Django haystack+solr搜索引擎部署的坑.
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Django haystack+solr搜索引擎部署的坑.相关的知识,希望对你有一定的参考价值。
跟着<<Django by Example>> 一路做下来,到了搭建搜索引擎的步骤
默认的思路是用
obj.objects.filter(body__icontains=‘framework‘)
然后把得到的QuerySet 返回到模板中使用
首先要确保你的java版本在 1.7或之上
使用 java -version 查看
http://archive.apache.org/dist/lucene/solr/ 然后到这个网站里下载 Solr 这里我使用的是4.10.4(不同版本之间的差异有点不一样,慎重选择.不然会被坑死)
然后进入example文件夹
java -jar start.jar //服务运行Solr;
打开你的浏览器,进入URL:http://127.0.0.1:8983/solr/ 你会看到类似这种界面
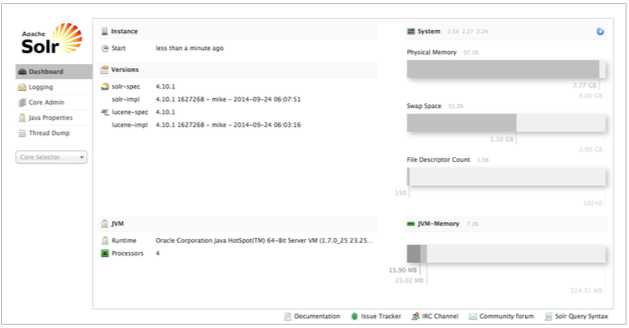
我们要为我们的应用创建一个core ,首先要创建目录树
blog$ tree
.
├── conf
│ ├── core.properties
│ ├── lang
│ │ └── stopwords_en.txt
│ ├── protwords.txt
│ ├── _rest_managed.json
│ ├── schema.xml
│ ├── solrconfig.xml
│ ├── stopwords.txt
│ └── synonyms.txt
└── data
└── index
├── segments_1
├── segments.gen
在solrconfig.xml文件中添加如下XML代码:
?xml version="1.0" encoding="utf-8" ?>
<config>
<luceneMatchVersion>LUCENE_36</luceneMatchVersion>
<requestHandler name="/select" class="solr.StandardRequestHandler" default="true" />
<requestHandler name="/update" class="solr.UpdateRequestHandler" />
<requestHandler name="/admin" class="solr.admin.AdminHandlers" />
<requestHandler name="/admin/ping" class="solr.PingRequestHandler">
<lst name="invariants">
<str name="qt">search</str>
<str name="q">*:*</str>
</lst>
</requestHandler>
</config>
这是一个最小的Solr配置。编辑schema.xml文件,加入如下XML代码:
<?xml version="1.0" ?>
<schema name="default" version="1.5">
</schema>
然后我们创建一个自己的架构
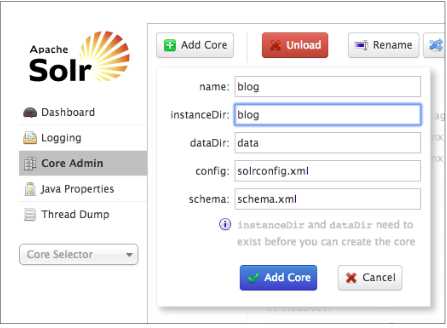
- name: blog
- instanceDir: blog
- dataDir: data
- config: solrconfig.xml
- schema: schema.xml
name字段是你想给这个core起的名字。instanceDir字段是你的core的目录。dataDir是索引数据将要存放的目录,它位于instanceDir目录下面。config字段是你的Solr XML配置文件名。schema字段是你的Solr XML 数据架构(schema)文件名。
为了在Django中使用Solr,我们还需要Haystack。使用下面的命令,通过pip渠道安装Haystack:
这里我们直接安装最新版的,书上有指定版本.跟着做坑了我一个早上,幸好各种google下来解决了问题,在此记录下,希望后面踩到坑的人也能顺利渡劫.
不过最好下之前看看自己的django版本haystack支持不支持...
附上github项目地址
https://github.com/django-haystack/django-haystack/issues
pip isntall django-haystack
//Haystack能和一些搜索引擎后台交互。要使用Solr后端,你还需要安装pysolr模块。运行如下命令安装它:
pip install pysolr
然后在setting 中添加它
INSTALLED_APPS = (
# ...
haystack‘,
)
再添加搜索引擎后端
HAYSTACK_CONNECTIONS = {
‘default‘: {
‘ENGINE‘: ‘haystack.backends.solr_backend.SolrEngine‘,
‘URL‘: ‘http://127.0.0.1:8983/solr/blog‘
},
}
在,我们必须将我们想要存储在搜索引擎中的模型进行注册。Haystack的惯例是在你的应用中创建一个search_indexes.py文件,然后在该文件中注册你的模型(models)。在你的blog应用目录下创建一个新的文件命名为search_indexes.py,添加如下代码:
from haystack import indexes
from .models import Post
class PostIndex(indexes.SearchIndex, indexes.Indexable):
text = indexes.CharField(document=True, use_template=True)
publish = indexes.DateTimeField(model_attr=‘publish‘)
def get_model(self):
return Post
def index_queryset(self, using=None):
return self.get_model().published.all()
这是一个Post模型(model)的自定义SearchIndex。通过这个索引(index),我们告诉Haystack这个模型(model)中的哪些数据必须被搜索引擎编入索引。这个索引(index)是通过继承indexes.SearchIndex和indexes.Indexable构建的。每一个SearchIndex都需要它的其中一个字段拥有document=True。按照惯例,这个字段命名为text。这个字段是一个主要的搜索字段。通过使用use_template=True,我们告诉Haystack这个字段将会被渲染成一个数据模板(template)来构建document,它会被搜索引擎编入索引(index)。publish字段是一个日期字段也会被编入索引。我们通过model_attr参数来表明这个字段对应Post模型(model)的publish字段。这个字段将用 被索引的Post对象的publish字段的内容 索引。
额外的字段,像这个为搜索提供额外的过滤器(filters),是非常有用的。get_model()方法必须返回将储存在这个索引中的documents的模型(model)。index_queryset()方法返回将会被编入索引的对象的查询集(QuerySet)。请注意,我们只包含了发布状态的帖子。
现在,在blog应用的模板(templates)目录下创建目录和文件search/indexes/blog/post_text.txt,然后添加如下代码:
{{ object.title }}
{{ object.tags.all|join:", " }}
{{ object.body }}
现在,我们已经有了一个自定义的搜索索引(index),我们需要创建合适的Solr架构(schema)。Solr的配置基于XML,所以我们必须为我们即将索引(index)的数据生成一个XML架构(schema)。非常幸运,haystack提供了一个基于我们的搜索索引(indexes),动态生成架构(schema)的方法。打开终端,运行以下命令:
python manage.py build_solr_schema

如果你看到的是这样的,那么恭喜你配置成功...
如果不是这样的,请去官网看看支持的版本和看看自己的版本对应不对应了...
以上是关于Django haystack+solr搜索引擎部署的坑.的主要内容,如果未能解决你的问题,请参考以下文章