范围。
"+":表示匹配次数大于等于1。
"$":匹配输入行尾。如果设置了RegExp对象Multiline属性,$也匹配“\\n”或“\\r”之前的位置。
"u":最后的u是模式修饰符,严格的说可能叫预定义常量。表示使用unicode进行匹配。
扩展资料:
其它正则表达式符号的含义:
1、"*":匹配前面的子表达式任意次。例如,zo*能匹配“z”,也能匹配“zo”以及“zoo”。*等价于0,。
2、"?":匹配前面的子表达式零次或一次。例如,“do(es)?”可以匹配“do”或“does”。?等价于0,1。
3、"n":n是一个非负整数。匹配确定的n次。例如,“o2”不能匹配“Bob”中的“o”,但是能匹配“food”中的两个o。
4、"n,":n是一个非负整数。至少匹配n次。例如,“o2,”不能匹配“Bob”中的“o”,但能匹配“foooood”中的所有o。“o1,”等价于“o+”。“o0,”则等价于“o*”。
5、"n,m":m和n均为非负整数,其中n<=m。最少匹配n次且最多匹配m次。例如,“o1,3”将匹配“fooooood”中的前三个o为一组,后三个o为一组。“o0,1”等价于“o?”。请注意在逗号和两个数之间不能有空格。
参考资料来源:百度百科-正则表达式
参考技术A式子:/^[a-zA-Z0-9]+$/u
释义:
(1)“/”:正则表达式的定义,固定的书写形式;
(2)“^”:表示开始;
(3)“[]”:表示一个字符组,匹配包含的任何字符。例如,“[ab]”匹配“plain”中的“a”;
(4)“a-z”:与小写字母a-z匹配的字母范围;
(5)“A-Z”:表示与大写字母A-Z匹配的字母范围;
(6)“0-9”:匹配范围为0-9的数字;
(7)“+”:表示匹配数为一个或多个;
(8)“$”:匹配输入行的结尾。如果设置了RegExp对象的Multiline属性,则$也匹配“\\n”或“\\r”之前的位置;
(9)“u”:最后一个u是模式修饰符,严格来说,它可以是预定义的常数。表示使用unicode进行匹配。
扩展资料:
其它正则表达式符号的含义:
(1)“*”:与上一个子表达式匹配任意次。例如,zo*匹配“z”以及“zo”和“zoo”。*等效于0,;
(2)“?”:匹配上一个子表达式零或一次。例如,“做(es)?”匹配“do”或“does”。?等效于0,1;
(3)“n”:n是一个非负整数。匹配被确定n次。例如,“o2”不能与“Bob”中的“o”匹配,但是可以与“food”中的两个o匹配;
(4)“n,”:n是一个非负整数。至少匹配n次。例如,“o2,”不能匹配“Bob”中的“o”,但是可以匹配“foooood”中的所有o。“o1,”等效于“o+”。“o0,”等效于“o*”;
(5)“ n,m”:m和n是非负整数,其中n <= m。 至少匹配n次,最多匹配m次。 例如,“ o 1,3”将匹配“ fooooood”中的前三个o作为一个组,最后三个o作为一个组。 “ o 0,1”等效于“ o?”。 请注意,逗号和两个数字之间不能有空格。
参考资料来源:
百度百科-正则表达式
参考技术B <?php$regex = '/^[ a-z0-9]$/i';
$str = 'abc123';
if(preg_match($regex, $str))
//符合条件的情况,如果处理不符合的情况,在Else里面进行处理;
echo "\\n";
?>
示例如上
我用的
if(!preg_match($regex, $str, $matches))
判断的。不可行。
我的意思是说只能是"纯字母"或"纯数字"或"字母数字组合"
抱歉,正则中少了一个加号,在中括号后面
括号中的空格去掉
本回答被提问者和网友采纳以上是关于JAVA正则表达式判断 只能包含汉字、英文、“_”和数字 ,正则该怎么写呢?的主要内容,如果未能解决你的问题,请参考以下文章