MPI中的缓冲区和非阻塞通信
Posted alliance
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MPI中的缓冲区和非阻塞通信相关的知识,希望对你有一定的参考价值。
转载自: Introduction to MPI - Part II (Youtube)
Buffering
Suppose we have
if(rank==0) MPI_Send(sendbuf,...,1,...) if(rank==1) MPI_Recv(recvbuf,...,0,...)
These are blocking communications, which means they will not return until the arguments to the functions can be safely modified by subsequent statements in the program.
Assume that process 1 is not ready to receive. Then there are 3 possibilities for process 0:
(1) stops and waits until process 1 is ready to receive
(2) copies the message at sendbuf into a system buffer (can be on process 0, process 1 or somewhere else) and returns from MPI_Send
(3) fails
As long as buffer space is available, (2) is a reasonable alternative.
An MPI implementation is permitted to copy the message to be sent into internal storage, but it is not required to do so.
What if not enough space is available?
>> In applications communicating large amounts of data, there may not be enough momory (left) in buffers.
>> Until receive starts, no place to store the send message.
>> Practically, (1) results in a serial execution.
A programmer should not assume that the system provides adequate buffering.
Now consider a program executing:
| Process 0 | Process 1 |
| MPI_Send to process 1 | MPI_Send to process 0 |
| MPI_Recv from process 1 | MPI_Recv from process 0 |
Such a program may work in many cases, but it is certain to fail for message of some size that is large enough.
There are some possible solutions:
>> Ordered send and receive - make sure each receive is matched with send in execution order across processes.
>> The aboved matched pairing can be difficult in complex applications. An alternative is to use MPI_Sendrecv. It performs both send and receive such that if no buffering is available, no deadlock will occur.
>> Buffered sends. MPI allows the programmer to provide a buffer into which data can be placed until it is delivered (or at lease left in buffer) via MPI_Bsend.
>> Nonblocking communication. Initiated, then program proceeds while the communication is ongoing, until a check that communication is completed later in the program. IMPORTANT: must make certain data not modified until communication has completed.
Safe programs
>> A program is safe if it will produce correct results even if the system provides no buffering.
>> Need safe programs for portability.
>> Most programmers expect the system to provide some buffering, hence many unsafe MPI programs are around.
>> Write safe programs using matching send with receive, MPI_Sendrecv, allocating own buffers, nonblocking operations.
Nonblocking communications
>> nonblocking communications are useful for overlapping communication with computation, and ensuring safe programs.
>> a nonblocking operation request the MPI library to perform an operation (when it can).
>> nonblocking operations do not wait for any communication events to complete.
>> nonblocking send and receive: return almost immediately
>> can safely modify a send (receive) buffer only after send (receive) is completed.
>> "wait" routines will let program know when a nonblocking operation is done.
Example - Communication between processes in ring topology
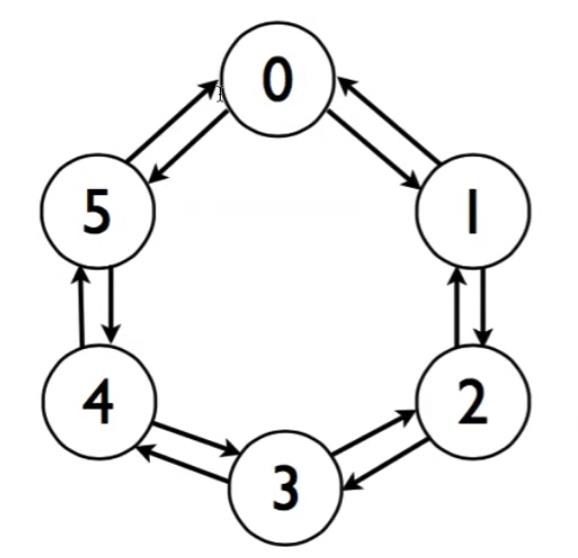
>> With blocking communications it is not possible to write a simple code to accomplish this data exchange.
>> For example, if we have MPI_Send first in all processes, program will get stuck as there will be no matching MPI_Recv to send data.
>> Nonblocking communication avoids this problem.
1 #include <stdio.h> 2 #include <stdlib.h> 3 #include "mpi.h" 4 5 int main(int argc, char *argv[]) { 6 int numtasks, rank, next, prev, buf[2], tag1=1, tag2=2; 7 8 tag1=tag2=0; 9 MPI_Request reqs[4]; 10 MPI_Status stats[4]; 11 12 MPI_Init(&argc, &argv); 13 MPI_Comm_size(MPI_COMM_WORLD, &numtasks); 14 MPI_Comm_rank(MPI_COMM_WORLD, &rank); 15 16 prev= rank-1; 17 next= rank+1; 18 if(rank == 0) prev= numtasks - 1; 19 if(rank == numtasks-1) next= 0; 20 MPI_Irecv(&buf[0], 1, MPI_INT, prev, tag1, MPI_COMM_WORLD, &reqs[0]); 21 MPI_Irecv(&buf[1], 1, MPI_INT, next, tag2, MPI_COMM_WORLD, &reqs[1]); 22 MPI_Isend(&rank, 1, MPI_INT, prev, tag2, MPI_COMM_WORLD, &reqs[2]); 23 MPI_Isend(&rank, 1, MPI_INT, next, tag1, MPI_COMM_WORLD, &reqs[3]); 24 MPI_Waitall(4, reqs, stats); 25 26 printf("Task %d communicated with tasks %d & %d\\n",rank,prev,next); 27 MPI_Finalize(); 28 return 0; 29 }
Summary for Nonblocking Communications
>> nonblocking send can be posted whether a matching receive has been posted or not.
>> send is completed when data has been copied out of send buffer.
>> nonblocking send can be matched with blocking receive and vice versa.
>> communications are initiated by sender
>> a communication will generally have lower overhead if a receive buffer is already posted when a sender initiates a communication.
以上是关于MPI中的缓冲区和非阻塞通信的主要内容,如果未能解决你的问题,请参考以下文章